
基于双注意力残差网络的高分遥感影像道路提取模型
|
刘 洋(1996— ),男,安徽淮南人,硕士,主要从事高分辨率遥感影像处理。E-mail: 20201248058@nuist.edu.cn |
收稿日期: 2022-07-14
修回日期: 2022-09-08
网络出版日期: 2023-04-19
基金资助
国家自然科学基金项目(41971414)
Road Extraction Model of High-resolution Remote Sensing Images based on Dual-attention Residual Network
Received date: 2022-07-14
Revised date: 2022-09-08
Online published: 2023-04-19
Supported by
National Natural Science Foundation of China(41971414)
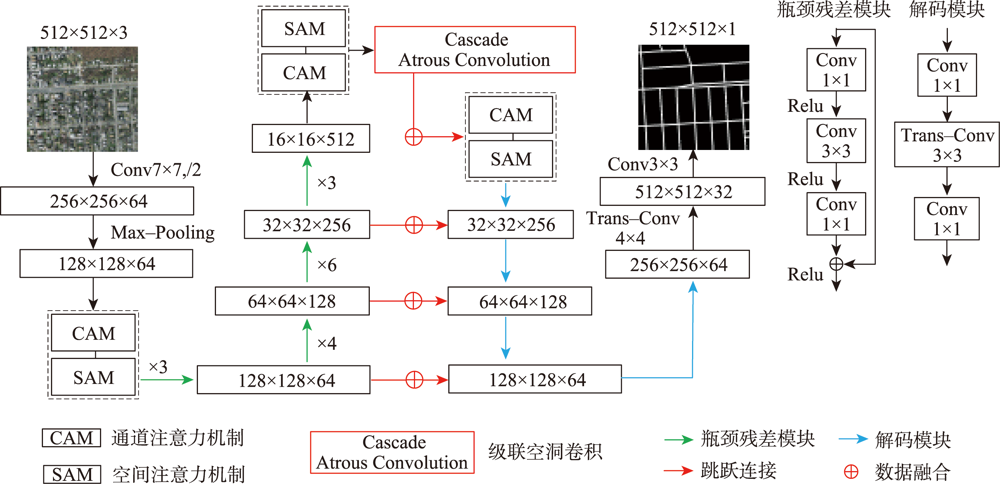
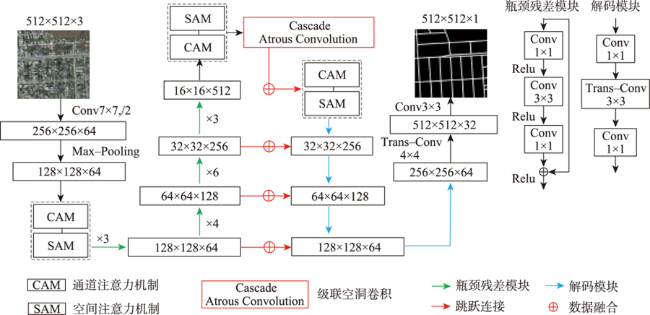
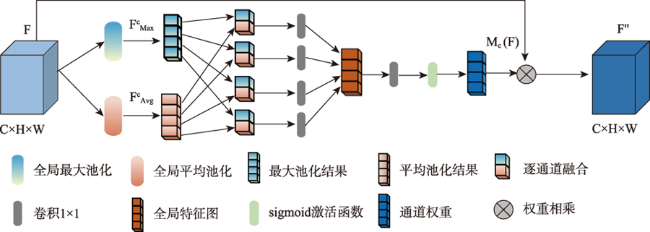
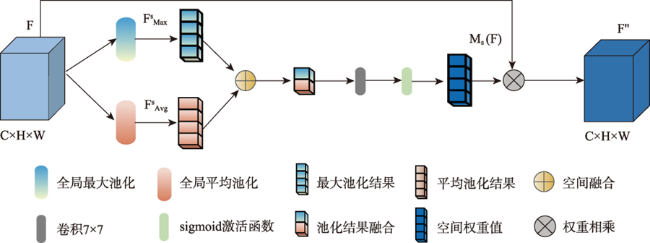
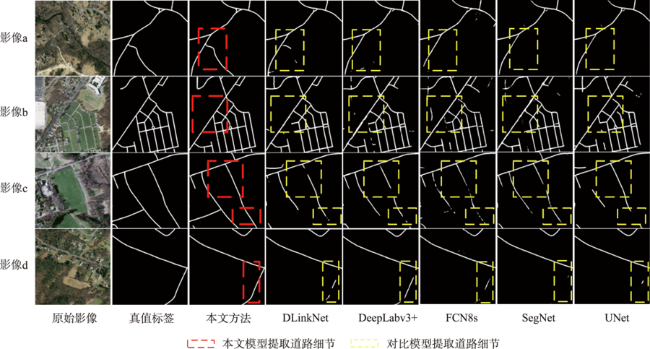
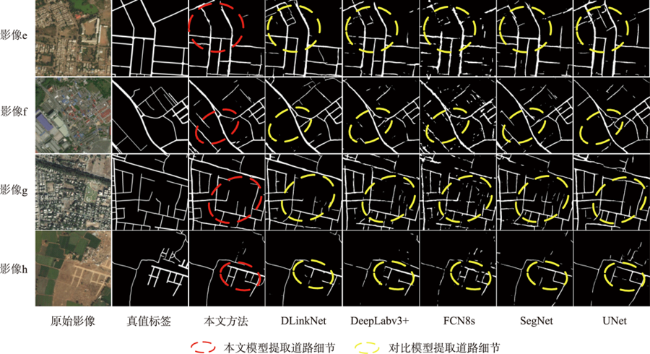
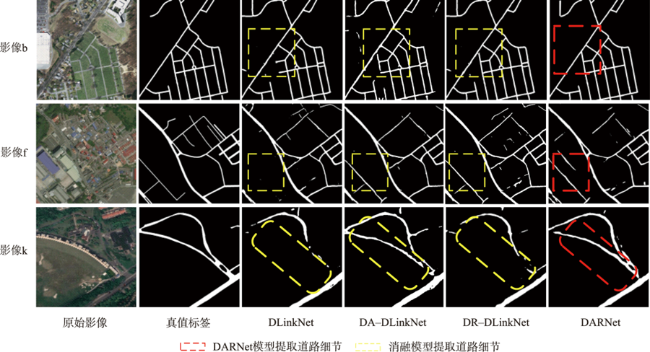
高分辨率遥感影像中,道路光谱信息丰富,且空间几何结构更清晰。但是,基于高分遥感影像的道路提取面临道路尺寸变化大、容易受树木、建筑物及阴影遮挡等因素影响,导致提取结果不完整。此外,高分遥感影像中同物异谱和异物同谱现象较为严重,从而影响道路提取结果连续性及细小道路信息完整性,而且难以区分道路和非道路不透水层。因此,本文提出基于双注意力残差网络的道路提取模型DARNet,利用深度编码网络,获取细粒度高阶语义信息,增强网络对细小道路的提取能力,通过嵌入串联式通道-空间双重注意力模块,获取道路特征图逐通道的全局语义信息,实现道路特征的高效表达及多尺度道路信息的深层融合,增强阴影和遮挡环境下网络模型的鲁棒性,改善道路提取细节缺失现象,实现复杂环境下高效、准确的道路自动化提取。本文在3个实验数据集对DARNet和DLinkNet、DeepLabV3+等5个对比模型进行对比试验和定量评估,结果表明,本文DARNet模型的F1分别为77.92%、67.88%和80.37%,高于对比模型。此外,定性比较表明,本文提出模型可以有效克服由于物体阴影、遮挡和高分影像光谱变化导致道路提取不准确与不完整问题,改善细小道路漏提、错提等现象,提高道路网提取的完整性和连续性。
刘洋 , 康健 , 管海燕 , 汪汉云 . 基于双注意力残差网络的高分遥感影像道路提取模型[J]. 地球信息科学学报, 2023 , 25(2) : 396 -408 . DOI: 10.12082/dqxxkx.2023.220513
In high-resolution remote sensing images, the spectral information of road is rich, and the spatial geometric structure is clear. However, the road extraction is still faced with challenges such as changes in road size and influences from trees, buildings, and occlusion shadow, which often leads to incomplete extraction results. In addition, the phenomenon of the same object with different spectrum and the foreign body with the same spectrum is more serious, which affects the continuity of road extraction and the integrity of small road information, and it is difficult to distinguish road and non-road impervious layer. Therefore, a road extraction model, DARNet, is proposed in this study to address the above limitations. It uses a deep learning network to obtain fine-grained high-level semantic information and enhance the network's ability to extract fine roads. By embedding the serial channel-space dual attention module, the global semantic information of road feature map is obtained, and the robustness of the network model in shadow and occlusion environment is enhanced. The efficient expression of road features and the deep fusion of multi-scale road information are achieved, the phenomenon of missing details in road extraction is improved, and the efficient and accurate automatic road extraction in complex environment is realized. In this paper, a quantitative comparison is carried out based on three experimental datasets, using DARNet, DLinkNet, and DeepLabV3+ etc. The results show that the F1 of the proposed model is 77.92%, 67.88% and 80.37% for three datasets, respectively, which is higher than that of the comparison models. In addition, the qualitative comparison shows that the proposed model can effectively overcome the problem of inaccurate and incomplete road extraction caused by object shadow, occlusion, and spectral changes of high-resolution images, avoid the phenomenon of missing and miscarrying of small roads, and improve the integrity and continuity of road network extraction.
表1 实验数据集参数统计Tab. 1 Statistical table of experimental data sets parameters |
| 数据集 | 年份 | 影像大小/像素 | 空间分辨率/m | 影像数量/张 |
|---|---|---|---|---|
| Massachusetts | 2013 | 1500×1500 | 1 | 1171 |
| DeepGlobe | 2018 | 1024×1024 | 0.5 | 6226 |
| CHN6-CUG | 2021 | 512×512 | 0.5 | 4511 |
表2 DARNet和对比模型在实验数据集上提取结果统计Tab. 2 DARNet and the comparison model extract the result tables on the experimental dataset (%) |
| 方法 | Massachusetts | DeepGlobe | CHN6-CUG | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Pre | F1 | mIoU | Pre | F1 | mIoU | Pre | F1 | mIoU | |||
| DARNet | 78.81 | 77.92 | 80.43 | 98.56 | 67.88 | 73.91 | 81.82 | 80.37 | 81.25 | ||
| DLinkNet | 77.25 | 74.48 | 78.22 | 97.16 | 64.66 | 71.39 | 80.48 | 77.43 | 79.02 | ||
| DeepLabv3+ | 77.89 | 72.79 | 77.09 | 97.07 | 64.42 | 71.24 | 76.82 | 72.38 | 75.30 | ||
| FCN8s | 72.30 | 68.80 | 57.96 | 96.14 | 65.17 | 71.68 | 73.97 | 70.32 | 73.81 | ||
| SegNet | 78.52 | 73.25 | 57.79 | 96.85 | 61.66 | 69.63 | 76.99 | 71.96 | 75.02 | ||
| UNet | 78.78 | 74.50 | 78.24 | 96.94 | 67.09 | 72.90 | 77.57 | 74.72 | 76.95 | ||
图6 DARNet和对比模型在Massachusetts数据集的道路提取结果Fig. 6 DARNet and Contrast model for road extraction results on Massachusetts dataset |
图7 DARNet和对比模型在DeepGlobe数据集的道路提取结果Fig. 7 DARNet and Contrast model for road extraction results on DeepGlobe dataset |
表3 DARNet和消融模型在实验数据集提取结果统计 |
| Massachusetts | DeepGlobe | CHN6-CUG | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | Pre | F1 | mIoU | Pre | F1 | mIoU | Pre | F1 | mIoU | ||
| DARNet | 78.81 | 77.92 | 80.43 | 98.56 | 67.88 | 73.91 | 81.82 | 80.37 | 81.25 | ||
| DR-DLinkNet | 77.42 | 74.68 | 78.36 | 97.33 | 65.03 | 71.54 | 80.57 | 77.70 | 79.22 | ||
| DA-DLinkNet | 77.89 | 74.66 | 78.57 | 96.93 | 65.32 | 71.78 | 80.82 | 77.58 | 79.14 | ||
| DLinkNet | 77.25 | 74.48 | 78.22 | 97.16 | 64.66 | 71.39 | 80.48 | 77.43 | 79.02 | ||
Tab. 3 DARNet and ablation model extracted results from experimental datasets in statistical tables (%) |
| [1] |
|
| [2] |
张永宏, 何静, 阚希, 等. 遥感图像道路提取方法综述[J]. 计算机工程与应用, 2018, 54(13):1-10,51.
[
|
| [3] |
曹敏. 基于频谱的高分辨率遥感影像纹理尺度分析及选择[D]. 北京: 中国地质大学(北京), 2020.
[
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
韩洁, 郭擎, 李安. 结合非监督分类和几何—纹理—光谱特征的高分影像道路提取[J]. 中国图象图形学报, 2017, 22(12):1788-1797.
[
|
| [11] |
曹云刚, 王志盼, 杨磊. 高分辨率遥感影像道路提取方法研究进展[J]. 遥感技术与应用, 2017, 32(1):20-26.
[
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
戴激光, 王杨, 杜阳, 等. 光学遥感影像道路提取的方法综述[J]. 遥感学报, 2020, 24(7):804-823.
[
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
宋廷强, 刘童心, 宗达, 等. 改进U-Net网络的遥感影像道路提取方法研究[J]. 计算机工程与应用, 2021, 57(14):209-216.
[
|
| [32] |
|
| [33] |
刘航, 汪西莉. 基于注意力机制的遥感图像分割模型[J]. 激光与光电子学进展, 2020, 57(4):11.
[
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
/
| 〈 |
|
〉 |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}