
基于深度学习的滑坡灾害易发性分析
|
王 毅(1979— ),男,湖北武汉人,博士,教授、博士生导师,主要从事遥感技术与应用、地学信息数据挖掘和环境影响评价等研究。E-mail: cug.yi. wang@gmail.com |
收稿日期: 2021-02-01
要求修回日期: 2021-04-14
网络出版日期: 2022-02-25
基金资助
国家自然科学基金项目(61271408)
国家自然科学基金项目(41602362)
智能机器人湖北省重点实验室(武汉工程大学)开放基金项目(HBIR202002)
版权
Landslide Susceptibility Analysis based on Deep Learning
Received date: 2021-02-01
Request revised date: 2021-04-14
Online published: 2022-02-25
Supported by
National Natural Science Foundation of China(61271408)
National Natural Science Foundation of China(41602362)
Open Fund of Hubei Key Laboratory of Intelligent Robot (Wuhan Institute of Technology)(HBIR202002)
Copyright
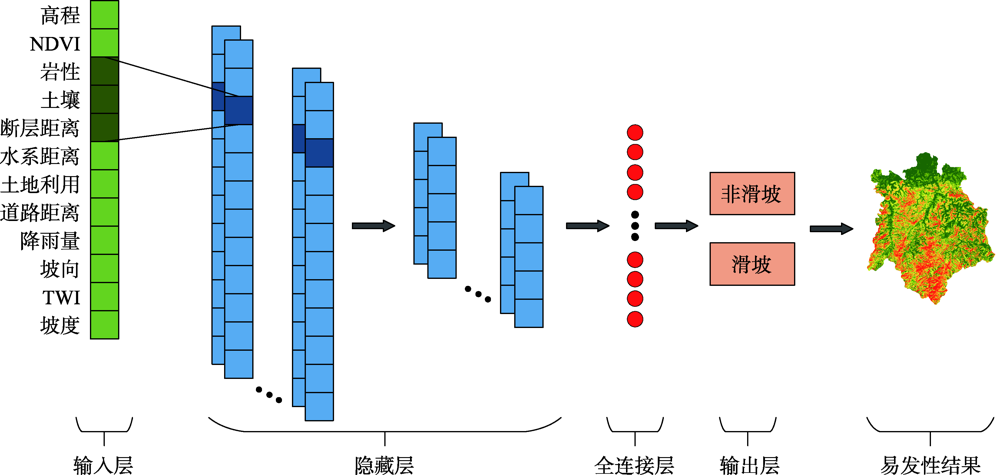
滑坡灾害成因机理复杂、影响因素众多,深度学习作为当前人工智能领域的热点,能够更好地模拟滑坡灾害的形成并准确预测潜在的斜坡。为了挖掘深度学习在滑坡易发性的应用潜能,本文构建了一维、二维和三维的滑坡数据表达形式,并提出3种基于卷积神经网络模型(Convolutional Neural Networks, CNN)的滑坡易发性分析处理框架:基于CNN分类器、基于CNN与逻辑回归的融合和基于CNN集成,最后以江西省铅山县为研究对象进行验证,结果表明:所有基于CNN的易发性模型都能够获得准确且可靠的滑坡易发性分析结果。其中,基于二维数据的CNN模型在所有单分类器中预测精度最高,为78.95%。此外,二维CNN特征提取能够显著提升逻辑回归的预测精度,其准确率提升7.9%。最后,异质集成策略能够大幅度提升基于CNN分类器的滑坡预测精度,其准确率提升4.35%~8.78%。
王毅 , 方志策 , 牛瑞卿 , 彭令 . 基于深度学习的滑坡灾害易发性分析[J]. 地球信息科学学报, 2021 , 23(12) : 2244 -2260 . DOI: 10.12082/dqxxkx.2021.210057
The formation mechanism of landslide disasters is complicated and there are many influencing factors. It is imperative to explore a low-cost and highly applicable method to manage and prevent landslide disasters. As a hot spot in the current artificial intelligence field, deep learning can better simulate the formation of landslide disasters and accurately predict potential slopes. Thus, to explore the application potential of deep learning, this paper constructs one-dimensional, two-dimensional, and three-dimensional forms of landslide data, and then introduces three Convolutional Neural Networks (CNN)-based landslide susceptibility analysis frameworks, including CNN-based classifiers, integrated models, and ensemble models. The proposed deep learning methods were applied to Yanshan County, Jiangxi Province for experiments. 16 landslide influencing factors were first selected for modelling based on the geomorphological, hydrological, and geological environment conditions of the study area. These factors include altitude, aspect, distance to faults, land use, lithology, normalized difference vegetation index, plan curvature, profile curvature, rainfall, distance to rivers, distance to roads, slope, soil, stream power index, sediment transport index, and topographic wetness index. Then, the multi-collinearity analysis and relief-F algorithm were used to analyze and screen the influencing factors. All CNN-based methods were constructed and validated based on several statistical measures of accuracy, root mean square error, mean absolute error, sensitivity, specificity, and the receiver operation characteristic curve. Finally, the susceptibility value of each pixel in the study area was predicted based on the CNN-based methods, and the entire study areas were reclassified into five susceptibility categories: very low, low, moderate, high, and very high. The factor analysis results show that the plan curvature, profile curvature, stream power index, and sediment transport index are redundant factors and should be removed from further modelling process. The model evaluation results demonstrate that all CNN-based models can obtain accurate and reliable landslide susceptibility mapping results. The two-dimensional CNN model achieved the highest prediction accuracy of 78.95% among single CNN models. Moreover, the performance of logistic regression was effectively improved by combining the two-dimensional CNN for feature extraction, with an accuracy improvement of 7.9%. Besides, the heterogeneous ensemble strategy can greatly improve landslide prediction accuracy when using CNN classifiers, with an accuracy improvement between 4.35% and 8.78%. Generally, the CNN has been proven to have huge application potential in landslide susceptibility analysis and can be implemented in other landslide-prone areas with similar geo-environmental conditions.
表1 模型评价指标Tab. 1 Model evaluation measures |
| 评价指标 | 变量含义 | 公式编号 |
|---|---|---|
| 真阳性(True Positive, TP)表示正确分类的滑坡样本个数,假阳性(False Positive, FP)表示错误分类的非滑坡样本个数,真阴性(True Negative, TN)表示正确分类的非滑坡样本个数,假阴性(False Negative, FN)表示错误分类的滑坡样本个数 | (4) | |
| (5) | ||
| (6) | ||
| n为样本个数, 和 分别代表第i个样本的观测值和预测值 | (7) | |
| (8) |
表2 滑坡评价因子多重共线性分析结果Tab. 2 Multicollinearity analysis results of landslide influencing factors |
| 滑坡评价因子 | 统计值 | |
|---|---|---|
| TOL | VIF | |
| 坡度 | 0.249 | 4.020 |
| 坡向 | 0.935 | 1.069 |
| 断层距离 | 0.865 | 1.156 |
| 土地利用 | 0.695 | 1.438 |
| 岩性 | 0.776 | 1.289 |
| NDVI | 0.700 | 1.428 |
| 平面曲率 | 0.569 | 1.756 |
| 剖面曲率 | 0.726 | 1.378 |
| 降雨量 | 0.590 | 1.695 |
| 水系距离 | 0.828 | 1.207 |
| 道路距离 | 0.852 | 1.174 |
| 坡度 | 0.310 | 3.221 |
| 土壤 | 0.351 | 2.846 |
| SPI | 0.102 | 9.802 |
| STI | 0.096 | 10.466 |
| TWI | 0.443 | 2.258 |
表3 本文CNN模型超参数设置Tab. 3 Hyperparameter settings of the proposed CNN models |
| 超参数 | 1D-CNN | 2D-CNN | 3D-CNN |
|---|---|---|---|
| 卷积核大小 | 3×1 | 3×3 | 3×3 |
| 池化核大小 | 2×1 | 2×2 | 2×2 |
| 激活函数 | Tanh | ReLU | ReLU |
| 优化器 | Adagrad | ||
| 损失函数 | 交叉熵损失函数 | ||
| 学习率 | 0.01 | 0.005 | 0.005 |
| Dropout rate | 0.2 | 0.3 | 0 |
| Epoch | 120 | 80 | 110 |
表5 融合模型和LR模型的精度评价Tab. 5 Performance of the proposed integrated models and LR |
| 模型 | ACC/% | RMSE | MAE | 敏感度 | 特异度 |
|---|---|---|---|---|---|
| 1D-CNN-LR | 75.00 | 0.5000 | 0.2500 | 0.7281 | 0.7719 |
| 2D-CNN-LR | 78.51 | 0.4636 | 0.2149 | 0.7193 | 0.8509 |
| 3D-CNN-LR | 73.25 | 0.5172 | 0.2675 | 0.7105 | 0.7544 |
| LR | 70.61 | 0.5421 | 0.2939 | 0.6930 | 0.7193 |
表6 集成模型和CNN分类器的精度评价Tab. 6 Performance of the proposed ensemble models and CNN classifiers |
| 模型 | ACC/% | RMSE | MAE | 敏感度 | 特异度 | |
|---|---|---|---|---|---|---|
| 集成模型 | Stacking | 85.09 | 0.3862 | 0.1491 | 0.8684 | 0.8333 |
| Blending | 83.88 | 0.4082 | 0.1667 | 0.8070 | 0.8596 | |
| WA | 83.30 | 0.4082 | 0.1667 | 0.7632 | 0.9035 | |
| 基分类器 | 1D-CNN | 76.31 | 0.4867 | 0.2368 | 0.7105 | 0.8158 |
| 2D-CNN | 78.95 | 0.4588 | 0.2105 | 0.7193 | 0.8596 | |
| 3D-CNN | 76.32 | 0.4866 | 0.2368 | 0.6754 | 0.8509 |
| [1] |
晏同珍, 杨顺安, 方云. 滑坡学[M]. 武汉: 中国地质大学出版社, 2000.
[
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
邱骋, 王纯祥, 江崎哲郎等.基于边坡单元的公路沿线滑坡危险度概率分析[J]. 岩土力学, 2005, 26(11):40-45.
[
|
| [6] |
兰恒星, 周成虎, 伍法权, 等. GIS支持下的降雨型滑坡危险性空间分析预测[J]. 科学通报, 2003, 48(5):507-512.
[
|
| [7] |
许嘉慧, 孙德亮, 王月, 等. 基于GIS与改进层次分析法的奉节县滑坡易发性区划[J]. 重庆师范大学学报(自然科学版), 2020, 37(2):36-44,封2.
[
|
| [8] |
楚敬龙, 杜加强, 滕彦国, 等. 基于GIS的重庆市万州区滑坡灾害危险性评价[J]. 地质通报, 2008, 27(11):1875-1881.
[
|
| [9] |
沈玲玲, 刘连友, 许冲, 等. 基于多模型的滑坡易发性评价——以甘肃岷县地震滑坡为例[J]. 工程地质学报, 2016, 24(1):19-28.
[
|
| [10] |
王进, 郭靖, 王卫东, 等. 权重线性组合与逻辑回归模型在滑坡易发性区划中的应用与比较[J]. 中南大学学报(自然科学版), 2012, 43(5):1932-1939.
[
|
| [11] |
胡燕, 李德营, 孟颂颂, 等. 基于证据权法的巴东县城滑坡灾害易发性评价[J]. 地质科技通报, 2020, 39(3):187-194.
[
|
| [12] |
|
| [13] |
|
| [14] |
武雪玲, 任福, 牛瑞卿, 等. 斜坡单元支持下的滑坡易发性评价支持向量机模型[J]. 武汉大学学报·信息科学版, 2013, 38(12):1499-1503.
[
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
黄玉蕾, 罗晓霞, 刘笃仁. MFSC系数特征局部有限权重共享CNN语音识别[J]. 控制工程, 2017, 24(7):1507-1513.
[
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
孙鑫. 机器学习中特征选问题研究[D]. 长春:吉林大学, 2013.
[
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
周志华. 机器学习[M]. 北京: 清华大学出版社, 2016.
[
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
文琼. 浅谈铅山县滑坡发育特征及形成条件[J]. 中国金属通报, 2018, 11:142-143.
[
|
| [34] |
|
| [35] |
许冲, 戴福初, 姚鑫, 等. GIS支持下基于层次分析法的汶川地震区滑坡易发性评价[J]. 岩石力学与工程学报, 2009, 28(S2):3978-3985.
[
|
| [36] |
王佳佳, 殷坤龙, 肖莉丽. 基于GIS和信息量的滑坡灾害易发性评价——以三峡库区万州区为例[J]. 岩石力学与工程学报, 2014, 33(4):797-808.
[
|
| [37] |
|
| [38] |
|
/
| 〈 |
|
〉 |














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}