
面向卫星遥感影像检索定位的深度学习全局表征模型评估与分析
|
施群山(1985— ),男,江苏盐城人,博士,副教授,主要从事摄影测量与遥感方向的研究。E-mail: hills1@163.com |
收稿日期: 2022-04-03
修回日期: 2022-05-31
网络出版日期: 2023-01-25
基金资助
国家自然科学基金项目(41701463)
Evaluation and Analysis of Deep Learning Global Representation Model for Satellite Remote Sensing Image Retrieval and Location
Received date: 2022-04-03
Revised date: 2022-05-31
Online published: 2023-01-25
Supported by
National Natural Science Foundation of China(41701463)
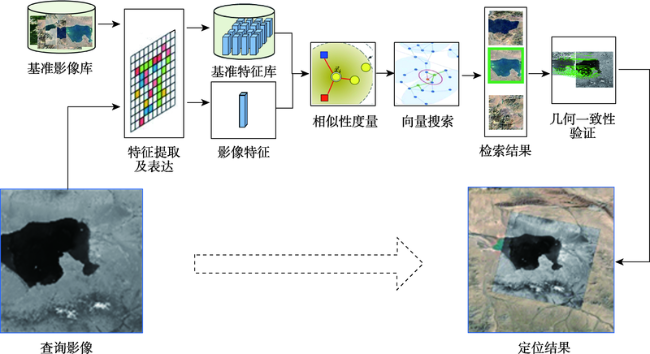
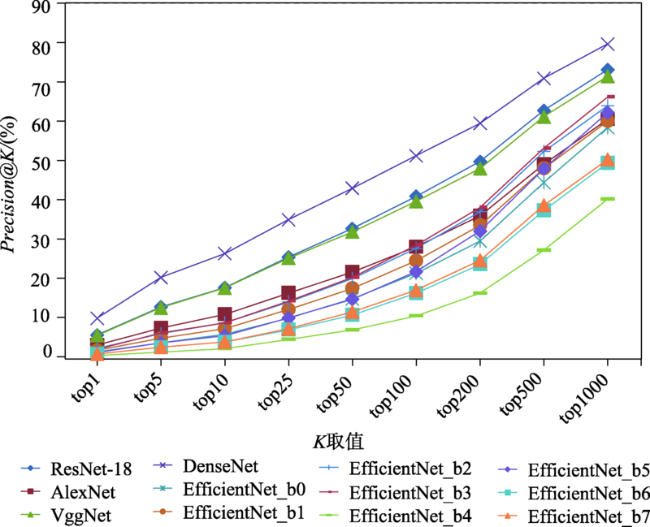
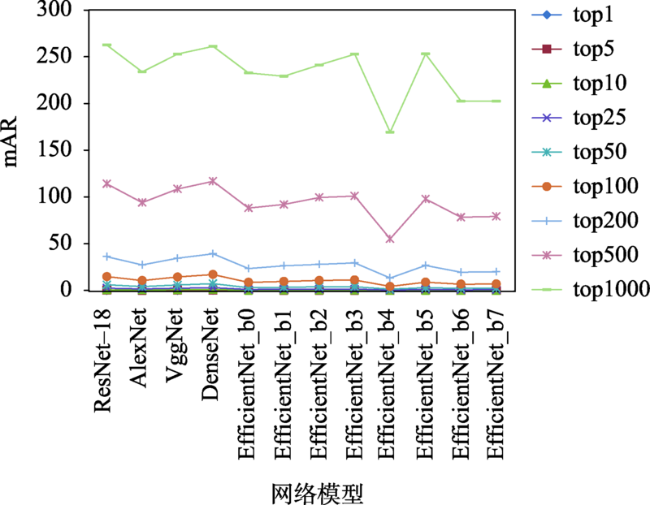
如何快速获取无辅助参数卫星遥感影像地理位置是非合作方式获取的遥感影像信息充分利用的一个关键,利用影像特征的相似性对卫星遥感影像检索来实现定位,是获取无辅助参数卫星遥感影像地理位置的有效手段。为了探寻影像深度学习全局特征用于无辅助参数卫星遥感影像检索定位的可行性,建立了包括Precision@K、平均排序、特征提取时间、特征相似性计算时间、硬件消耗等,涵盖有效性、效率2个方面共计5类指标的评估体系。采用谷歌地球提供的影像数据作为基准影像,在资源三号夏季及冬季数据集上,分别利用AlexNet、VggNet、ResNet、DenseNet、EfficientNet等几种代表性的卷积神经网络预训练模型提取基准影像及查询影像的全局特征,依据评估体系中的指标,对这些网络模型的影像表征效果进行全面的量化评估与分析。试验分析结果表明,DenseNet、ResNet-18、VggNet这3个深度学习神经网络预训练模型提取的全局特征,综合表征效果较好,可有效用于卫星遥感影像检索定位;当K值取200时,DenseNet网络模型的Precision@K值可以达到59.5%,ResNet-18和VggNet网络模型紧随其后,分别为49.7%和48.0%,为进一步利用深度学习全局特征进行卫星遥感影像检索定位,找出了最佳的候选网络模型,为下一步模型优化等研究奠定了基础。

施群山 , 蓝朝桢 , 徐青 , 周杨 , 胡校飞 . 面向卫星遥感影像检索定位的深度学习全局表征模型评估与分析[J]. 地球信息科学学报, 2022 , 24(11) : 2245 -2263 . DOI: 10.12082/dqxxkx.2022.220148
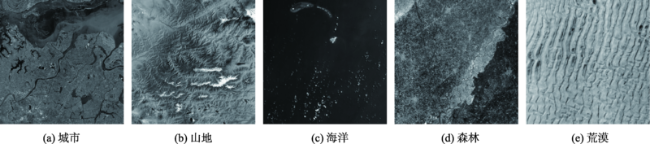
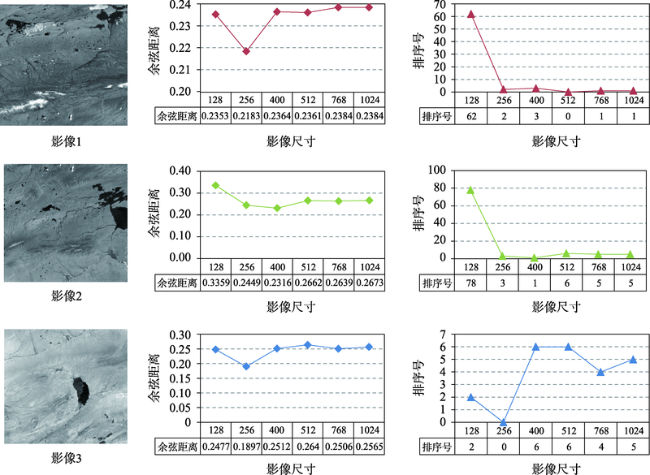
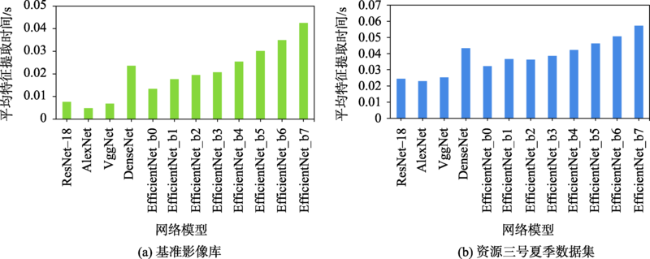
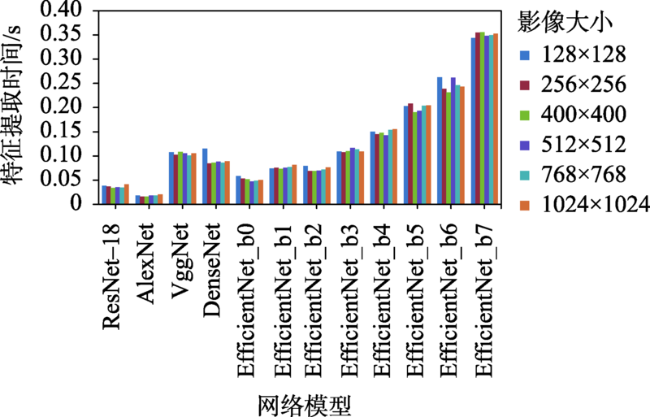
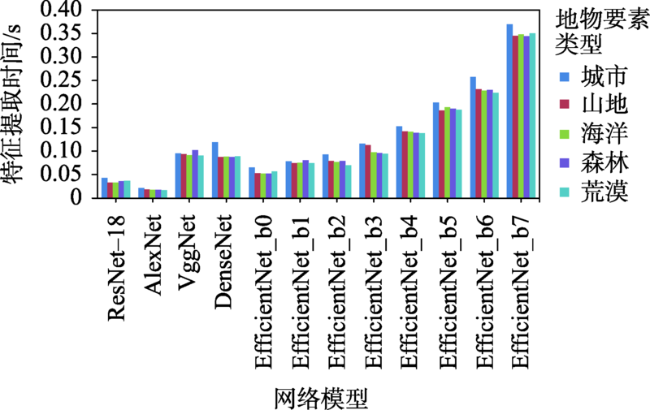
How to quickly obtain the geographical location of satellite remote sensing images without auxiliary parameters is a key to make full use of remote sensing image information obtained by non-cooperative means. Using the similarity of image features to realize satellite remote sensing image retrieval is an effective means to obtain the geographical location of satellite remote sensing images without auxiliary parameters. In order to explore the feasibility of deep learning derived global features for satellite remote sensing image retrieval and positioning without auxiliary parameters, an evaluation system considering both effectiveness and efficiency is established, which quantifies the Precision@K, average ranking, feature extraction time, feature similarity calculation time, and hardware consumption. Using the image data provided by Google Earth as the reference image, the summer and winter data from ZY-3 as the test datasets, several representative convolution neural network such as AlexNet, VggNet, ResNet, DenseNet, and EfficientNet are trained and used to extract the global features of the reference image and test datasets, respectively. Using multiple indicators of the evaluation system, the image representation capability of these models is comprehensively evaluated and quantitatively analyzed. The results show that: (1) the global features extracted by deep learning models have higher effectiveness in satellite remote sensing image retrieval and positioning. Compared with local features, these models provide a new way for satellite remote sensing image retrieval and positioning; (2) based on the test datasets, the performance of DenseNet, ResNet-18, and VggNet is relatively better, and the precision@K of DenseNet is the highest, indicating the highest success rate. The success rate is also a primary index in satellite remote sensing image retrieval and positioning. The mAR of ResNet-18 is close to that of VggNet and slightly higher than that of DenseNet model. In terms of efficiency, the ResNet-18 model is better among the three models, with less feature extraction time, the least feature similarity calculation time, and the smallest feature file. Its feature vector has only 512 dimensions, but its effectiveness is close to the DenseNet model; (3) The deep learning derived global features have good robustness using different image resolutions. With different resolutions, the corresponding cosine distance and the sorting number of the correct image change little in this study, which can overcome the limitation in existing satellite remote sensing image retrieval and positioning methods with different resolutions; (4) Among these models, the feature extraction of AlexNet takes the least time, and EfficientNet_b7 takes the most time in feature extraction. The image size, feature element type, and texture richness have little impact on the time of feature extraction; (5) For the image representation with poor texture information such as desert, ocean, cloud, and continuous mountain, the representation ability of deep learning models needs to be further improved.
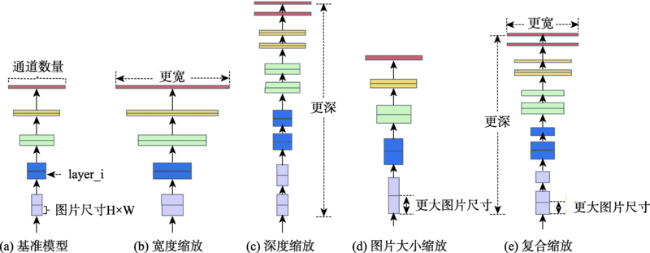
表1 EfficientNet各版本深度、宽度、图片大小缩放参数[59]Tab. 1 Depth, width, and image size scaling parameters of each version of EfficientNet[59] |
| 版本名称 | 缩放参数:宽度 | 缩放参数:深度 | 缩放参数:分辨率 | Dropout率 |
|---|---|---|---|---|
| EfficientNet_b0 | 1.0 | 1.0 | 224 | 0.2 |
| EfficientNet_b1 | 1.0 | 1.1 | 240 | 0.2 |
| EfficientNet_b2 | 1.1 | 1.2 | 260 | 0.3 |
| EfficientNet_b3 | 1.2 | 1.4 | 300 | 0.3 |
| EfficientNet_b4 | 1.4 | 1.8 | 380 | 0.4 |
| EfficientNet_b5 | 1.6 | 2.2 | 456 | 0.4 |
| EfficientNet_b6 | 1.8 | 2.6 | 528 | 0.5 |
| EfficientNet_b7 | 2.0 | 3.1 | 600 | 0.5 |
| EfficientNet_b8 | 2.2 | 3.6 | 672 | 0.5 |
| EfficientNet_L2 | 4.3 | 5.3 | 800 | 0.5 |
表2 网络模型影像表征效果的评估指标体系Tab. 2 Evaluation index system of image representation effect of network model |
| 序号 | 指标名称 | 计算方法 | 主要作用 |
|---|---|---|---|
| 1 | Precision@K | 式(2) | 评价模型能否用于卫星遥感影像检索定位中影像表征的主要指标 |
| 2 | 平均排序(mAR) | 式(4) | 用于辅助Precision@K指标来评价网络模型影像表征的有效性 |
| 3 | 特征提取时间 | 式(5) | 评价网络模型进行特征提取时的效率 |
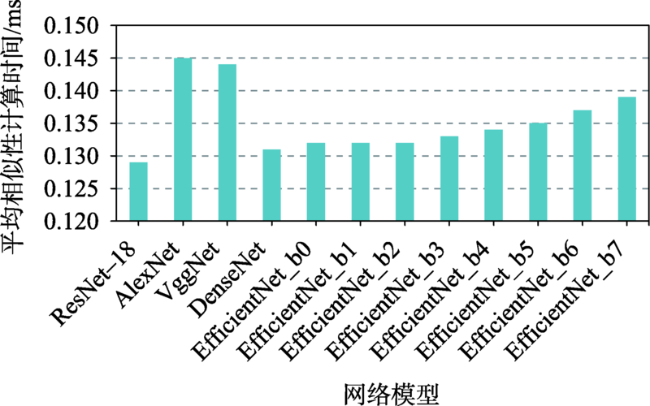
| 4 | 特征相似性计算时间 | 式(6) | 评价利用提取的特征进行检索时的效率 |
| 5 | 硬件消耗 | 特征向量文件大小 | 评价检索时内存的消耗情况 |
表3 试验用网络预训练模型指标参数及下载地址Tab. 3 Parameters and download address of the pre training model used in the experiment |
表4 各网络模型提取的基准影像库的特征库大小情况表Tab. 4 The size of the feature library of the benchmark image library extracted by each network model |
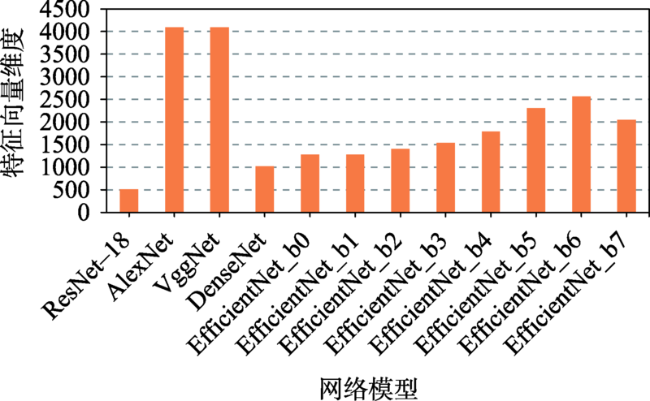
| 网络模型 | 维度 | 大小/KB | 单幅影像特征 大小/KB | 网络模型 | 维度 | 大小/KB | 单幅影像特征 大小/KB |
|---|---|---|---|---|---|---|---|
| ResNet-18 | 512 | 49 262 | 1.63 | EfficientNet_b2 | 1408 | 133 539 | 4.41 |
| AlexNet | 4096 | 386 373 | 12.77 | EfficientNet_b3 | 1536 | 145 579 | 4.81 |
| VggNet | 4096 | 386 373 | 12.77 | EfficientNet_b4 | 1792 | 169 657 | 5.61 |
| DenseNet | 1024 | 97 421 | 3.22 | EfficientNet_b5 | 2048 | 193 738 | 6.40 |
| EfficientNet_b0 | 1280 | 121 500 | 4.02 | EfficientNet_b6 | 2304 | 217 814 | 7.20 |
| EfficientNet_b1 | 1280 | 121 500 | 4.02 | EfficientNet_b7 | 2560 | 241 894 | 7.99 |
表5 各网络模型在用于卫星遥感影像表征时的优缺点Tab. 5 Advantages and disadvantages of each network model when used for representation of satellite remote sensing images |
| 模型 | 优点 | 缺点 |
|---|---|---|
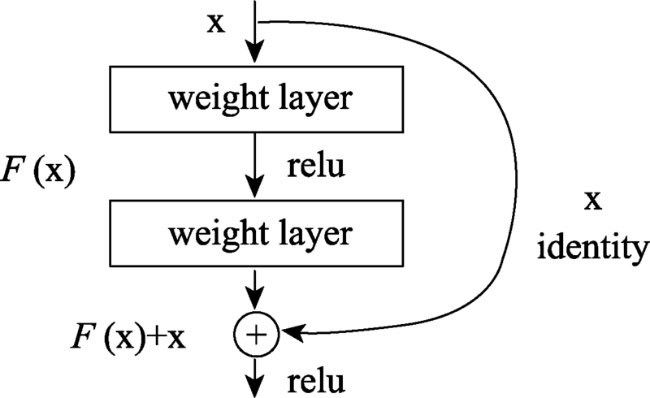
| ResNet-18 | 表征有效性较好,特征向量维度最低,因此特征相似性计算时间最少、特征向量文件最小,影像特征提取时间也较少,综合效果最好 | 表征效果和最好的DenseNet模型有10%左右的差距 |
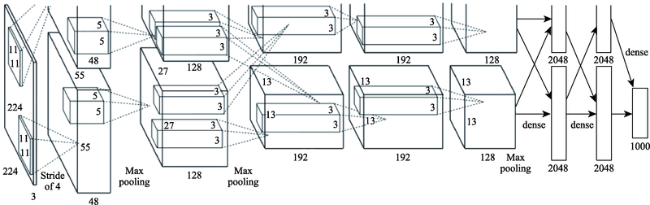
| AlexNet | 影像特征提取时间最少 | 表征有效性较差,特征向量维度最高,因此特征相似性计算时间最长、特征向量文件最大 |
| VggNet | 表征有效性较好 ,影像特征提取时间较少 | 特征向量维度最高,因此特征相似性计算时间较长、特征向量文件最大 |
| DenseNet | 表征有效性最好,特征向量维度较低,因此特征相似性计算时间较少、特征向量文件较小 | 影像特征提取时间较长 |
| EfficientNet_b0 | 特征向量维度较低,因此特征相似性计算时间较少、特征向量文件较小 | 表征有效性较差,影像特征提取时间较长 |
| EfficientNet_b1 | 特征向量维度较低,因此特征相似性计算时间较少、特征向量文件较小 | 表征有效性较差,影像特征提取时间较长 |
| EfficientNet_b2 | 特征向量维度较低,因此特征相似性计算时间较少、特征向量文件较小 | 表征有效性较差,影像特征提取时间较长 |
| EfficientNet_b3 | 特征向量维度较低,因此特征相似性计算时间较少、特征向量文件较小 | 表征有效性较差,影像特征提取时间较长 |
| EfficientNet_b4 | 特征向量维度较低,因此特征相似性计算时间较少、特征向量文件较小 | 表征有效性最差,影像特征提取时间较长 |
| EfficientNet_b5 | 特征向量维度较低,因此特征相似性计算时间较少、特征向量文件较小 | 表征有效性较差,影像特征提取时间较长 |
| EfficientNet_b6 | 特征向量维度较低,因此特征相似性计算时间较少、特征向量文件较小 | 表征有效性较差,影像特征提取时间较长 |
| EfficientNet_b7 | 特征向量维度较低,因此特征相似性计算时间较少、特征向量文件较小 | 表征有效性较差,影像特征提取时间最长 |
| [1] |
李德仁. 展望大数据时代的地球空间信息学[J]. 测绘学报, 2016, 45(4):379-384.
[
|
| [2] |
刘雪莹. 基于深度学习的遥感图像检索方法研究[D]. 北京: 中国科学院大学, 2017.
[
|
| [3] |
李德仁, 张过, 蒋永华, 等. 论大数据视角下的地球空间信息学的机遇与挑战[J]. 大数据, 2022, 8(2):3-14.
[
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
薛朝辉, 周逸飏, 强永刚, 等. 融合NetVLAD和全连接层的三元神经网络交叉视角场景图像定位[J]. 遥感学报, 2021, 25(5):1095-1107.
[
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
毛雪宇, 彭艳兵. 增量角度域损失和多特征融合的地标识别[J]. 中国图象图形学报, 2020, 25(8):1567-1577.
[
|
| [13] |
王懋. 地标图像检索及街景图像位置识别技术研究[D]. 长沙: 国防科技大学, 2018.
[
|
| [14] |
毛雪宇. 基于深度特征的地标图像识别[D]. 武汉: 武汉邮电科学研究院, 2020.
[
|
| [15] |
|
| [16] |
秦剑琪. 无辅助参数遥感影像全球快速检索定位技术[D]. 郑州: 战略支援部队信息工程大学, 2021.
[
|
| [17] |
暴雨. 基于对象深度特征融合的图像表征方法研究[D]. 大连: 大连理工大学, 2017.
[
|
| [18] |
孙韶言. 基于深度学习表征的图像检索技术[D]. 合肥: 中国科学技术大学, 2017.
[
|
| [19] |
|
| [20] |
|
| [21] |
蔡华悦. 图像深度特征提取方法研究[D]. 长沙: 国防科技大学, 2018.
[
|
| [22] |
张坷, 冯晓晗, 郭玉荣, 等. 图像分类的深度卷积神经网络模型综述[J]. 中国图象图形学报, 2021, 26(10):305-2325.
[
|
| [23] |
季长清, 高志勇, 秦静, 等. 基于卷积神经网络的图像分类算法综述[J]. 计算机应用, 2022, 42(4):1044-1049.
[
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
|
| [51] |
|
| [52] |
|
| [53] |
|
| [54] |
|
| [55] |
|
| [56] |
|
| [57] |
|
| [58] |
|
| [59] |
李金洪. 机器视觉之TensorFlow 2入门、原理与应用实战[M]. 北京: 人民邮电出版社, 2020.
[
|
| [60] |
|
| [61] |
王崎. 大规模数据集下图像表征问题的研究和应用[D]. 广东: 广东工业大学, 2020.
[
|
| [62] |
韦娜, 耿国华, 周明全. 基于内容的图像检索系统性能评价[J]. 中国图象图形学报, 2004, 9(11):1271-1276.
[
|
| [63] |
秦志新, 裴东兴. 基于内容的图像检索技术概述[J]. 数字技术与应用, 2012(1):159,161.
[
|
| [64] |
贾强槐. 图像检索结果质量评价[D]. 合肥: 中国科学技术大学, 2015.
[
|
| [65] |
杨宇. 基于深度学习特征的图像推荐系统[D]. 成都: 电子科技大学, 2015.
[Image recommendation system based on the image features obtained from deep learning[D]. Chengdu: University of Electronic Science and Technology of China, 2015. ]
|
| [66] |
张松伟. 基于深度学习的图像检索方法研究[D]. 武汉: 华中科技大学, 2019.
[
|
| [67] |
龚海华. 基于语义哈希的图像检索算法研究[D]. 合肥: 中国科学技术大学, 2019.
[
|
| [68] |
潘雪琛. 多源数据辅助线阵遥感影像定位技术研究[D]. 郑州: 战略支援部队信息工程大学, 2018.
[
|
| [69] |
自然资源部国土卫星遥感应用中心. 自然资源卫星遥感云服务平台[EB/OL].(2022-02-20) [2022-02-20]. http://sasclouds.com/chinese/normal/
[ Land Satellite Remote Sensing Application Center of the Ministry of Natural Resources. Natural resources satellite remote sensing cloud service platform[EB/OL]. (2022-02-20) [2022-02-20]. http://sasclouds.com/chinese/normal/
|
| [70] |
|
| [71] |
Torchvision[EB/OL]. (2022-3-11) [2022-4-18]. https://pypi.org/project/torchvision/
|
| [72] |
ImageNet[EB/OL]. (2021-3-11) [2022-4-18]. https://www.image-net.org/
|
| [73] |
张永显. 无人机序列影像上路标实时识别快速定位技术研究[D]. 郑州: 战略支援部队信息工程大学, 2020.
[
|
| [74] |
蓝朝桢, 卢万杰, 于君明, 等. 异源遥感影像特征匹配的深度学习算法[J]. 测绘学报, 2021, 50(2):189-202.
[
|
/
| 〈 |
|
〉 |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}