
基于残差神经网络改进的密集人群计数方法
|
史劲霖(1994— ),男,江苏常州人,硕士。从事深度学习算法、虚拟地理环境构建研究。E-mail: sjl_njnu@163.com |
收稿日期: 2020-10-15
网络出版日期: 2021-11-25
基金资助
国家重点研发计划项目子课题(2017YFB0503503)
版权
Improved Dense Crowd Counting Method based on Residual Neural Network
Received date: 2020-10-15
Online published: 2021-11-25
Supported by
National Key Research and Development Program of China(2017YFB0503503)
Copyright
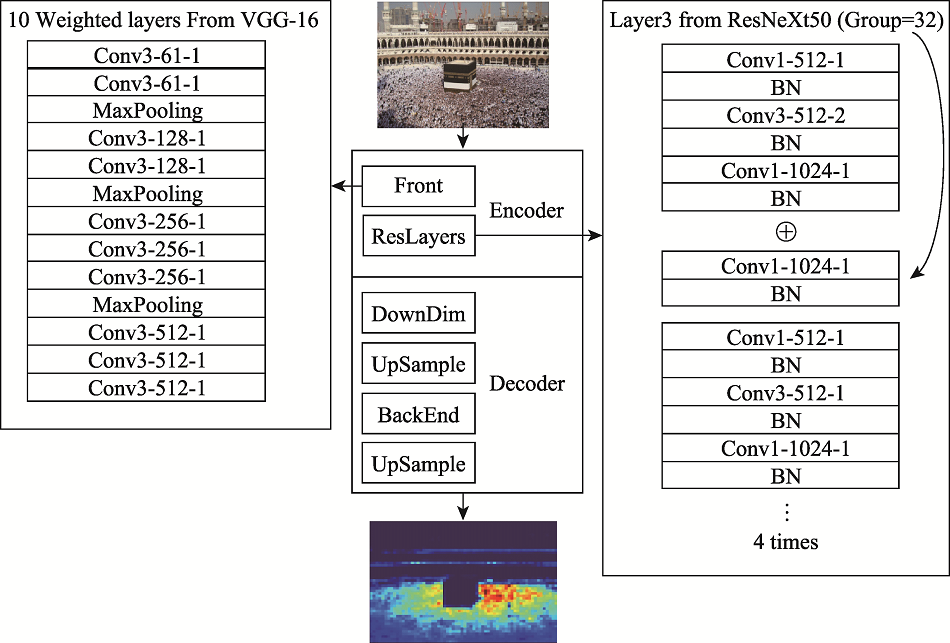
为避免密集人群踩踏事件发生,从监控图像中准确获取密集人群人数信息非常重要。针对密集人群计数难度大、人群目标小、场景尺度变化大等特点,本文提出一种新型神经网络结构VGG-ResNeXt。本网络使用VGG-16的前10层作粗粒度特征提取器,使用改进的残差神经网络作为细粒度特征提取器。利用改进的残差神经网络“多通道,共激活”的特点,使得单列式人群计数神经网络获得了多列式人群计数网络的优点(即从小目标、多尺度的密集人群图像中提取更多人群特征),同时避免了多列式人群计数网络训练难度大、结构冗余等缺点。实验结果表明本模型在UCF-CC-50数据集、ShangHaiTech B数据集和UCF-QNRF数据集中取得了最高精度,MAE指标分别优于其他同期模型7.5%、18.8%和2.4%,证明了本模型的在计数精度方面的有效性。本研究成果可以有效帮助城市管理,有效缓解公安疏导压力,保障人民生命财产安全。
史劲霖 , 周良辰 , 闾国年 , 林冰仙 . 基于残差神经网络改进的密集人群计数方法[J]. 地球信息科学学报, 2021 , 23(9) : 1537 -1547 . DOI: 10.12082/dqxxkx.2021.200604
In order to avoid crowd trampling, it is very important to accurately obtain information on the number of crowds from surveillance images. Early crowd counting studies used a feature engineering approach, in which human-designed feature extraction algorithms were used to obtain features that represented the number of people to be counted. However, the counting accuracy of such methods is not sufficient to meet the practical requirements when facing heavily occluded counting scenes with large changes in scene scale. In recent years, with the development of neural network, breakthroughs have been made in image classifications, object detections, and other fields. Neural network methods have also advanced the accuracy and robustness of dense crowd counting. In view of the difficulty of counting dense crowds, small crowd targets, and large changes in scene scale, this paper proposes a new neural network structure named: VGG-ResNeXt. The features extracted by VGG-16 are used as general-purpose visual description features. ResNet has more hidden layers, more activation functions and has more powerful feature extraction capabilities to extract more features from crowd images. Improved residual structure ResNeXt expands on the base of ResNet to further enhance feature extraction capabilities while maintaining the same computing power requirements and number of parameters. Therefore, in this paper, the first 10 layers of VGG-16 are used as the coarse-grained feature extractor, and the improved residual neural network ResNeXt is used as the fine-grained feature extractor. With the improved residual neural network feature of "multi-channel, co-activation", the single-column crowd counting neural network obtains the advantages of the multicolumn crowd counting network (i.e., extracting more features from dense crowd images with small targets and multiple scales), while avoiding the disadvantages of the multicolumn crowd counting network, such as the difficulty of training and structural redundancy. The experimental results show that our model achieves the highest accuracy in the UCF-CC-50 dataset with a very large number of people per image, the ShangHaiTech PartB dataset with a sparse crowd, and the UCF-QNRF dataset with the largest number of images currently included. Our model outperforms other models in the same period by 7.5%, 18.8%, and 2.4%, respectively, in MAE in the above three datasets, demonstrating the effectiveness of the model in improving counting accuracy in dense crowds. The results of this research can effectively help city management, relieve the pressure on public security, and protect people's lives and property.
表2 UCF-CC-50数据集中实验结果Tab. 2 Results in UCF-CC-50 dataset |
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
付倩慧, 李庆奎, 傅景楠, 等. 基于空间维度循环感知网络的密集人群计数模型[J]. 计算机应用, 2020(10-12):1-7.
[
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
/
| 〈 |
|
〉 |







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}