
利用基于残差多注意力和ACON激活函数的神经网络提取建筑物
|
吴新辉(1995— ),男,福建莆田人,硕士生,主要从事深度学习、遥感影像的分析与应用研究。E-mail: wdlan4869@163.com |
收稿日期: 2021-09-02
修回日期: 2021-10-10
网络出版日期: 2022-06-25
基金资助
国家自然科学基金项目(41801324)
国家自然科学基金项目(41701491)
福建省自然科学基金面上项目(2019J01244)
福建省自然科学基金面上项目(2019J01791)
版权
A Neural Network based on Residual Multi-attention and ACON Activation Function for Extract Buildings
Received date: 2021-09-02
Revised date: 2021-10-10
Online published: 2022-06-25
Supported by
Youth Project of National Natural Science Foundation of China(41801324)
Youth Project of National Natural Science Foundation of China(41701491)
General project of Natural Science Foundation of Fujian Province(2019J01244)
General project of Natural Science Foundation of Fujian Province(2019J01791)
Copyright
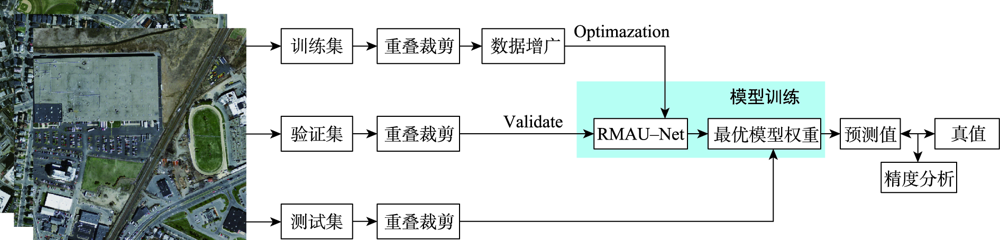
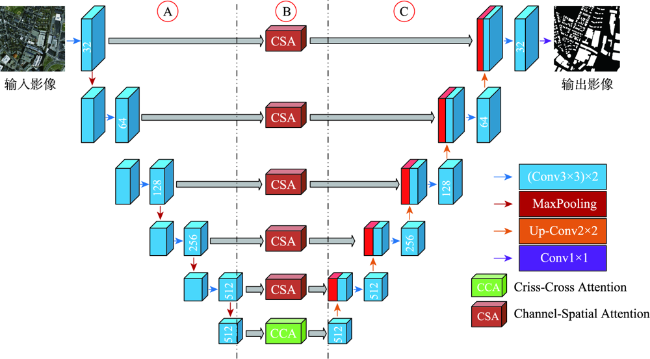
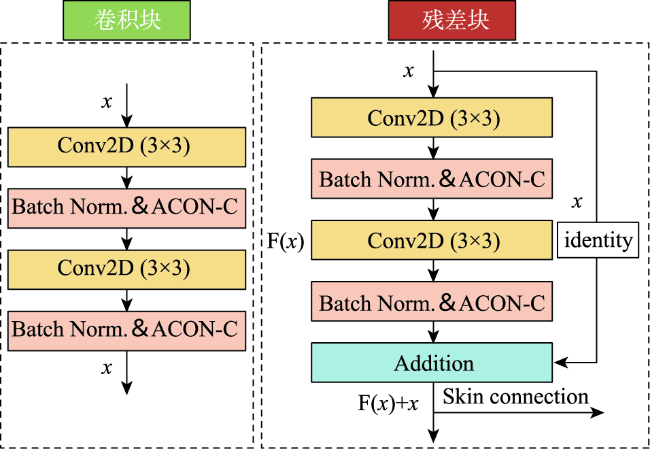
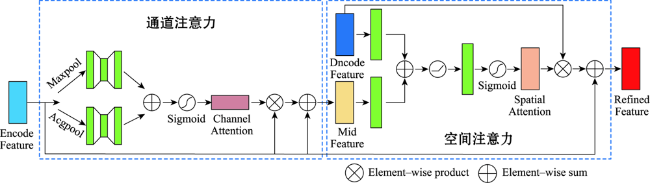
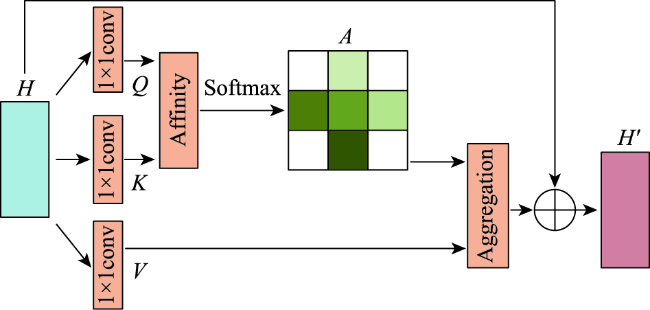
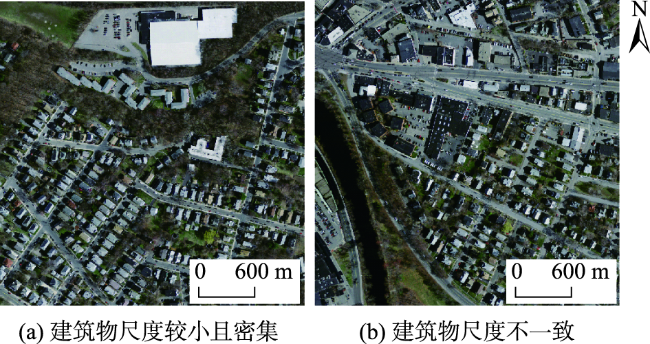
针对目前主流深度学习网络模型应用于高空间分辩率遥感影像建筑物提取存在的内部空洞、不连续以及边缘缺失与边界不规则等问题,本文在U-Net模型结构的基础上通过设计新的激活函数(ACON)、集成残差以及通道-空间与十字注意力模块,提出RMAU-Net模型。该模型中的ACON激活函数允许每个神经元自适应地激活或不激活,有利于提高模型的泛化能力和传输性能;残差模块用于拓宽网络深度并降低训练和学习的难度,获取深层次语义特征信息;通道-空间注意力模块用于增强编码段与解码段信息的关联、抑制无关背景区域的影响,提高模型的灵敏度;十字注意力模块聚合交叉路径上所有像素的上下文信息,通过循环操作捕获全局上下文信息,提高像素间的全局相关性。以Massachusetts数据集为样本的建筑物提取实验表明,在所有参与比对的7个模型中,本文提出的RMAU-Net模型交并比与F1分数2项指标最优、查准率和查全率两项指标接近最优, RMA-UNet总体效果优于同类模型。通过逐步添加每个模块来进一步验证各模块的有效性以及本文所提方法的可靠性。
吴新辉 , 毛政元 , 翁谦 , 施文灶 . 利用基于残差多注意力和ACON激活函数的神经网络提取建筑物[J]. 地球信息科学学报, 2022 , 24(4) : 792 -801 . DOI: 10.12082/dqxxkx.2022.210530
Current mainstream deep learning network models have many problems such as inner cavity, discontinuity, missed periphery, and irregular boundaries when applied to building extraction from high spatial resolution remote sensing images. This paper proposed the RMAU-Net model by designing a new activation function (Activate Customized or Not, ACON) and integrating residuals block with channel-space and criss-cross attention module based on the U-Net model structure. The ACON activation function in the model allows each neuron to be activated or not activated adaptively, which helps improve the generalization ability and transmission performance of the model. The residual module is used to broaden the depth of the network, reduce the difficulty in training and learning, and obtain deep semantic feature information. The channel-spatial attention module is used to enhance the correlation between encoding and decoding information, suppress the influence of irrelevant background region, and improve the sensitivity of the model. The cross attention module aggregates the context information of all pixels on the cross path and captures the global context information by circular operation to improve the global correlation between pixels. The building extraction experiment using the Massachusetts dataset as samples shows that among all the 7 comparison models, the proposed RMA-UNET model is optimal in terms of intersection of union and F1-score, as well as indexes of precision and recall, and the overall performance of RMAU-Net is better than similar models. Each module is added step by step to further verify the validity of each module and the reliability of the proposed method.
表1 实验环境Tab. 1 Experimental environment |
| 项目 | 参数 |
|---|---|
| 中央处理器 | Intel(R) Core(TM) i5-10600KF CPU @4.10 GHz |
| 显存 | 8 G |
| 硬盘 | 2 T |
| 显卡 | NVIDIA GeForce RTX 3070 |
| 操作系统 | Window10 |
| 开发语言 | Python |
| 深度学习框架 | PyTorch |
图8 Massachusetts数据集同类模型的结果图对比Fig. 8 Comparison of results from similar models in the Massachusetts dataset |
表2 RMAU-Net与同类模型在Massachusetts数据集上的训练和测试时间Table 2 The training time and testing time of RMAU-NET and similar models on Massachusetts dataset |
| 模型 | U-Net | Res-Unet | Attention-Unet | Res-Attention-Unet | RMAU-Net |
|---|---|---|---|---|---|
| 训练时间/h | 30.6 | 32.6 | 38.3 | 40.1 | 39.2 |
| 测试时间/s | 5.3 | 5.6 | 6.8 | 7.3 | 6.9 |
表3 在Massachusetts数据集上RMAU-Net和同类模型提取结果的定量评价Tab. 3 Quantitative evaluation on results of RMAU-Net and similar models for the Massachusetts dataset (%) |
| 模型 | IOU | F1-score | Precision | Recall |
|---|---|---|---|---|
| U-Net | 70.69 | 82.48 | 85.99 | 79.61 |
| Res-Unet | 70.51 | 82.06 | 85.98 | 79.04 |
| Attention-Unet | 71.34 | 83.11 | 87.09 | 79.69 |
| Res-Attention-Unet | 71.41 | 83.12 | 87.63 | 79.37 |
| SA-Net[5] | 73.45 | 84.69 | 86.78 | 82.70 |
| RMAU-Net | 73.68 | 84.75 | 87.10 | 82.69 |
表4 ACON激活函数实验评估结果及对比Tab. 4 The evaluation results and comparisonof ACON activation function experiment (%) |
| 模型 | IOU | F1-score | Precision | Recall |
|---|---|---|---|---|
| U-Net+ReLu | 70.69 | 82.48 | 85.99 | 79.61 |
| U-Net+ACON-C | 71.33 | 83.09 | 86.65 | 80.09 |
| RMAU-Net+ReLu | 73.16 | 84.40 | 86.89 | 82.21 |
| RMAU-Net+ACON-C | 73.68 | 84.75 | 87.10 | 82.69 |
表5 RB、CSA、CCA模块实验评估结果及对比Tab. 5 The experiments evaluation results and comparison of RB, CSA and CCA module (%) |
| 模型 | IOU | F1-score | Precision | Recall |
|---|---|---|---|---|
| U-Net(基准) | 71.33 | 83.09 | 86.65 | 80.09 |
| U-Net(基准)+RB | 71.61 | 83.33 | 85.78 | 81.22 |
| U-Net(基准)+RB+CSA | 72.76 | 84.11 | 86.73 | 81.78 |
| U-Net(基准)+RB+CSA+CCA | 73.68 | 84.75 | 87.10 | 82.69 |
| [1] |
施文灶, 毛政元. 基于图割与阴影邻接关系的高分辨率遥感影像建筑物提取方法[J]. 电子学报, 2016,44(12):2849-2854.
[
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
冯凡, 王双亭, 张津, 等. 基于尺度自适应全卷积网络的遥感影像建筑物提取[J]. 激光与光电子学进展, 2021:1-20.
[
|
| [6] |
|
| [7] |
|
| [8] |
崔卫红, 熊宝玉, 张丽瑶. 多尺度全卷积神经网络建筑物提取[J]. 测绘学报, 2019,48(5):597-608.
[
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
季顺平, 魏世清. 遥感影像建筑物提取的卷积神经元网络与开源数据集方法[J]. 测绘学报, 2019,48(4):448-459.
[
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
陈凯强, 高鑫, 闫梦龙, 等. 基于编解码网络的航空影像像素级建筑物提取[J]. 遥感学报, 2020,24(9):1134-1142.
[
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
/
| 〈 |
|
〉 |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}