
顾及POI人口吸引力异质性的城市人口空间化方法
|
桂志鹏(1982— ),男,宁夏吴忠人,博士,副教授,主要从事高性能地理计算与时空大数据分析相关研究。E-mail: zhipeng.gui@whu.edu.cn |
收稿日期: 2022-07-01
修回日期: 2022-06-07
网络出版日期: 2022-12-25
基金资助
国家自然科学基金项目(41971349)
国家自然科学基金项目(42090010)
国家自然科学基金项目(U20A2091)
国家重点研发计划项目(2021YFE0117000)
武汉大学知卓时空智能研究基金项目(ZZJJ202201)
Urban Population Spatialization by Considering the Heterogeneity on Local Resident Attraction Force of POIs
Received date: 2022-07-01
Revised date: 2022-06-07
Online published: 2022-12-25
Supported by
National Natural Science Foundation of China(41971349)
National Natural Science Foundation of China(42090010)
National Natural Science Foundation of China(U20A2091)
National Key Research and Development Program of China(2021YFE0117000)
Zhizhuo Research Fund on Spatial-Temporal Artificial Intelligence(ZZJJ202201)
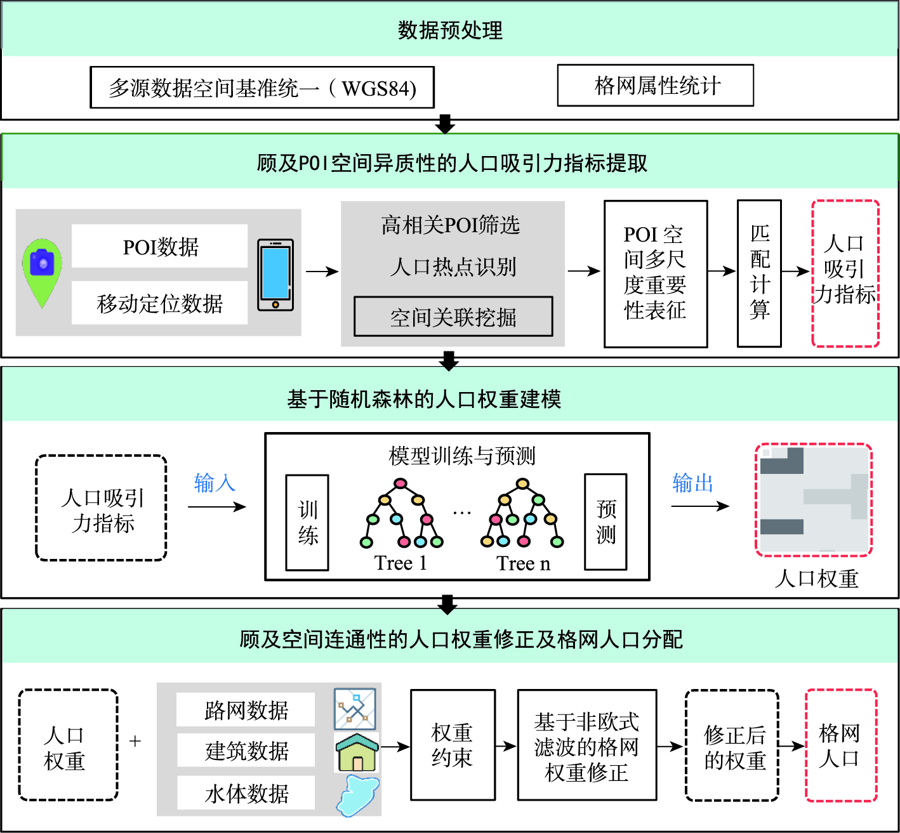
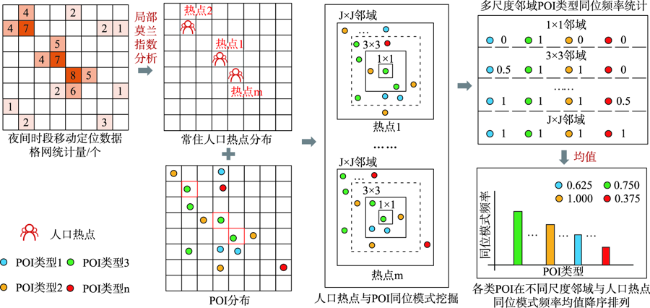
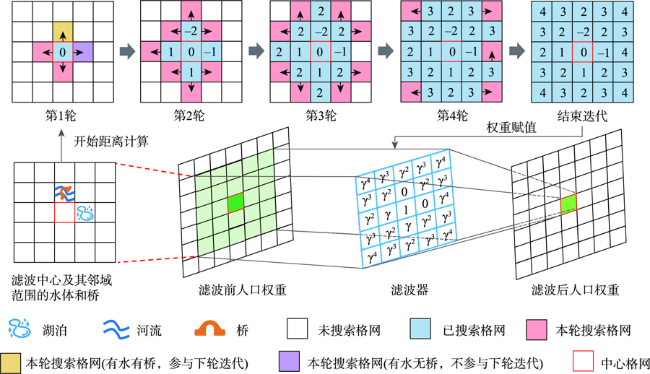
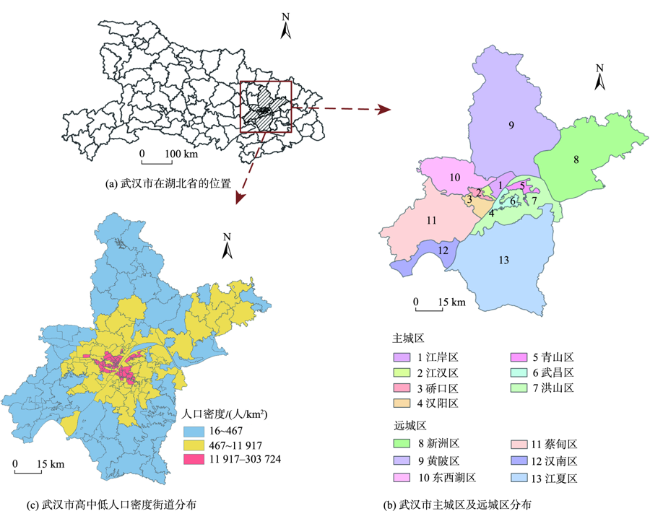
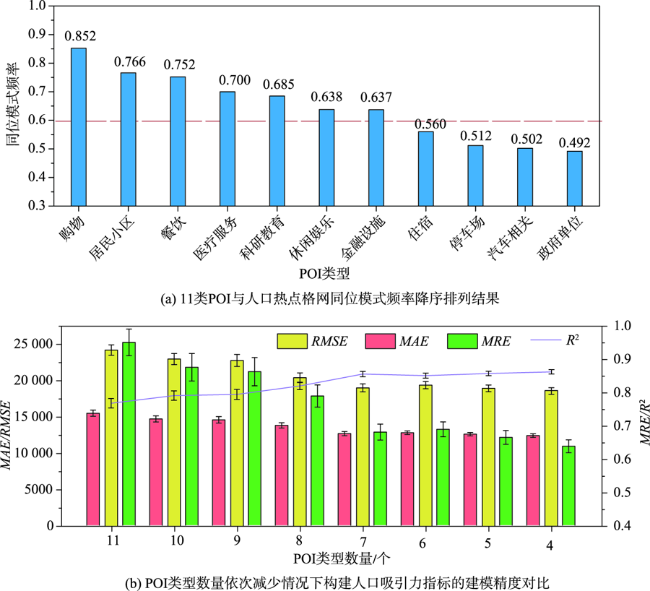
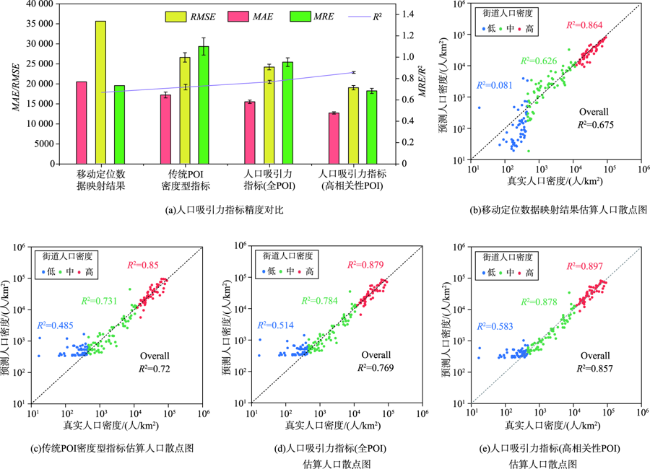
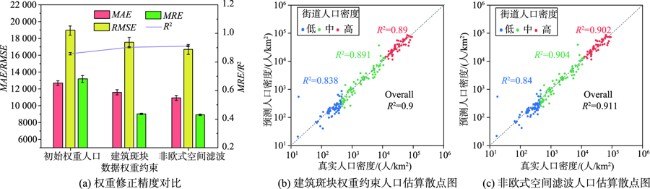
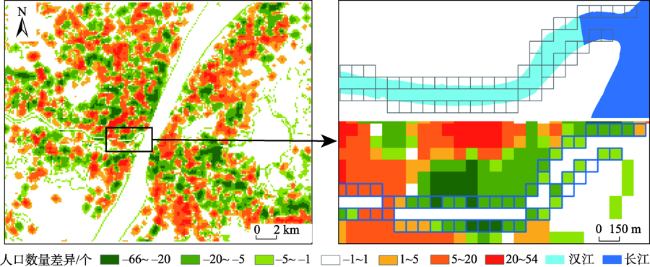
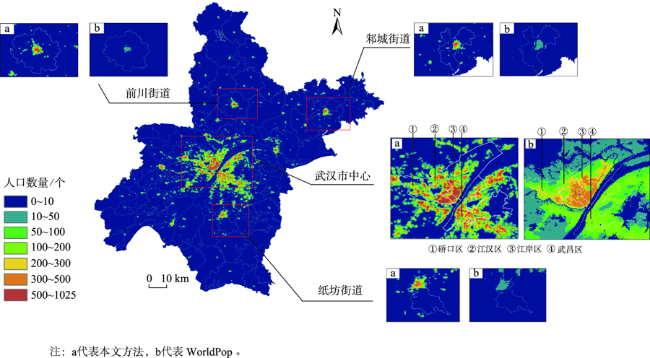
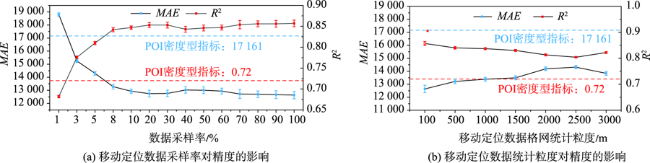
人口空间化是提升人口统计数据空间分辨率的常用手段,现有研究多基于统计建模思想建立多源数据与统计人口的数学模型以预测格网人口。兴趣点(Point of Interest, POI)作为精细人口估算的重要数据源,通常以数量/密度型指标形式参与回归建模,该方式忽略了类型相同但个体规模不同的POI与人口之间数量关系的差异,特征均质化处理造成POI语义细节的损失,导致中心城区人口低估与远城区高估。为此,本文基于随机森林模型,提出一种顾及POI人口吸引力异质性的城市人口空间化方法。该方法在表征POI空间多尺度重要性的基础上,引入移动定位数据构建人口吸引力指标;并基于非欧式滤 波修正格网人口权重,建模人口空间自相关,刻画水体等障碍物对局部空间连通性的影响。本文以武汉市为研究区域开展100 m格网验证,通过与POI密度型回归模型、公开人口数据集的对比和消融实验,展现了人口吸引力指标与权重修正的有效性。结果表明,本文方法平均绝对误差为WorldPop、GPW及对比模型的1/4~2/3,在精细人口空间化场景具有精度优势。此外,本文还讨论了移动定位数据采样率及格网粒度对建模精度的影响。
桂志鹏 , 梅宇翱 , 吴华意 , 李锐 . 顾及POI人口吸引力异质性的城市人口空间化方法[J]. 地球信息科学学报, 2022 , 24(10) : 1883 -1897 . DOI: 10.12082/dqxxkx.2022.220384
Population spatialization is a common method to refine the spatial resolution of census data. Existing studies are mostly based on the idea of statistical modeling to establish the association between ancillary data and population at the administrative-unit-level, and then transfer it to predict the gridded population. As an important data input for fine-grained population estimation, Point of Interests (POIs) are usually in the form of quantity or density indexes for regression modeling, which ignores the heterogeneity in the association between population and POIs with same type but different sizes. Such modeling methods cause the loss of semantic details of POIs, in turn leading to the population underestimation in main urban areas and overestimation in suburban areas. To tackle this problem, this paper proposes an urban population spatialization method based on random forest model by considering the heterogeneity of population attraction of POIs. More specifically, on the basis of establishing a multi-scale representation of the spatial importance of POIs, this method constructs population attraction indexes by integrating mobile positioning data. Meanwhile, the spatial autocorrelation of population is modeled based on non-Euclidean spatial filter for weight correction, which considers the influence of obstacles such as water body on local spatial connectivity. We select Wuhan city as the study area to conduct population spatialization experiment at 100 m spatial resolution. Through the comparison with traditional density-based model, popular gridded datasets, and the ablation experiments, the results verify the effectiveness of population attraction indexes and weight correction. The mean absolute error of our method is about 1/4-2/3 of the WorldPop, GPW, and the comparison model (i.e., Ye's model), demonstrating the advantages of our method in fine-grained population spatialization. In addition, the influences of the sampling rate and size of grid of mobile positioning data on the modeling accuracy are also discussed.
表1 研究数据概况Tab. 1 Overview of study data |
| 数据 | 年份 | 来源 | 描述 | |
|---|---|---|---|---|
| 建模数据 | POI数据 | 2017 | 高德地图 (https://www.amap.com/) | 使用11类POI:休闲娱乐、住宿、停车场、医疗服务、居民小区、政府单位、汽车相关、科研教育、购物、金融服务、餐饮 |
| 移动定位数据 | 2018 | 维智科技Wayz.AI | 数据量为266 460条(每条对应一个定位点记录),时间段为23:00—次日3:00 | |
| 建筑斑块数据 | 2015 | 武汉市地理国情普查 | 作为初始人口权重约束的依据;小于200 m2的斑块未被采集 | |
| 水体数据 | 2015 | 清华大学开放数据集 (http://data.ess.tsinghua.edu.cn) | 作为本文实验中的障碍物;30 m分辨率的栅格数据 | |
| 路网数据 | 2015 | 武汉市测绘研究院 | 利用路网中的桥作为水体的连通设施 | |
| 武汉市行政区划 | 2015 | 武汉市测绘研究院 | 包括武汉市区县、街道矢量轮廓及常住人口数量信息 | |
| 对比数据 | WorldPop | 2015 | WorldPop官网 (http://www.worldpop.org.uk/) | 分辨率为100 m |
| GPW | 2015 | NASA社会经济数据和应用中心 (http://srtm.csi.cgiar.org) | 分辨率为30弧秒(赤道处约为1 km) | |
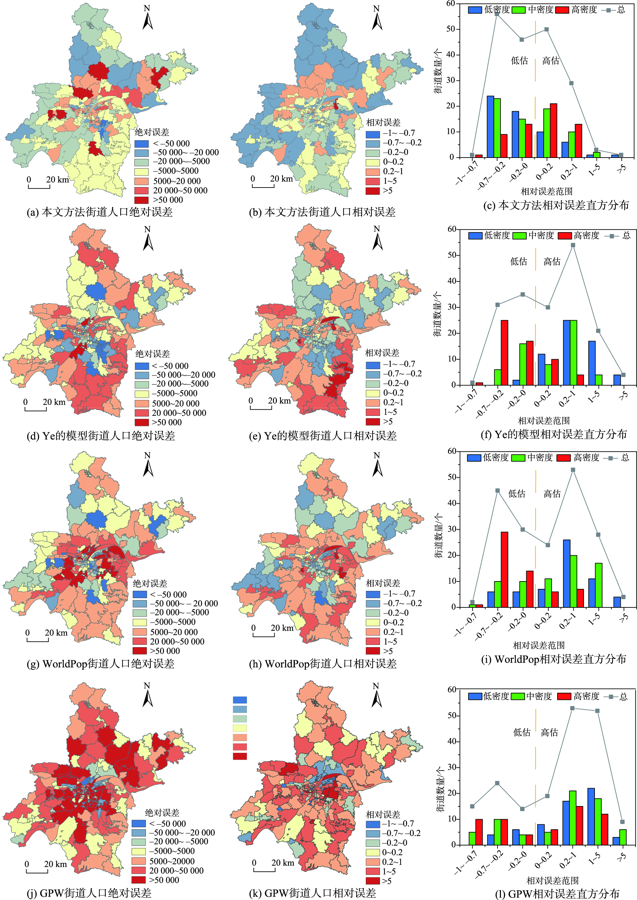
表2 本文方法与GPW、WorldPop及Ye的模型精度对比Tab. 2 Accuracy comparison between our method and GPW, WorldPop and Ye's model |
| 数据集/方法 | MAE | MRE | RMSE | R2 |
|---|---|---|---|---|
| GPW | 46 919 | 1.712 | 81 077 | 0.49 |
| WorldPop | 23 763 | 3.258 | 40 500 | 0.55 |
| Ye的模型 | 16 922 | 0.991 | 25 259 | 0.74 |
| 本文方法 | 10 887 | 0.429 | 16 681 | 0.91 |
| [1] |
董南, 杨小唤, 蔡红艳. 人口数据空间化研究进展[J]. 地球信息科学学报, 2016, 18(10):1295-1304.
[
|
| [2] |
刘云霞, 田甜, 顾嘉钰, 等. 基于大数据的城市人口社会经济特征精细时空尺度估计——数据,方法与应用[J]. 人口与经济, 2022(1):42-57.
[
|
| [3] |
胡云锋, 王倩倩, 刘越, 等. 国家尺度社会经济数据格网化原理和方法[J]. 地球信息科学学报, 2011, 13(5):573-578.
[
|
| [4] |
|
| [5] |
|
| [6] |
陈晴, 侯西勇. 集成土地利用数据和夜间灯光数据优化人口空间化模型[J]. 地球信息科学学报, 2015, 17(11):1370-1377.
[
|
| [7] |
|
| [8] |
卓莉, 陈晋, 史培军, 等. 基于夜间灯光数据的中国人口密度模拟[J]. 地理学报, 2005, 60(2):266-276.
[
|
| [9] |
柏中强, 王卷乐, 姜浩, 等. 基于多源信息的人口分布格网化方法研究[J]. 地球信息科学学报, 2015, 17(6):653-660.
[
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
淳锦, 张新长, 黄健锋, 等. 基于POI数据的人口分布格网化方法研究[J]. 地理与地理信息科学, 2018, 34(4):83-89,124,2.
[
|
| [16] |
郑洪晗, 桂志鹏, 栗法, 等. 夜间灯光数据和兴趣点数据结合的建成区提取方法[J]. 地理与地理信息科学, 2019, 35(2):25-32.
[
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
孙小芳. 夜光遥感支持下的城市人口核密度空间化及自相关分析[J]. 地球信息科学学报, 2020, 22(11):2256-2266.
[
|
| [26] |
|
| [27] |
|
| [28] |
许泽宁, 高晓路. 基于电子地图兴趣点的城市建成区边界识别方法[J]. 地理学报, 2016, 71(6):928-939.
[
|
| [29] |
吴京航, 桂志鹏, 申力, 等. 顾及格网属性分级与空间关联的人口空间化方法[J]. 武汉大学学报·信息科学版, 2021:1-14.
[
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}