
基于条件生成对抗网络的电子地图可视水印去除方法
|
江宝得(1982— ),男,湖北武汉人,博士,硕士生导师,主要从事深度学习与智能制图等方面研究。E-mail: jiangbaode@cug.edu.cn |
收稿日期: 2022-08-22
修回日期: 2022-11-01
网络出版日期: 2023-04-19
基金资助
地理信息工程国家重点实验室基金资助项目(SKLGIE2019-Z-4-1)
地质探测与评估教育部重点实验室主任基金(GLAB2020ZR11)
Electronic Map Visible Watermark Removal with Conditional Generative Adversarial Networks
Received date: 2022-08-22
Revised date: 2022-11-01
Online published: 2023-04-19
Supported by
State Key Laboratory of Geo-information Engineering(SKLGIE2019-Z-4-1)
Key Laboratory of Geological Survey and Evaluation of Ministry of Education(GLAB2020ZR11)
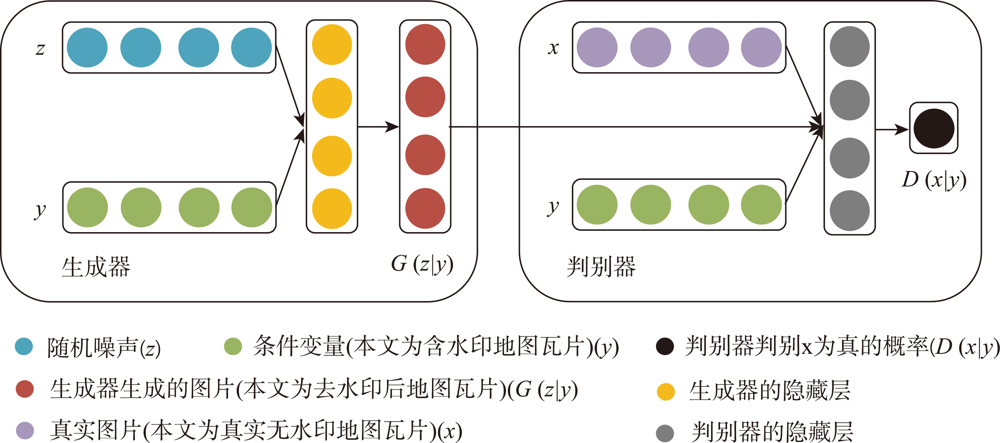
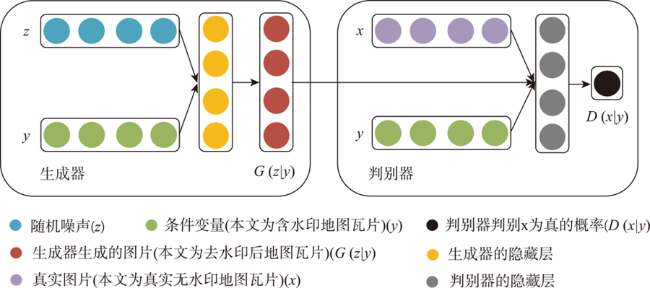
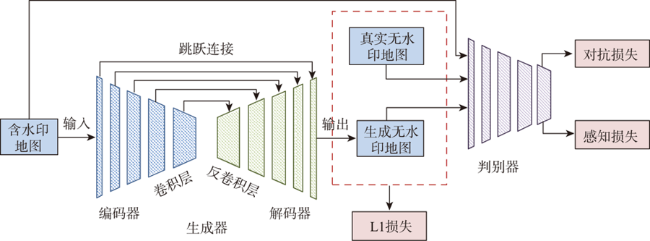
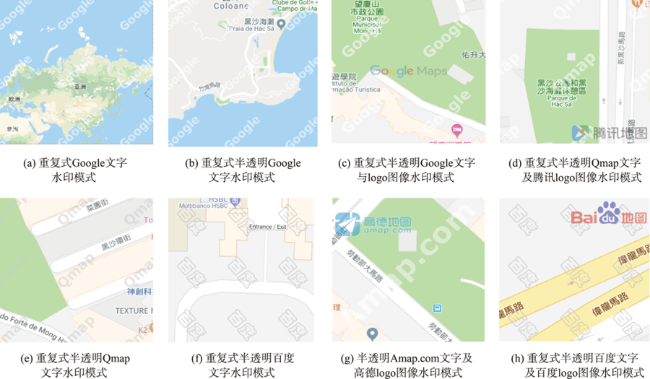
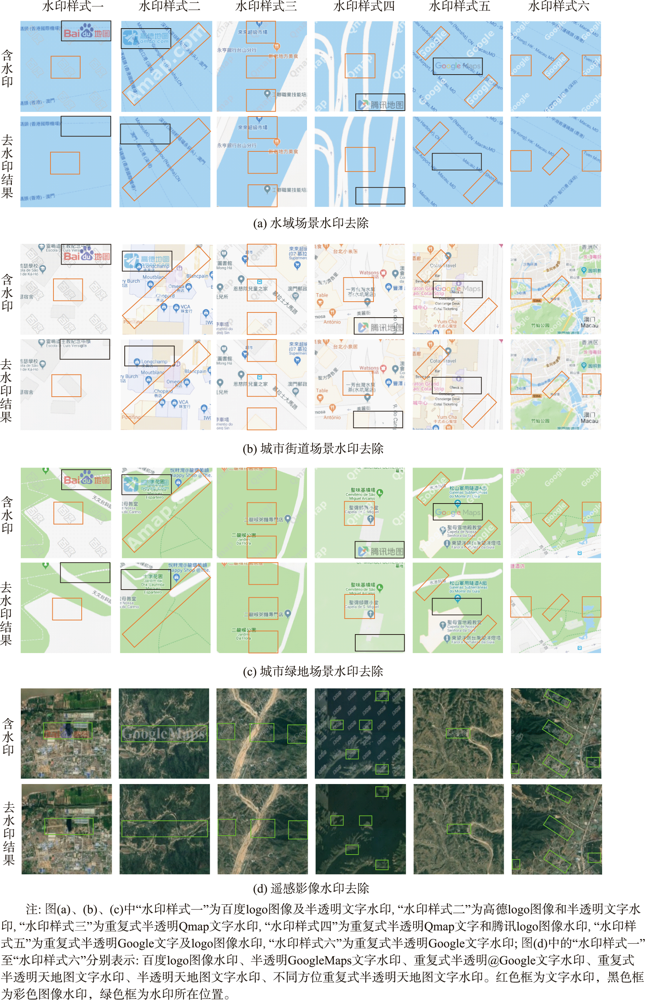
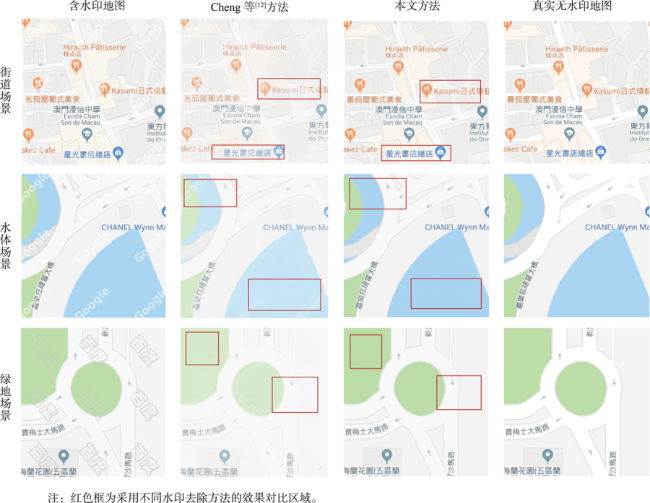
水印对于电子地图版权的保护十分重要,开展可视水印的去除研究有助于从攻防对抗的角度评价可视水印的有效性,进而提高电子地图可视水印的抗攻击研究水平。针对已有基于深度学习的可视水印去除方法存在训练样本量大、效率低、可视水印去除后有残留或要素丢失等问题,本文提出一种基于条件生成对抗网络(CGAN)的电子地图可视水印去除方法。该方法的模型主要由一个生成器和一个判别器组成,其中生成器采用U-Net结构,保证去除可视水印后生成的地图区域的真实性,判别器则采用基于区域判别的全卷积网络,通过对抗训练来区分生成的地图瓦片与真实地图瓦片之间的差异,使得可视水印去除后重建的电子地图更接近真实地图。实验表明,本文提出的方法简单易行,模型训练速度比基于全卷积网络的算法快4倍,能够去除文字、彩色图像及二者混合等模式的可视水印,可实现Google、高德、百度等国内外地图厂商提供的导航电子地图、遥感影像等多种地图瓦片上的可视水印批量去除,无需人工干预,且水印去除后的地图瓦片与原始真实地图瓦片有着良好的结构相似性。
江宝得 , 许少芬 , 王进 , 王淼 . 基于条件生成对抗网络的电子地图可视水印去除方法[J]. 地球信息科学学报, 2023 , 25(2) : 288 -297 . DOI: 10.12082/dqxxkx.2023.220616
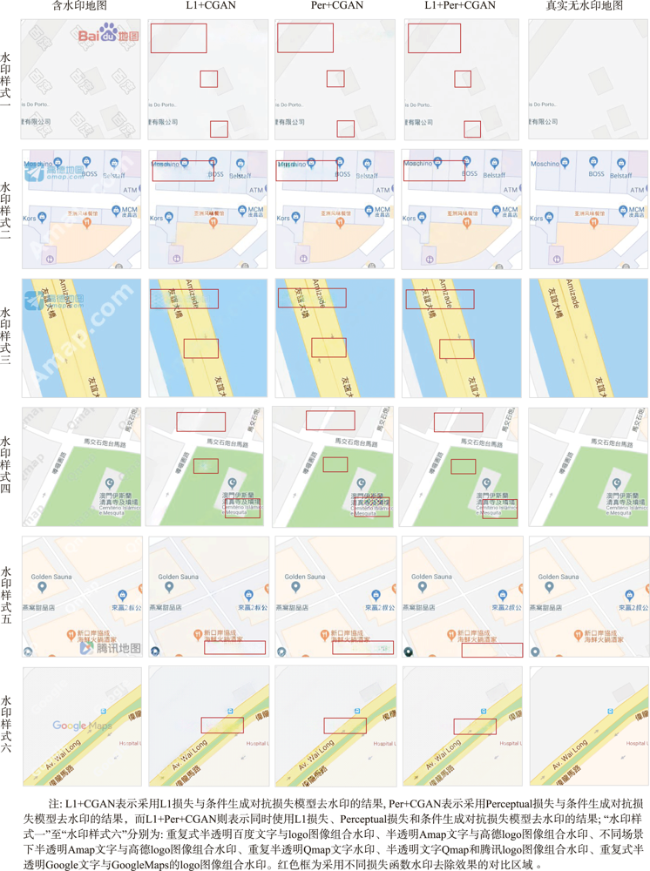
Watermarks play an important role in the copyright protection of electronic map tiles. Research on visible watermark removal can help to evaluate the effectiveness of watermarks and improve anti-attack capabilities in an adversarial manner. The existing deep learning-based methods of visible watermark removal have problems such as requiring a large number of training samples, low efficiency, and watermark residual or unrealistic maps generated in results after watermark removal. To address these problems, inspired by the idea of image inpainting, this paper proposes a method based on conditional Generative Adversarial Networks (CGAN) to remove the visible watermarks on electronic maps. The network model mainly consists of a generator and a discriminator. Specifically, the generator adopts a U-Net structure, which includes an encoding stage and a decoding stage. In the encoding stage, multiple convolutional layers are used to obtain multi-scale features of the input watermarked map tile, and jump connections are used in the decoding stage to stitch features and up sample them to generate the watermark-free map tiles. The discriminator uses patch GAN, a full convolutional network model based on region discrimination, to evaluate the authenticity of the generated map tiles. In order to enrich the details and improve the verisimilitude of the generated maps, this paper further adds perceptual loss and L1 loss with the adversarial loss of CGAN. By optimizing the loss function of the real watermark-free map and the generated watermark-free map, an extremely real-like generated watermark-free map can be obtained. The proposed model has been extensively tested on a road map dataset, which was retrieved from domestic and foreign electronic map manufacturers such as Google, Gaode, Baidu, etc. It includes over 3000 watermarked map tiles with different watermark patterns like texts, colorful logos, and both. The results demonstrate that the proposed model in this paper can realize batch removal of visual watermarks on various map tiles such as navigation electronic maps and remote sensing images, and the training speed of the model is 4 times faster than the FCN-based approach. The comparison results by using different combination of loss functions show that the proposed perceptual loss and L1 loss can significantly improve the values of the evaluation metrics of MSE, PSNR, and DSSIM, which explain the similarity of the generated map tiles with the real map tiles. In a word, the approach proposed in this paper is efficient and simple. It can effectively protect the geometric and geographic information in the map tiles after watermark removal and realize batch removal without manual interferences.
表1 使用不同损失函数的模型的指标评价结果Tab. 1 Evaluation indicators of models using different loss functions |
| Loss | MSE | PSNR | DSSIM |
|---|---|---|---|
| L1+CGAN | 38.2092 | 33.5013 | 0.0185 |
| Per+CGAN | 45.7431 | 34.1378 | 0.0134 |
| L1+Per+CGAN | 33.1858 | 35.5405 | 0.0097 |
| [1] |
|
| [2] |
刘波. 基于深度学习的图像可见水印的检测及去除方法研究[D]. 哈尔滨: 哈尔滨工业大学, 2019.
[
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}