
基于LDA和优化蚁群的OD流向时空语义聚类算法
|
张 晗(1994— ),男,福建永安人,硕士生,主要从事时空数据挖掘研究。E-mail: zh_curry@163.com |
收稿日期: 2021-09-06
要求修回日期: 2021-11-10
网络出版日期: 2022-07-25
基金资助
国家自然科学基金项目(41471333)
中央引导地方科技发展专项(2021H0036)
版权
A Spatio-temporal Semantic Clustering Algorithm for OD Flow Direction based on LDA and Ant Colony Optimization
Received date: 2021-09-06
Request revised date: 2021-11-10
Online published: 2022-07-25
Supported by
National Natural Science Foundation of China(41471333)
Central Guided Local Development of Science and Technology Project(2021H0036)
Copyright
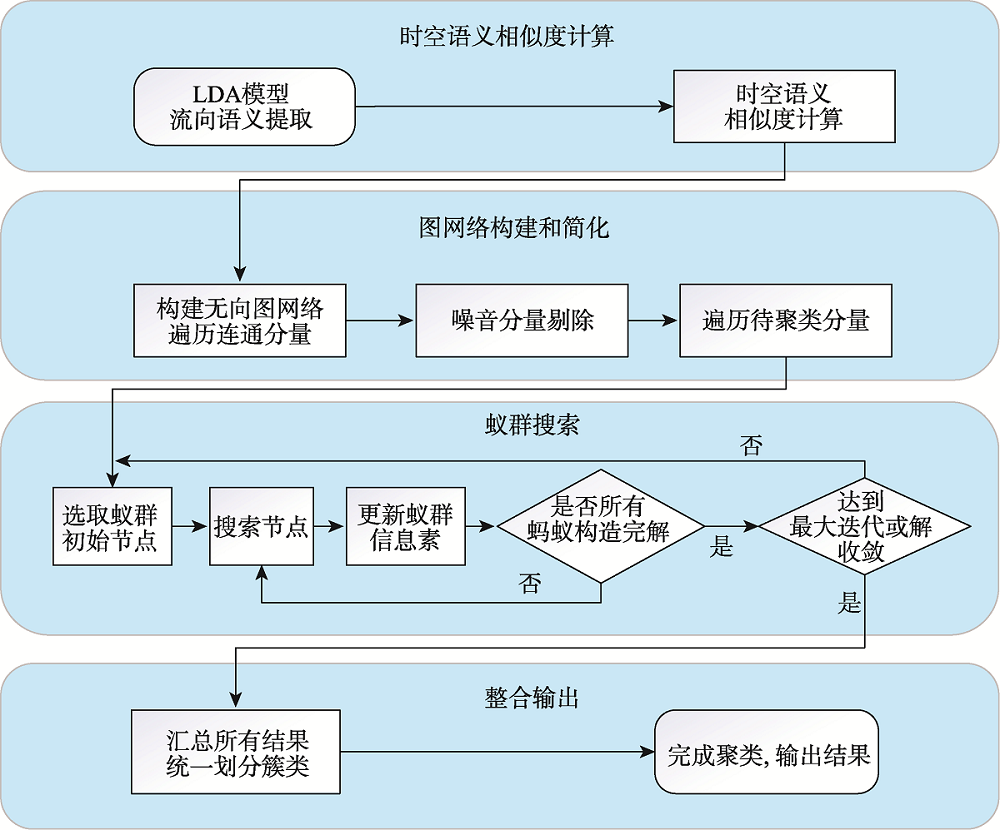
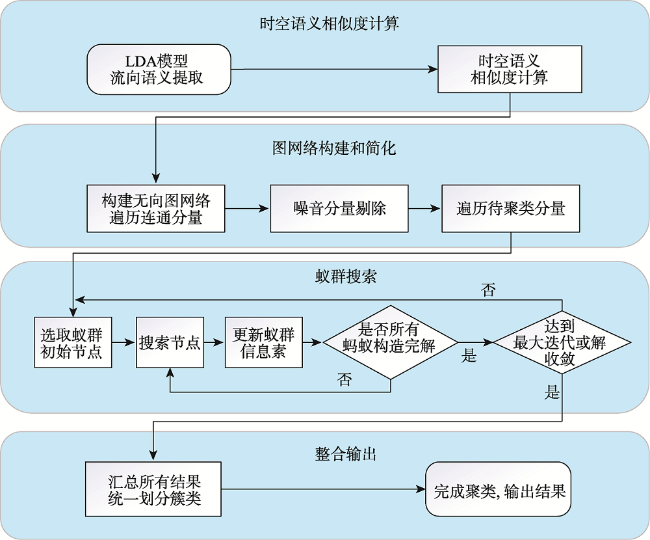
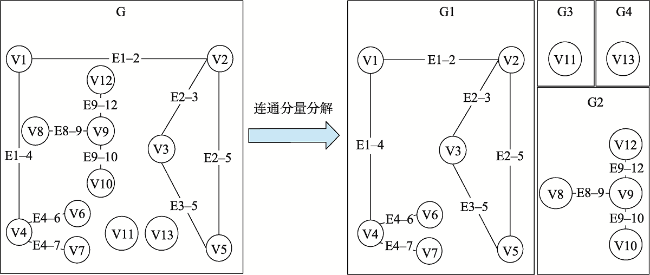
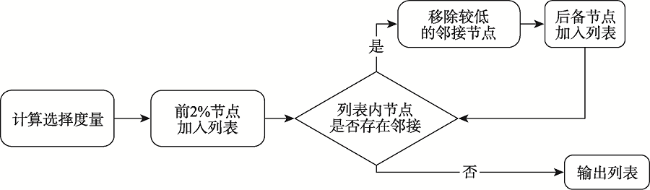
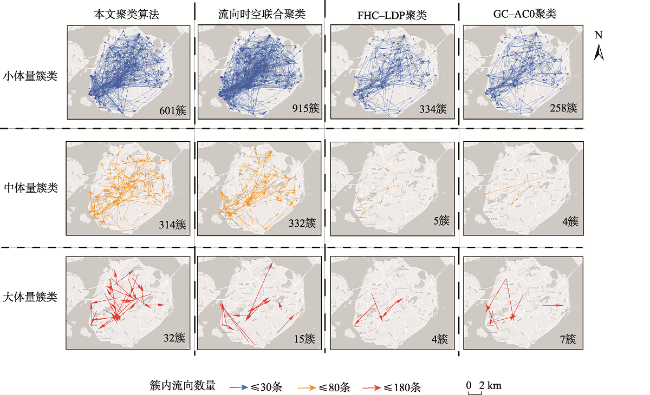
针对OD流向聚类中语义信息考虑不足和流向语义提取困难的问题,本文提出了一种基于隐含狄利克雷分布模型(Latent Dirichlet Allocation,LDA)和优化蚁群的OD流向语义聚类算法。算法首先以流向终点的POI类别为词汇构建流向文档,采用LDA主题模型提取流向语义,量化OD流向间的语义相似度,融合时间、空间和语义相似度构建流向时空语义相似度;接着以流向为节点,以流向时空语义相似度为边构建流向图,利用高斯函数映射以及图连通分量,剔除不相似的流向,实现数据精简;之后借鉴了密度峰值聚类算法思想,利用节点的介数中心性优化蚁群初始位置选取;最后基于多路切图准则(Multiway Normalized Cut, MNCUT)强化蚁群搜索的目的性,优化蚁群搜索的聚类效果,实现OD流向的时空语义聚类。以厦门市出租车公开数据集与厦门市高德地图POI数据为例进行分析与验证,结果表明本文基于LDA模型的语义提取方法可以有效提取流向的语义信息,构建有效的流向相似度度量;基于高斯函数和图连通分量特性的映射策略可以有效剔除了流向数据中的噪音,有效节省无向图构建的计算开支,大约节省了88.5%~88.8%的运行时间;基于介数中心性和多路切图准则优化的蚁群搜索聚类算法,可以有效进行流向语义聚类。相比已有方法本文方法能够更好地衡量流向间的语义相似程度,可实现按主题进行聚类划分,划分更加精细,更方便有效地进行流向语义的相关分析。
张晗 , 邬群勇 . 基于LDA和优化蚁群的OD流向时空语义聚类算法[J]. 地球信息科学学报, 2022 , 24(5) : 837 -850 . DOI: 10.12082/dqxxkx.2022.210535
In order to solve the problem that semantic information is not fully considered in existing OD flow clustering algorithms and it is difficult to mine OD flow semantic information, this paper proposes an OD flow clustering algorithm based on the Latent Dirichlet Allocation (LDA) model and ant colony optimization algorithm. Firstly, the LDA Topic model is used to extract OD flows' semantics, and the JS divergence (Jensen-Shannon divergence) is used to quantify the semantic similarity between OD flows. We also propose a spatiotemporal semantic similarity calculation method that is constructed by integrating temporal, spatial, and semantic similarity, which provides data basis for flow clustering. Then, the graph network data structure is constructed according to the spatiotemporal semantic similarity, and the Gaussian function mapping and the connected component of the graph are used to simplify the data and eliminate the noise data. Based on the idea of CFDP algorithm (Clustering by fast search and find of density peaks algorithm), the intermediate centrality of nodes is used to optimize the selection strategy of the initial position of ant colony. Finally, the Multi-path Normalized Cut (MNCUT) graph criterion is used to strengthen the purpose of ant colony search, optimize the clustering effect of ant colony search, and realize the spatiotemporal semantic clustering for OD flow direction. Taking Xiamen taxi open data set and Xiamen map POI data as examples, the proposed method is verified. The experimental results show that: (1) The proposed method can effectively extract the semantic information of flow direction and measure the similarity degree between flow directions more comprehensively compared with the existing methods; (2) The Gaussian function mapping strategy and graph connected component feature are adopted to effectively eliminate the noise in the flow direction data, which saves the computational cost of undirected graph construction effectively by 88.5%~88.8% of the running time; (3) Compared with the existing algorithms, the clustering division of the proposed algorithm is more precise, and the correlation analysis of flow semantics can be carried out conveniently and effectively.
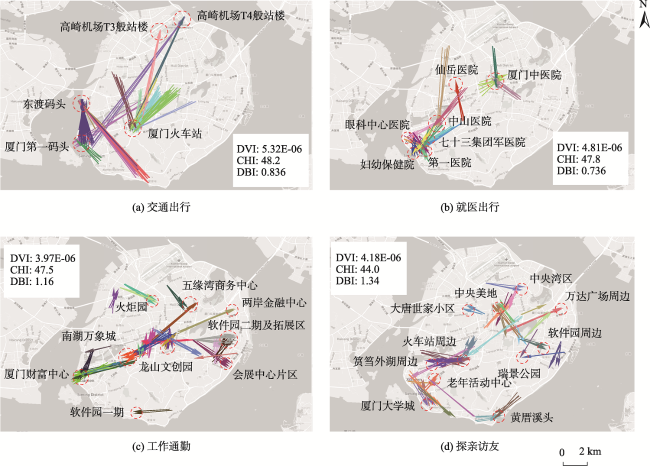
表1 LDA模型“主题-词汇”概率分布表及其语义解释Tab. 1 The topic-word probability distribution table of LDA model and semantic interpretation |
| 主题编号 | 主题词汇分布 | 语义解释 |
|---|---|---|
| Topic0 | 0.549×"汽车服务" + 0.103×"公司企业" + 0.087×"购物" + 0.062×"美食" + 0.054×"生活服务" | 租车购车 |
| Topic1 | 0.390×"旅游景点" + 0.084×"美食" + 0.065×"购物" + 0.059×"生活服务" + 0.058×"公司企业" | 游玩出行 |
| Topic2 | 0.331×"教育培训" + 0.302×"生活服务" + 0.087×"美食" + 0.081×"交通设施" + 0.076×"购物" | 教育培训 |
| Topic3 | 0.550×"交通设施" + 0.333×"教育培训" + 0.098×"美食" + 0.017×"购物" + 0.002×"生活服务" | 交通出行 |
| Topic4 | 0.568×"公司企业" + 0.074×"购物" + 0.067×"金融" + 0.063×"美食" + 0.050×"生活服务" | 工作通勤 |
| Topic5 | 0.715×"房地产" + 0.091×"交通设施" + 0.075×"美食" + 0.045×"生活服务" + 0.044×"购物" | 探亲访友 |
| Topic6 | 0.430×"购物" + 0.255×"美食" + 0.072×"生活服务" + 0.055×"公司企业" + 0.041×"休闲娱乐" | 购物出行 |
| Topic7 | 0.336×"休闲娱乐" + 0.168×"美食" + 0.164×"酒店" + 0.068×"交通设施" + 0.057×"公司企业" | 休闲娱乐 |
| Topic8 | 0.356×"金融" + 0.123×"美食" + 0.098×"购物" + 0.089×"公司企业" + 0.087×"生活服务" | 金融理财 |
| Topic9 | 0.319×"医疗" + 0.127×"购物" + 0.119×"美食" + 0.077×"金融" + 0.061×"生活服务" | 就医出行 |
|
| 算法1 基于LDA和优化蚁群的OD流向时空语义聚类算法 |
|---|
| 输入:OD流向数据F←{ },连通分量划分阈值r,信息素重 要性参数 ,启发函数重要性参数 输出:OD流向类簇C={ },噪音集合N={ } |
| function LDA_MNCUT_ANT_CLUSTER(G,r,α,β) Step1: //无向图构图阶段,无向图G(V,E),其中V是点集合V ←{ },E是边集合E ←{ } for i in F do for j in F do creat add to G Step2://连通分量划分阶段,划分连通分量Graphs{ },并简化噪音获得待聚类集合C_Graphs{ } |
| Graphs=divide(G,r) |
| for in Graphs do C_Graphs=classify( ) Step3: //对待聚类连通分量进行聚类,计算出初始位置inital,K只蚂蚁搜索求解,最后整合聚类结果 for in C_Graphs do while Not_End_Condition do //迭代搜索,直到满足停止条件 K,inital=Initialize( ) for k in K do res=Search(k,inital,α,β) Res=Merge(res,C) |
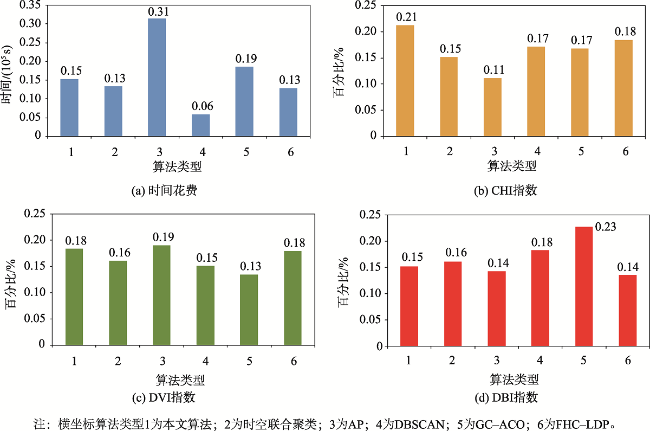
表2 LDA、中心性、MNCUT模块实验评估结果Tab. 2 Experimental evaluation results of LDA, centrality and MNCUT modules |
| 序号 | 基准 | LDA | 中心性 | MNCUT | DVI | CHI | DBI | 时间/s |
|---|---|---|---|---|---|---|---|---|
| 1 | √ | 0.9186E-22 | 0.13486 | 2.6478 | 1747 | |||
| 2 | √ | √ | √ | √ | 1.1598E-22 | 0.18349 | 1.7699 | 1535 |
| 3 | √ | √ | √ | 1.1468E-22 | 0.18615 | 1.7817 | 1517 | |
| 4 | √ | √ | √ | 0.9345E-22 | 0.15876 | 1.9683 | 1964 | |
| 5 | √ | √ | √ | 1.1198E-22 | 0.17145 | 2.1784 | 1418 |
| [1] |
杨延杰, 尹丹, 刘紫玟, 等. 基于大数据的流空间研究进展[J]. 地理科学进展, 2020, 39(8):1397-1411.
[
|
| [2] |
李涛王, 姣娥, 黄洁. 基于腾讯迁徙数据的中国城市群国庆长假城际出行模式与网络特征[J]. 地球信息科学学报, 2020, 22(6):1240-1253.
[
|
| [3] |
张政, 陈艳艳, 梁天闻. 基于网约车数据的城市区域出行时空特征识别与预测研究[J]. 交通运输系统工程与信息, 2020, 20(3):89-94.
[
|
| [4] |
杨格格, 宋辞, 裴韬, 等. 北京对外交通枢纽乘客OD时空分布特征[J]. 地球信息科学学报, 2016, 18(10):1374-1383.
[
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
项秋亮, 邬群勇, 张良盼. 一种逐级合并OD流向时空联合聚类算法[J]. 地球信息科学学报, 2020, 22(6):1394-1405.
[
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
陈世莉, 陶海燕, 李旭亮, 等. 基于潜在语义信息的城市功能区识别——广州市浮动车GPS时空数据挖掘[J]. 地理学报, 2016, 71(3):471-483.
[
|
| [16] |
冷彪, 赵文远. 基于客流数据的区域出行特征聚类[J]. 计算机研究与发展, 2014, 51(12):2653-2662.
[
|
| [17] |
叶小莺, 万梅, 唐蓉, 等. 基于图聚类与蚁群算法的社交网络聚类算法[J]. 计算机应用研究, 2020, 37(6):1670-1674,1687.
[
|
| [18] |
白璐, 赵鑫, 孔钰婷, 等. 谱聚类算法研究综述[J]. 计算机工程与应用, 2021, 57(14):15-26.
[
|
| [19] |
张文会, 苏永民, 戴静, 等. 居住区共享停车泊位分配模型[J]. 交通运输系统工程与信息, 2019, 19(1):89-96.
[
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
王婷婷, 韩满, 王宇. LDA模型的优化及其主题数量选择研究——以科技文献为例[J]. 数据分析与知识发现, 2018, 2(1):29-40.
[
|
| [24] |
|
| [25] |
|
| [26] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}