
基于MAEU-CNN的高分辨率遥感影像建筑物提取
|
张 华(1979— ),男,安徽合肥人,博士,副教授,主要从事遥感数据智能解译及GIS理论与应用研究。E-mail: zhhua_79@163.com |
收稿日期: 2021-11-15
修回日期: 2021-12-01
网络出版日期: 2022-08-25
基金资助
国家自然科学基金项目(41971400)
国家自然科学基金项目(41974039)
Building Extraction from High Spatial Resolution Imagery based on MAEU-CNN
Received date: 2021-11-15
Revised date: 2021-12-01
Online published: 2022-08-25
Supported by
National Natural Science Foundation of China(41971400)
National Natural Science Foundation of China(41974039)
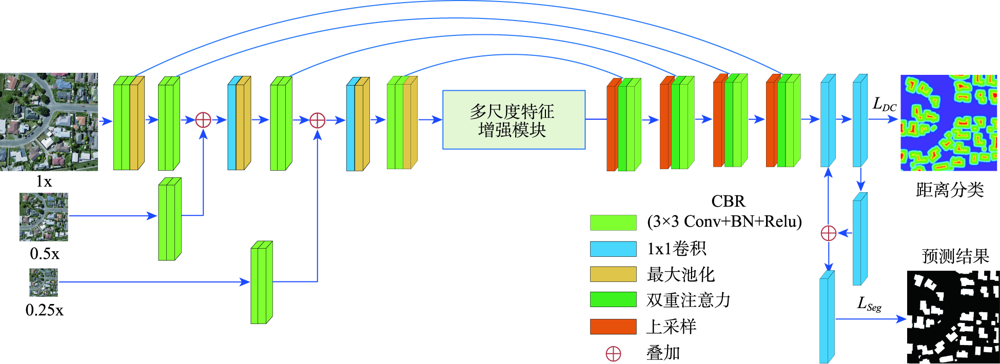
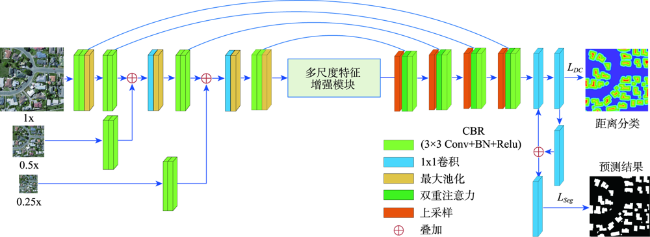
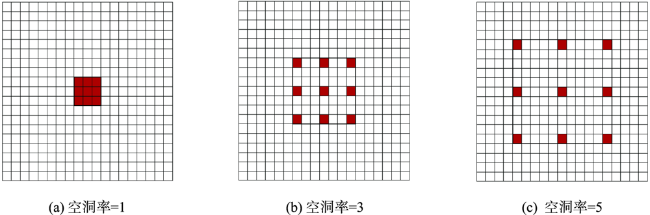
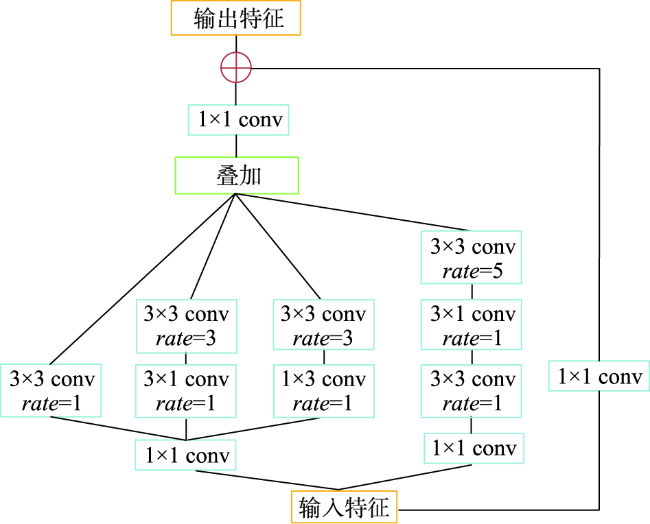
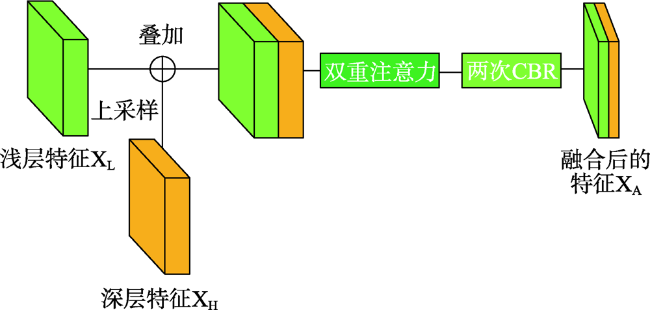
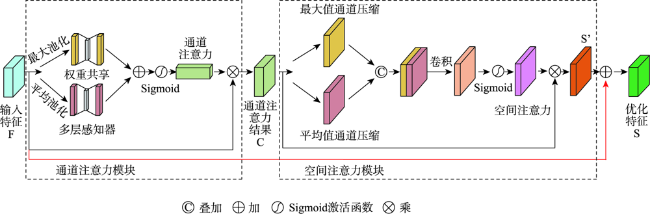
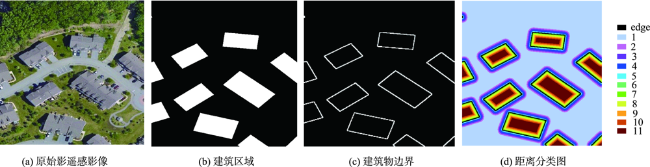
从高空间分辨率图像(HSRI)中提取建筑物信息在遥感应用领域具有重要意义。然而,由于遥感影像中的建筑物尺度变化大、背景复杂和外观变化大等因素,从HSRI中自动提取建筑物仍然是一项具有挑战性的任务。特别是从影像中同时提取小型建筑物群和具有精确边界的大型建筑物时,难度更大。为解决这些问题,本文提出了一种端到端的编码器-解码器神经网络模型,用于从HSRI中自动提取建筑物。所设计的网络称为MAEU-CNN(Multiscale Feature Enhanced U-shaped CNN with Attention Block and Edge Constraint)。首先,在设计的网络编码部分加入多尺度特征融合(MFF)模块,使网络能够更好地聚集多个尺度特征。然后,在编码器和解码器部分之间添加了多尺度特征增强模块(MFEF),以获得不同尺寸的感受野,用于获取更多的多尺度上下文信息。在跳跃连接部分引入双重注意机制,自适应地选择具有代表性的特征图用于提取建筑物。最后,为了进一步解决MAEU-CNN中由于池化及卷积操作导致的分割结果边界模糊的问题,引入多任务学习机制,将建筑物的边界几何信息融入网络中以优化提取的建筑物边界,最终获得精确边界的建筑物信息。MAEU-CNN在ISPRS Vaihingen语义标记数据集和WHU航空影像数据集2种不同尺度建筑物数据集上进行了试验分析,在ISPRS Vaihingen语义标记数据集上,MAEU-CNN在精度、F1分数和IoU指标中获得了最高精度,分别达到了93.4%、93.62%和88.01%;在WHU航空影像数据集上,召回率、F1分数和IoU指标中也获得了最高精度,分别达到了95.45%、95.58%和91.54%。结果表明,本文所提出的MAEU-CNN从遥感图像中提取建筑物信息精度较高,并且对于不同尺度具有较强的鲁棒性。
张华 , 郑祥成 , 郑南山 , 史文中 . 基于MAEU-CNN的高分辨率遥感影像建筑物提取[J]. 地球信息科学学报, 2022 , 24(6) : 1189 -1203 . DOI: 10.12082/dqxxkx.2022.210727
Extraction of buildings from High Spatial Resolution Imagery (HSRI) plays an important role in remotely sensed imagery application. However, automatically extracting buildings from HSRI is still a challenging task due to factors such as large-scale variation of buildings, background complexity, and variation in appearance, etc. Especially, it is difficult in extracting both crowded small buildings and large buildings with accurate boundaries. To address these challenges, this paper presents an end-to-end encoder-decoder model to automatically extract buildings from HSRI. The designed network is called multiscale feature enhanced U-Shaped CNN with attention block and edge constraint (MAEU-CNN). Firstly, a Multiscale Feature Fusion (MFF) module is adopted in the encoder part of the network, which enables the network to aggregate features from multiple scales. Then, a Multi-scale Feature Enhancement module (MFEF) is added between the encoder and decoder parts to obtain multiscale receptive fields for obtaining multiscale context information. Thirdly, a dual attention mechanism is introduced to adaptively select representative feature maps for extraction of buildings instead of direct skipping connections. Lastly, in order to further solve the problem of segmentation result with poor boundaries aroused by the pooling operations in the MAEU-CNN, the geometric information of building boundary is introduced into the proposed MAEU-CNN by multi-task learning using the distance class map to produce fine-grained segmentations with precise boundaries. The performance of MAEU-CNN is examined through two different data sets at different building scales. The results show that MAEU-CNN obtains the greatest accuracy in each data set. The Precision, F1, and IoU is 93.4%, 93.62%, and 88.01%, respectively using the ISPRS Vaihingen semantic labeling contest data set. The Recall, F1, and IoU reach 95.45%, 95.58%, and 91.54%, respectively, using the WHU aerial image data set. Experimental results demonstrate that our proposed MAEU-CNN can achieve high accuracy for the extraction of building from remotely sensed imagery and show great robustness at different scales.
表1 超参数设置Tab. 1 Hyper parameter configuration |
| 参数 | WHU数据集 | Vaihingen数据集 |
|---|---|---|
| 优化器 | Adam | Adam |
| 损失函数 | 标准交叉熵损失函数 | 标准交叉熵损失函数 |
| 训练次数 | 100 | 300 |
| 批次大小 | 5 | 5 |
| 初始学习率 | 0.0001 | 0.0001 |
| 学习率衰减 | 0.5倍/50次 | 0.5倍/50次 |
表2 ISPRS Vaihingen数据集上各种方法精度对比Tab. 2 Quantitative comparison of precisions of different methods on the ISPRS Vaihingen data set |
| 方法 | 精度/% | 召回率/% | F1分数/% | IoU/% |
|---|---|---|---|---|
| UNet | 93.12 | 91.31 | 92.21 | 85.54 |
| UNet++ | 92.12 | 93.83 | 92.97 | 86.86 |
| PSPNet | 93.25 | 92.98 | 93.12 | 87.13 |
| HRNetV2 | 93.07 | 94.07 | 93.56 | 87.91 |
| MAEU-CNN | 93.44 | 93.81 | 93.62 | 88.01 |
表3 WHU航空影像数据集上各种方法精度对比Tab. 3 Quantitative comparison of precisions of different methods on the WHU aerial image data set (%) |
| 方法 | 精度 | 召回率 | F1分数 | IoU |
|---|---|---|---|---|
| UNet | 92.72 | 94.71 | 93.70 | 88.15 |
| UNet++ | 95.23 | 94.64 | 94.94 | 90.36 |
| PSPNet | 94.94 | 94.23 | 94.58 | 89.72 |
| HRNetV2 | 96.53 | 94.01 | 95.26 | 90.94 |
| MAEU-CNN | 95.73 | 95.45 | 95.58 | 91.54 |
表4 MAEU-CNN在ISPRS Vaihingen数据集上的消融实验Tab. 4 Ablation experiment of MAEU-CNN with the ISPRS Vaihingen data set (%) |
| 方法 | 精度 | 召回率 | F1分数 | IoU |
|---|---|---|---|---|
| UNet | 93.12 | 91.31 | 92.21 | 85.54 |
| UNet + Attention | 92.42 | 93.76 | 93.08 | 87.06 |
| UNet + Attention + MF | 93.15 | 93.43 | 93.29 | 87.42 |
| UNet + Attention + MF+ MFEM | 92.80 | 94.29 | 93.53 | 87.85 |
| UNet + Attention+ MF + MFEM + ECM(MAEU-CNN) | 93.44 | 93.81 | 93.62 | 88.01 |
表5 MAEU-CNN在WHU航空影像数据集上的消融实验Tab. 5 Ablation experiment of MAEU-CNN with the WHU aerial image data set (%) |
| 方法 | 精度 | 召回率 | F1分数 | IoU |
|---|---|---|---|---|
| UNet | 92.71 | 94.71 | 93.70 | 88.15 |
| UNet + Attention | 94.30 | 94.92 | 94.61 | 89.77 |
| UNet + Attention + MF | 95.55 | 94.78 | 95.18 | 90.78 |
| UNet + Attention + MF+ MFEM | 95.80 | 95.25 | 95.52 | 91.42 |
| UNet + Attention + MF + MFEM + ECM(MAEU-CNN) | 95.73 | 95.45 | 95.58 | 91.54 |
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
徐佳伟, 刘伟, 单浩宇, 等. 基于PRCUnet的高分遥感影像建筑物提取[J]. 地球信息科学学报, 2021, 23(10):1838-1849.
[
|
| [18] |
张玉鑫, 颜青松, 邓非. 高分辨率遥感影像建筑物提取多路径RSU网络法[J]. 测绘学报, 2021, 50(10):1-10.
[
|
| [19] |
|
| [20] |
唐璎, 刘正军, 杨懿, 等. 基于特征增强和ELU的神经网络建筑物提取研究[J]. 地球信息科学学报, 2021, 23(4):692-709.
[
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
Vaihingen 2D Semantic Labeling-ISPRS. [Online]. Available:http://www2.isprs.org/commissions/comm3/wg4/semantic-labeling.html
|
/
| 〈 |
|
〉 |




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}