
基于语义规则和词向量的台风灾害网络情感分析方法
|
林筱妍(1997— ),女,福建闽侯人,硕士生,主要从事灾害信息挖掘等研究。E-mail: 542726737@qq.com |
收稿日期: 2021-09-24
修回日期: 2021-11-29
网络出版日期: 2022-03-25
基金资助
福建省科技创新平台项目(〔2015〕75)
福建省科技创新平台项目(〔2017〕675)
版权
Typhoon Disaster Network Emotion Analysis Method based on Semantic Rules and Word Vector
Received date: 2021-09-24
Revised date: 2021-11-29
Online published: 2022-03-25
Supported by
Fujian Science and Technology Innovation Platform Project(〔2015〕75)
Fujian Science and Technology Innovation Platform Project(〔2017〕675)
Copyright
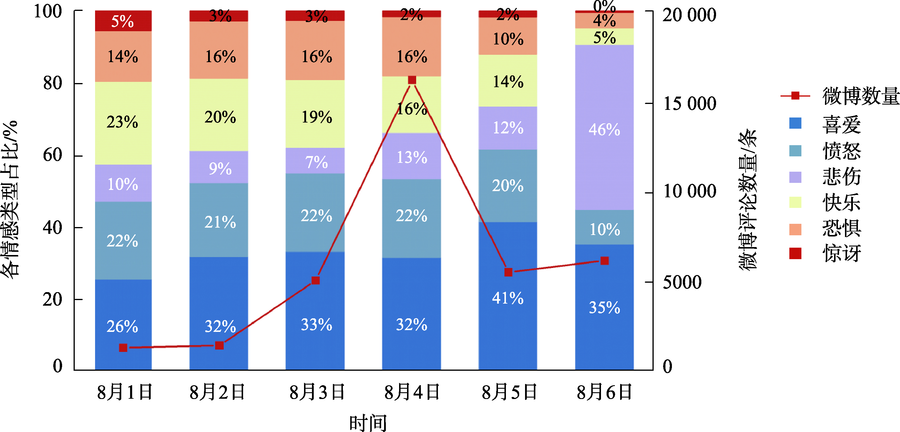
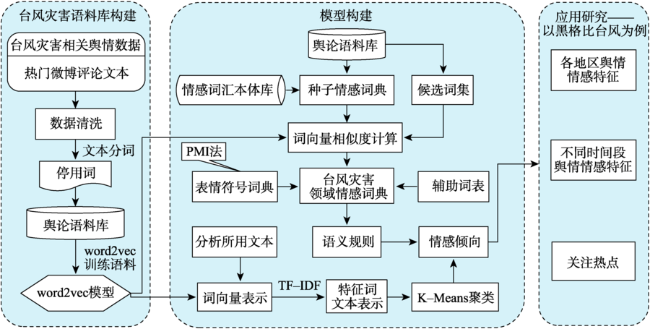
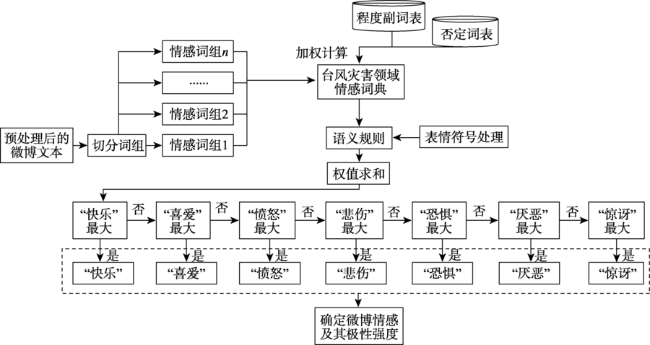
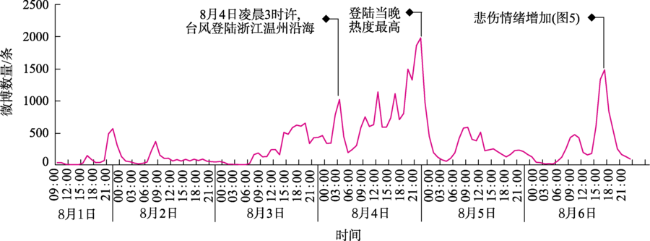
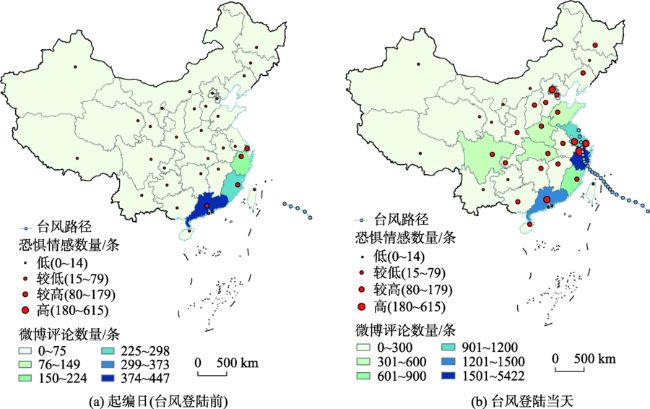
灾害期间的舆情引导有助于维护社会稳定。社交媒体是舆论传播的重要渠道,通过微博评论了解用户的网络情感及关注的话题,可以帮助相关舆情监测部门掌握公众的关注热点,从而选择适当的干预节点来应对网络舆情,并对公众情绪进行疏导,这对于应急管理具有现实意义。现有的研究大多是利用有监督的机器学习方法进行情感分类,这需要人工进行语料的标注,工作量大。本文根据微博评论文本的特点,综合考虑情感词以及表情符号等多重情感源,构建了台风灾害领域情感词典。在此基础上,提出了一种基于情感词语义规则的情感倾向计算方法,以及基于词向量的话题聚类方法。首先,采集了近年5次台风灾害期间共计40多万条微博评论文本,基于大连理工情感词汇本体库进行扩展构建了台风灾害领域情感词典,结合PMI法构建表情符号词典,根据语义规则确定情感倾向,并使用3500条评论文本验证了该方法的有效性。然后,本文基于词向量、TF-IDF与K-means的聚类方法探索灾害期间热点话题。最后,以2020年4号台风“黑格比”为例,基于台风期间的5万余条微博评论文本进行了舆情情感分析,并识别出6类与台风相关的话题。通过时空分析发现,随着时间的推移,微博评论文本的数量发生一定变化,评论数量多的地区大都集中在沿海地区和经济水平高的地区,台风登陆当天浙江省的恐惧情感达到最高。结果表明,基于语义规则和词向量的台风灾害网络情感分析方法,能在类似灾害事件发生时为政府部门掌握和引导网络舆情提供辅助。
林筱妍 , 吴升 . 基于语义规则和词向量的台风灾害网络情感分析方法[J]. 地球信息科学学报, 2022 , 24(1) : 114 -126 . DOI: 10.12082/dqxxkx.2022.210575
During natural disasters, public opinion guidance contributes to maintaining social stability. Social media is an important channel for the dissemination of public opinion. Understanding users' network emotions and topics of concern through microblog comments can help relevant public opinion monitoring departments master the hot spots of public concern, so as to select appropriate intervention nodes to deal with network public opinion and dredge public emotions, which is of practical significance for emergency management. Most of the existing researches use supervised machine learning methods for emotion classification, which requires manual labeling of corpus, and the workload is large. While the unsupervised methods are mainly based on the existing emotional dictionary, which can reflect the unstructured characteristics of the text and is easy to understand and explain. According to the characteristics of microblog comments, this paper constructs an emotional dictionary in the field of typhoon disaster by comprehensively considering multiple emotional sources such as emotional words and emoticons. Based on this, this paper proposes a method to calculate emotional tendency based on semantic rules of emotional words and a topic clustering method based on word vector. Firstly, this study collected a total of more than 400 000 comments on Sina Weibo during five times typhoon disasters in recent years and constructed the emotional dictionary in the field of typhoon disaster based DUTIR. We built the expression symbol dictionary combined with the Pointwise Mutual Information method. We determined the emotional tendencies according to the semantic rules, and we used 3500 comments to demonstrate the effectiveness of the proposed method. Secondly, based on the clustering method of word vector, TF-IDF, and K-means, we explored the hot topics during these disasters. Finally, taking typhoon Hagupit, the fourth typhoon in 2020, as an example, this paper conducted an analysis on more than 50 000 Weibo comments during the typhoon disaster, and identified 6 categories of typhoon-related topics. Through the spatial-temporal analysis, it was found that the number of comments on Weibo changed as time went on, and the areas with a large number of comments were also concentrated in coastal areas and areas with high economic level. On the day of typhoon Hagupit landing, the fear in Zhejiang province reached the highest level. The results show that the typhoon disaster network emotion analysis method based on semantic rules and word vector can provide assistance for government departments to master and guide network public opinion when similar disaster events occur.
表1 程度副词词表Tab. 1 Degree adverb list |
| 等级 | 程度副词 | 强度值 |
|---|---|---|
| 最,顶,极(most) | 最,不得了,不堪,极了,极端,极其,绝了,绝对,刻骨铭心,酷,死,滔天,痛,完全,万万,无比,要命,要死,贼,卓绝 | 2 |
| 更,越,愈,格外(very) | 太,越发,更,更加,愈加,十二分,非常,十分,不少,出奇,多多,多,多加,多么,格外,好不,何等,很,很是,十足,甚,甚至,实在,太,实在太,特,特别,尤其,着实,过于,过度,万分,真,真的,异常 | 1.5 |
| 较,还(more) | 还好,还,较,较为,进一步,那么,那样,如斯,尤甚,愈发,越发,越来越,挺,颇受,多一些 | 1 |
| 略,稍,些微(ish) | 蛮,稍,有点,有点儿,稍稍,稍微,略,些小,些许,一点,一点儿 | 0.5 |
表2 否定词词表Tab. 2 List of negative words |
| 否定词 |
|---|
| 不,非,无,别,甭,不要,不是,不必,不曾,不可,不用,并非,毫无,毫不,切勿,不够,绝不,决不,绝非,绝无,没有,从没,尚未,白白,从不,从未,何必,何曾,何尝,何须,没,没有,莫,难以,徒,徒然,枉,未,未必,未曾,未尝,未有,无从,无须,无庸,毋须,毋庸,勿 |
表3 经否定词修饰后的情感转变Tab. 3 Emotion conversion modified by negative word |
| 原始的情感类别 | 奇数个否定词修饰后 |
|---|---|
| 快乐 喜爱 愤怒 悲伤 恐惧 厌恶 惊讶 | 悲伤 厌恶 无 无 无 无 无 |
表4 表情符号词典(部分)Tab. 4 Partical Emotions |
| 情感类别 | 表情符号 |
|---|---|
| 快乐(83) 喜爱(69) 愤怒(8) 悲伤(37) 恐惧(18) 厌恶(18) 惊讶(13) | [微笑] [嘻嘻] [笑cry] [太开心] [鼓掌] [憧憬] [good] [中国赞] [耶] [哼] [小黄人不屑] [怒骂] [弱] [失望] [摊手] [下雨] [哪吒委屈] [衰] [求饶] [抓狂] [骷髅] [阴险] [费解] [黑线] [晕] [吃惊] [哆啦A梦吃惊] [awsl] |
表6 实验结果评价Tab.6 Evaluation of experimental results (%) |
| 情感类别 | 准确率P | 召回率R | 综合评价指标F1 |
|---|---|---|---|
| 快乐 | 86.00 | 87.40 | 86.69 |
| 喜爱 | 87.40 | 88.46 | 87.93 |
| 愤怒 | 89.20 | 94.09 | 91.58 |
| 悲伤 | 93.20 | 82.04 | 87.27 |
| 恐惧 | 86.80 | 88.21 | 87.50 |
| 厌恶 | 85.80 | 93.06 | 89.28 |
| 惊讶 | 93.00 | 89.60 | 91.27 |
表7 话题讨论情况Tab. 7 Topic discussion of Typhoon Hagupit |
| 话题 编号 | 话题 类型 | 话题词条(部分) | |
|---|---|---|---|
| 起编日当天话题情况 | 停编日当天话题情况 | ||
| Topic 0 | 天气与警示 | 夏天、打雷、降降温、盼来、风感、烤熟、清凉、西南风 | 小雨、炎热、暴风雨、高温、太惨、停电 |
| Topic 1 | 交通状况 | 延误、学车、停航、推迟、耽误、计划、旅行、取消 | 开车、高铁、堵车、旅行、取消、车票、公交车 |
| Topic 2 | 台风路径描述 | 登陆、威力、交界处、纬度、东南、外围、低压 | - |
| Topic 3 | 灾情讨论 | - | 工程质量、安全性、点餐、玻璃、承担责任、恶魔、辟谣 |
| Topic 4 | 祈祷及感谢 | 注意安全、灾难、平安、点赞、希望、盼望、保护 | 感激、因公殉职、节哀顺变、送别、英雄人物、缅怀 |
| Topic 5 | 抢险救灾 | - | 善后工作、电力供应、设施、防洪、隐患、公务员、负责人 |
表8 2020年8月1日—8月6日负面情感数量及占比Tab. 8 Number and proportion of negative emotions from August 1 to August 6, 2020 |
| 愤怒情感数量/条 | 愤怒情感占比/% | 悲伤情感数量/条 | 悲伤情感占比/% | ||
|---|---|---|---|---|---|
| 浙江省 | 1613 | 30.11 | 浙江省 | 1383 | 24.64 |
| 广东省 | 596 | 11.13 | 广东省 | 733 | 13.06 |
| 江苏省 | 476 | 8.89 | 北京市 | 441 | 7.86 |
| 恐惧情感数量/条 | 恐惧情感占比/% | 负面情感数量/条 | 负面情感占比/% | ||
| 浙江省 | 953 | 27.02 | 浙江省 | 3949 | 27.24 |
| 广东省 | 390 | 11.06 | 广东省 | 1719 | 11.86 |
| 上海市 | 281 | 7.97 | 上海市 | 1113 | 7.68 |
| [1] |
|
| [2] |
马哲坤, 涂艳. 基于知识图谱的网络舆情突发话题内容监测研究[J]. 情报科学, 2019, 37(2):33-39.
[
|
| [3] |
|
| [4] |
叶光辉, 曾杰妍, 胡婧岚, 等. 城市画像视角下的社会公众情感演化研究[J]. 数据分析与知识发现, 2020, 4(4):15-26.
[
|
| [5] |
徐琳宏, 林鸿飞, 潘宇, 等. 情感词汇本体的构造[J]. 情报学报, 2008, 27(2):180-185.
[
|
| [6] |
Sensing emotions in a crisis[DB/OL]. 2020. https://techxplore.com/news/2020-10-emotions-crisis.html.
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
张琛, 马祥元, 周扬, 等. 基于用户情感变化的新冠疫情舆情演变分析[J]. 地球信息科学学报, 2021, 23(2):341-350.
[
|
| [15] |
杨腾飞, 解吉波, 闫东川, 李国庆. 基于深度学习的社交媒体情感信息抽取及其在灾情分析中的应用研究[J]. 地理与地理信息科学, 2020, 36(2):62-68.
[
|
| [16] |
韩珂珂, 邢子瑶, 刘哲, 等. 重大公共卫生事件中的舆情分析方法研究—以新冠肺炎疫情为例[J]. 地球信息科学学报, 2021, 23(2):331-340.
[
|
| [17] |
|
| [18] |
|
| [19] |
单斌, 李芳. 基于LDA话题演化研究方法综述[J]. 中文信息学报, 2010, 24(6):43-49.
[
|
| [20] |
张岩, 李英冰, 郑翔. 基于微博数据的台风“山竹”舆情演化时空分析[J]. 山东大学学报(工学版), 2020, 50(5):118-126.
[
|
| [21] |
|
| [22] |
王艳东, 李昊, 王腾, 朱建奇. 基于社交媒体的突发事件应急信息挖掘与分析[J]. 武汉大学学报·信息科学版, 2016, 41(3):290-297.
[
|
| [23] |
|
| [24] |
安璐, 吴林. 融合主题与情感特征的突发事件微博舆情演化分析[J]. 图书情报工作, 2017, 61(15):120-129.
[
|
| [25] |
林江豪, 周咏梅, 阳爱民, 王伟. 结合词向量和聚类算法的新闻评论话题演进分析[J]. 计算机工程与科学, 2016, 38(11):2368-2374.
[
|
| [26] |
微博数据中心. 微博2020用户发展报告[EB/OL].http://data.weibo.com/report/, 2021-03-12.
[ Weibo Data Center. Weibo User Development Report 2020[EB/OL]. http://data.weibo.com/report, 2020-03-12.]
|
| [27] |
谌志群, 鞠婷. 基于BERT和双向LSTM的微博评论倾向性分析研究[J]. 情报理论与实践, 2020, 43(8):173-177.
[
|
| [28] |
文本分析—停用词集合[DB/OL]. 2018.https://download.csdn.net/download/cymlancy/10651346
[ Text analysis-stop words set[DB/OL]. 2018.https://download.csdn.net/download/cymlancy/10651346.]
|
| [29] |
冯跃. 面向微博的情感倾向性研究[D]. 吉林:吉林大学, 2018.
[
|
| [30] |
董振东, 董强. 知网[EB/OL].[2016-12-08]. http://www.keenage.com/zhiwang/c_zhiwang.html.
[
|
| [31] |
杜振雷. 面向微博短文本的情感分析研究[D]. 北京:北京信息科技大学, 2013.
[
|
| [32] |
|
/
| 〈 |
|
〉 |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}