
面实体匹配的集成学习CatBoost方法
|
刘 贺(1996— ),男,河南叶县人,硕士生,主要研究方向为空间相似性与空间关联。E-mail: zzuliuhe@163.com |
收稿日期: 2022-01-26
修回日期: 2022-02-23
网络出版日期: 2023-01-25
基金资助
科技基础资源调查专项(2019FY202501)
河南省高等教育教学改革研究与实践重点项目(2021SJGLX299)
Matching Areal Entities with CatBoost Ensemble Method
Received date: 2022-01-26
Revised date: 2022-02-23
Online published: 2023-01-25
Supported by
Science and Technology Fundamental Resources Investigation Program of China(2019FY202501)
The Teaching Research and Practice Projects of Higher Education in Henan Province(2021SJGLX299)
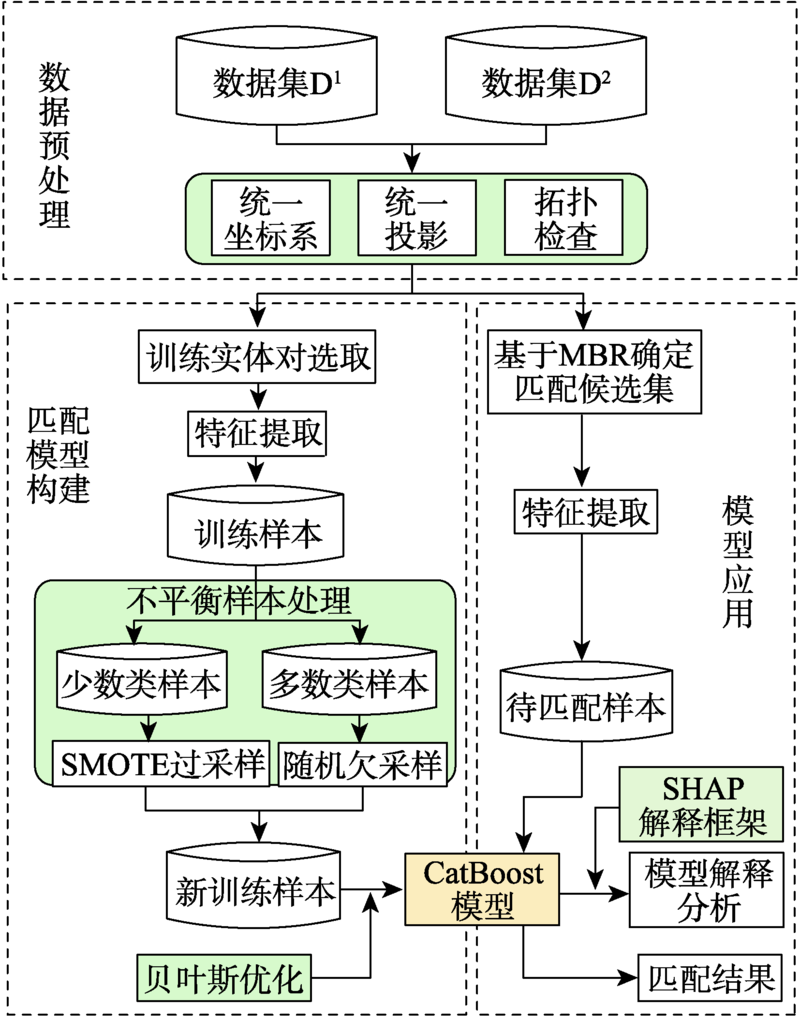
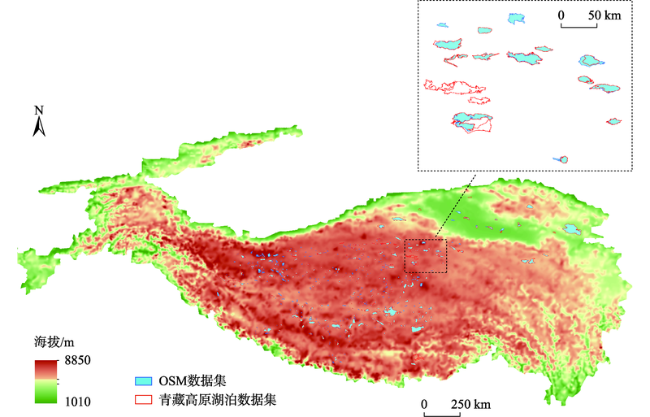
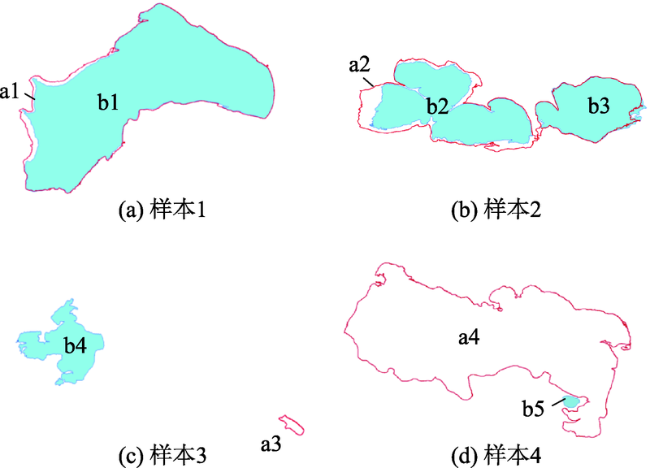
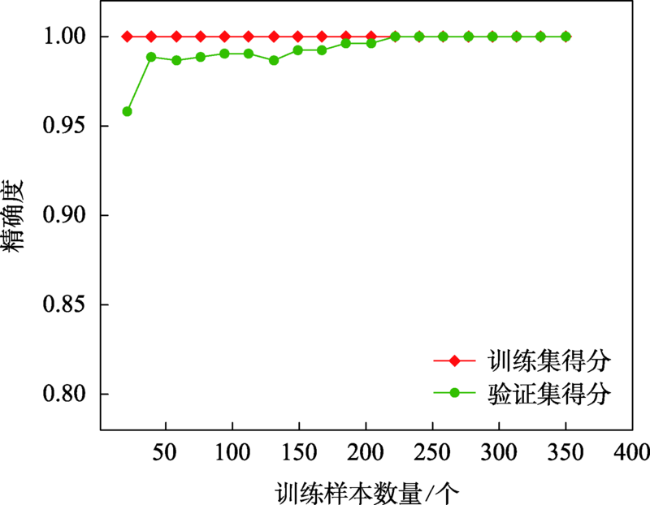
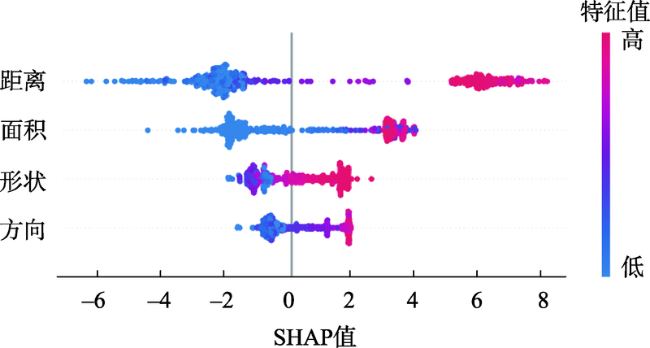
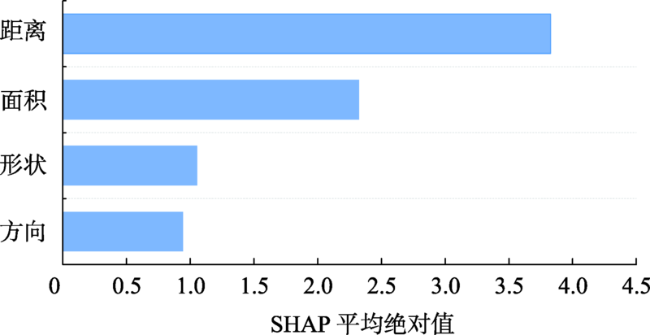
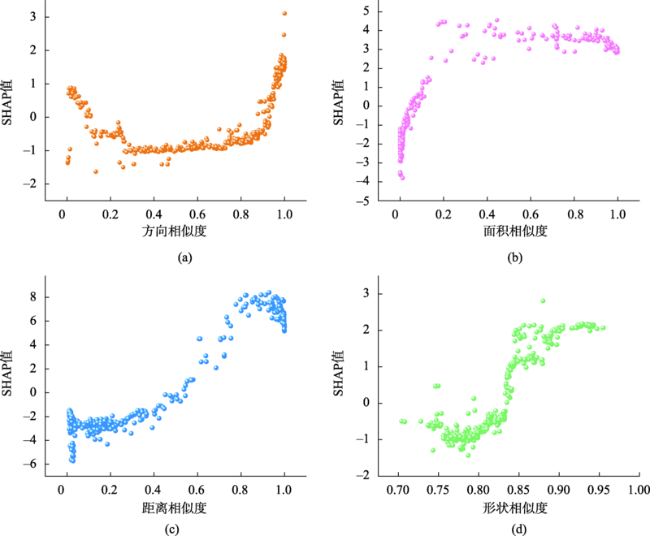
现有的面实体多指标几何匹配方法在计算综合相似度和确定最终匹配实体时面临着指标权重和阈值难以科学量化的难题,集成学习算法通过构建并结合多个机器学习器来完成学习任务,在解决分类问题时体现出了较为明显的性能优势。为此,本文提出了一种基于集成学习算法CatBoost的面实体匹配方法,将匹配问题转化为分类问题。选取形状、面积、方向和位置4个几何特征作为模型分类特征;利用过采样与欠采样相结合的混合重采样技术减轻原始训练样本的类别不平衡度;借助贝叶斯优化算法确定CatBoost模型的最优超参数;引入可解释人工智能领域的SHAP解释框架从全局和局部两个角度解释各输入特征对匹配结果的影响。在青藏高原的面状湖泊数据上对本文提出的方法进行了验证,实验结果表明:对模型预测影响最大的特征是位置,然后依次是面积、形状,影响最小的特征是方向。CatBoost匹配方法在实验数据集上的查准率、查全率和F1-score分别达到0.9937、0.9753和0.9844,相比于直接使用样本不均衡的原始样本进行模型训练,分别提高了约5.8%、0.6%和3.3%。与传统的面实体多指标双向匹配方法和逻辑回归、K近邻、决策树、神经网络等常规机器学习分类算法相比,集成学习算法CatBoost性能表现更加优异,在避免指标权重和阈值设置难题的同时取得了较好的匹配结果。
刘贺 , 郭黎 , 李豪 , 张婉晨 , 白翔天 . 面实体匹配的集成学习CatBoost方法[J]. 地球信息科学学报, 2022 , 24(11) : 2198 -2211 . DOI: 10.12082/dqxxkx.2022.220050
The existing multi-index geometric matching methods for areal entities face the difficulty in scientific quantification of index weights and thresholds when calculating the comprehensive similarity and determining the final matching entity. The ensemble methods in machine learning train multiple base models as ensemble members and combine their predictions into the final output, which have shown excellent performance in solving classification problems. For this purpose, an areal entities matching method based on the CatBoost is proposed in this paper, and this method transforms the matching problem into a classification problem. Firstly, we select four geometric features including shape, area, direction, and position as model classification features. Secondly, to reduce the impact of sample imbalance on model training, we use hybrid resampling combining oversampling and undersampling to alleviate the class imbalance of the original training samples. The Bayesian optimization is used to determine the optimal hyperparameters of the CatBoost model. To improve transparency of ensemble learning models, the SHAP framework in the field of explainable artificial intelligence is introduced to explain the influence of each input feature on the prediction results from both global and local perspectives. Finally, we take the areal lake data of the Qinghai-Tibet Plateau as experimental data to assess the performance of the proposed method. The results demonstrate that the feature with the greatest influence on model prediction is position, followed by area and shape, and the feature with the least influence is direction. The Precision, Recall, and F1-score of this method on the experimental data are 0.9937, 0.9753, and 0.9844, respectively. Hybrid resampling can effectively reduce the impact of unbalanced samples on model training. Compared with the original unbalanced samples for model training, hybrid resampling increases the Precision, Recall, and F1-score by 5.8%, 0.6%, and 3.3%, respectively. Compared with traditional areal entities multi-index bidirectional matching method and conventional machine learning classification algorithms such as logistic regression, K-nearest neighbors, decision trees, and neural networks, the CatBoost performs better and achieves better matching results while avoiding the difficulty of index weights and thresholds setting.
Key words: areal entities; similarity; matching; ensemble methods; CatBoost; class imbalance; Bayesian Optimization; SHAP
表2 待优化参数搜索空间及优化结果Tab. 2 Search space of parameters to be optimized and optimization results |
| 序号 | 名称 | 含义 | 搜索范围 | 贝叶斯优化结果 |
|---|---|---|---|---|
| 参数1 | iterations | 最大树数 | (10, 1000) | 420 |
| 参数2 | depth | 树的深度 | (1, 10) | 4 |
| 参数3 | learning_rate | 学习率 | (0.01,1.0) | 0.016 |
| 参数4 | bagging_temperature | 贝叶斯套袋控制强度 | (0.0, 1.0) | 0.617 |
| 参数5 | l2_leaf_reg | L2正则参数 | (2, 30) | 17 |
| 参数6 | scale_pos_weight | 类别调整权重 | (0.01, 1.0) | 0.874 |
表3 双向匹配方法参数Tab. 3 Bidirectional matching method parameters |
| 匹配方法 | 形状相 似度 | 面积相 似度 | 方向相 似度 | 位置相 似度 | 总相似 度阈值 |
|---|---|---|---|---|---|
| 双向匹配1 | 0.25 | 0.25 | 0.25 | 0.25 | — |
| 双向匹配2 | 0.44 | 0.11 | 0.23 | 0.24 | 0.8 |
| 双向匹配3 | 0.44 | 0.11 | 0.23 | 0.24 | 0.7 |
| 双向匹配4 | 0.44 | 0.11 | 0.23 | 0.24 | 0.6 |
| 双向匹配5 | 0.44 | 0.11 | 0.23 | 0.24 | 0.5 |
表4 各模型匹配实验结果评价指标对比Tab. 4 Comparison of evaluation indicators for the matching results of various models |
| 候选集 操作 | 匹配方法 | 输出结 果数量/对 | 正确匹 配数量/对 | 误匹配 数量/对 | 漏匹配 数量/对 | Precision | Recall | F1-score |
|---|---|---|---|---|---|---|---|---|
| 创建候 选集 | 双向匹配1 | 170 | 162 | 8 | 0 | 0.9529 | 1.0000 | 0.9759 |
| 双向匹配2 | 146 | 145 | 1 | 17 | 0.9931 | 0.8951 | 0.9416 | |
| 双向匹配3 | 160 | 157 | 3 | 5 | 0.9812 | 0.9691 | 0.9752 | |
| 双向匹配4 | 168 | 162 | 6 | 0 | 0.9643 | 1.0000 | 0.9818 | |
| 双向匹配5 | 169 | 162 | 7 | 0 | 0.9586 | 1.0000 | 0.9788 | |
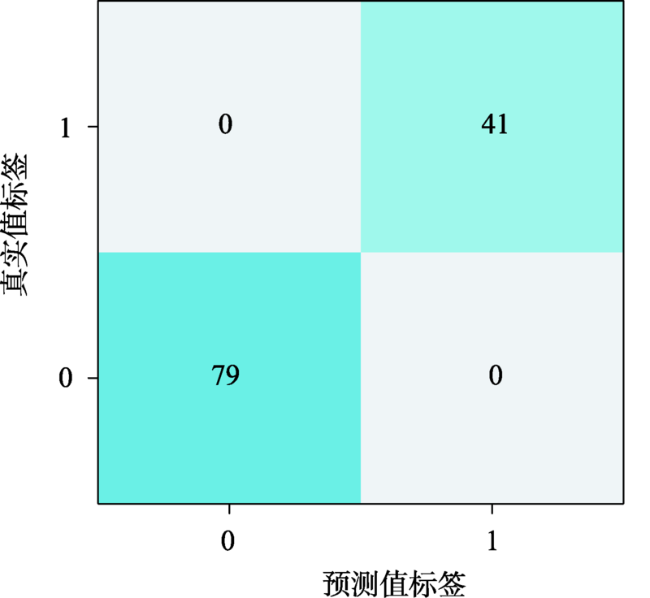
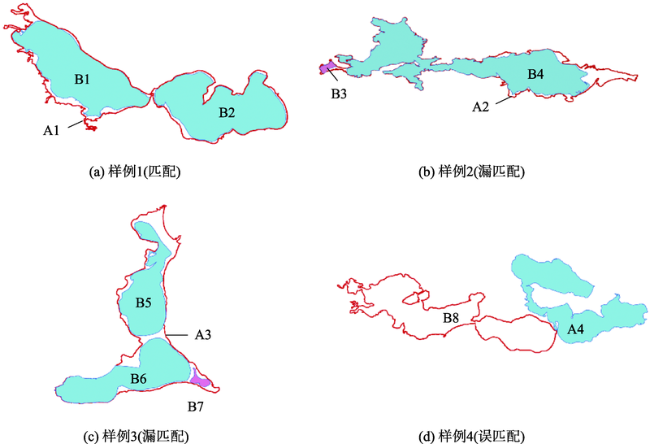
| CatBoost | 159 | 158 | 1 | 4 | 0.9937 | 0.9753 | 0.9844 | |
| 不创建 候选集 | 逻辑回归 | 212 | 154 | 58 | 8 | 0.7264 | 0.9506 | 0.8235 |
| BP神经网络 | 179 | 157 | 22 | 5 | 0.8771 | 0.9691 | 0.9208 | |
| K近邻 | 163 | 151 | 12 | 11 | 0.9264 | 0.9321 | 0.9292 | |
| CART决策树 | 169 | 157 | 12 | 5 | 0.9289 | 0.9691 | 0.9486 | |
| 随机森林 | 165 | 157 | 8 | 5 | 0.9515 | 0.9691 | 0.9602 | |
| CatBoost | 161 | 158 | 3 | 4 | 0.9814 | 0.9753 | 0.9783 | |
| CatBoost* | 170 | 157 | 13 | 5 | 0.9235 | 0.9691 | 0.9457 |
注:*训练样本不经过混合采样处理。 |
| [1] |
廖小罕. 中国对地观测20年科技进步和发展[J]. 遥感学报, 2021, 25(1):267-275.
[
|
| [2] |
赵文波. “中国高分”科技重大专项在对地观测发展历程中的阶段研究[J]. 遥感学报, 2019, 23(6):1036-1045.
[
|
| [3] |
赵文波, 李帅, 李博, 等. 新一代体系效能型对地观测体系发展战略研究[J]. 中国工程科学, 2021, 23(6):128-138.
[
|
| [4] |
姜晶莉, 郭黎, 李豪, 等. 面向空间关联的多源矢量数据空间实体匹配方法[J]. 测绘科学, 2020, 45(4):183-191.
[
|
| [5] |
马京振. 顾及尺度变化的道路和居民地融合处理理论与方法研究[D]. 郑州: 战略支援部队信息工程大学, 2020.
[
|
| [6] |
孙群. 多源矢量空间数据融合处理技术研究进展[J]. 测绘学报, 2017, 46(10):1627-1636.
[
|
| [7] |
郭黎, 崔铁军, 郑海鹰, 等. 基于空间方向相似性的面状矢量空间数据匹配算法[J]. 测绘科学技术学报, 2008, 25(5):380-382.
[
|
| [8] |
刘凌佳. 多尺度面实体匹配方法及其融合应用研究[D]. 武汉: 武汉大学, 2018.
[
|
| [9] |
郝燕玲, 唐文静, 赵玉新, 等. 基于空间相似性的面实体匹配算法研究[J]. 测绘学报, 2008(4):501-506.
[
|
| [10] |
汪汇兵, 唐新明, 邱博, 等. 运用多算子加权的面要素几何匹配方法[J]. 武汉大学学报·信息科学版, 2013, 38(10):1243-1247.
[
|
| [11] |
郭敏, 刘闯, 钱海忠, 等. 利用层次分析法匹配面状居民地[J]. 测绘与空间地理信息, 2018, 41(8):130-134.
[
|
| [12] |
黄宝群, 盛业华, 郭宁宁, 等. 同名边界点的面状居民地要素匹配[J]. 测绘科学, 2018, 43(2):108-113.
[
|
| [13] |
刘立恒, 钱新林, 张福浩, 等. 同名居民地在多尺度下的匹配分析[J]. 测绘科学, 2019, 44(11):123-128.
[
|
| [14] |
许俊奎, 武芳, 魏慧峰. 人工神经网络在居民地面状匹配中的应用[J]. 测绘科学技术学报, 2013, 30(3):293-298.
[
|
| [15] |
|
| [16] |
刘凌佳, 朱道也, 朱欣焰, 等. 基于MBR组合优化算法的多尺度面实体匹配方法[J]. 测绘学报, 2018, 47(5):652-662.
[
|
| [17] |
|
| [18] |
肖湘文, 沈校熠, 柯长青, 等. 基于Sentinel-1A数据的多种机器学习算法识别冰山的比较[J]. 测绘学报, 2020, 49(4):509-521.
[
|
| [19] |
龙玉洁, 李为乐, 黄润秋, 等. 汶川地震震后10 a绵远河流域滑坡遥感自动提取与演化趋势分析[J]. 武汉大学学报·信息科学版, 2020, 45(11):1792-1800.
[
|
| [20] |
方秀琴, 郭晓萌, 袁玲, 等. 随机森林算法在全球干旱评估中的应用[J]. 地球信息科学学报, 2021, 23(6):1040-1049.
[
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
安晓亚, 孙群, 肖强, 等. 一种形状多级描述方法及在多尺度空间数据几何相似性度量中的应用[J]. 测绘学报, 2011, 40(4):495-501.
[
|
| [27] |
马京振, 孙群, 肖强, 等. 利用多级弦长拱高复函数进行面实体综合相似性度量研究[J]. 中国图象图形学报, 2017, 22(4):551-562.
[
|
| [28] |
|
| [29] |
周志华. 机器学习[M]. 北京: 清华大学出版社, 2016.
[
|
| [30] |
李艳霞, 柴毅, 胡友强, 等. 不平衡数据分类方法综述[J]. 控制与决策, 2019, 34(4):673-688.
[
|
| [31] |
|
| [32] |
方昊, 李云. 基于多次随机欠采样和POSS方法的软件缺陷检测[J]. 山东大学学报(工学版), 2017, 47(1):15-21.
[
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
童新华, 张郭秋晨, 韦燕飞. 区域碳收支能力估算的面向对象遥感分类方法[J]. 地球信息科学学报, 2016, 18(12):1675-1683.
[
|
| [40] |
|
/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}