
基于改进全卷积神经网络模型的土地覆盖分类方法研究
|
衡雪彪(1999— ),男,河南焦作人,硕士生,从事深度学习遥感信息提取研究。E-mail: hxb719617378@163.com |
收稿日期: 2022-06-23
修回日期: 2022-08-02
网络出版日期: 2023-04-19
基金资助
国家自然科学基金项目(411771478)
Research on Land Cover Classification Method based on Improved Fully Convolutional Neural Network Model
Received date: 2022-06-23
Revised date: 2022-08-02
Online published: 2023-04-19
Supported by
National Natural Science Foundation of China(411771478)
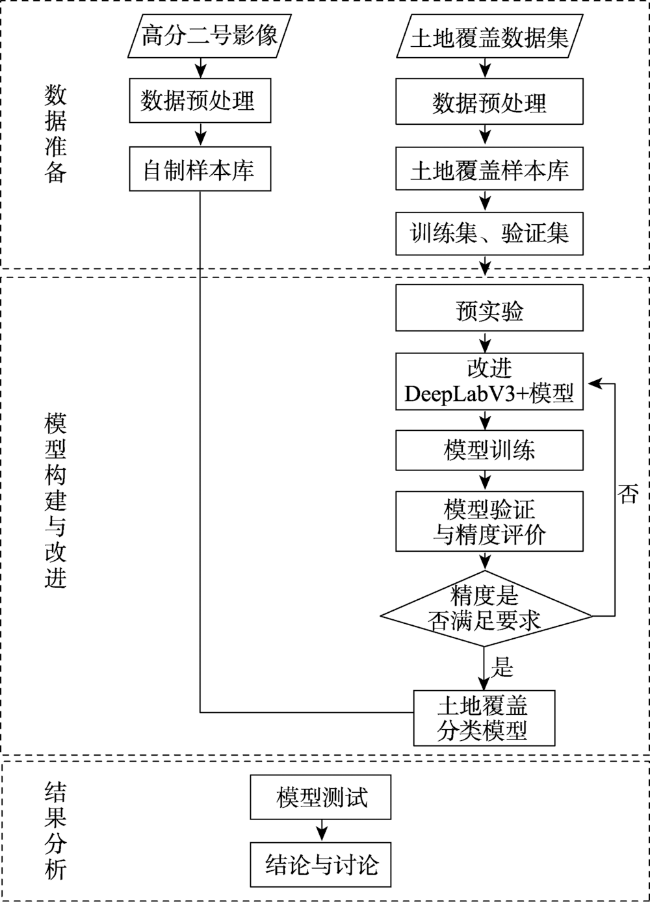
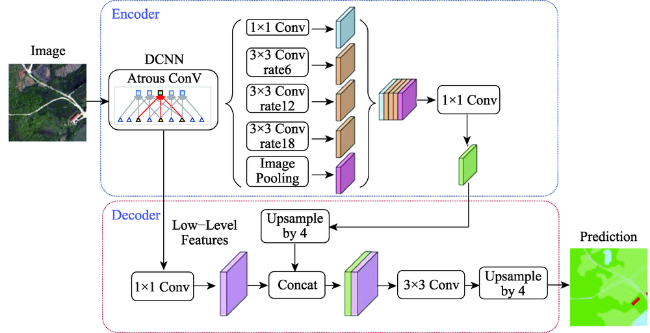
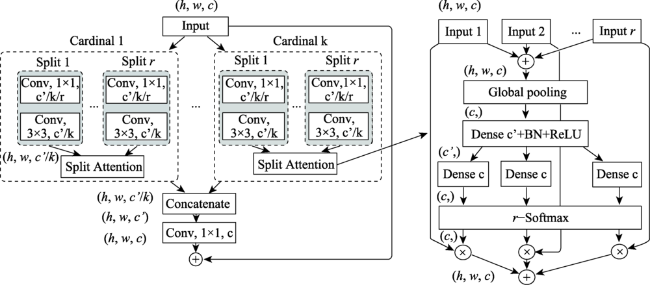
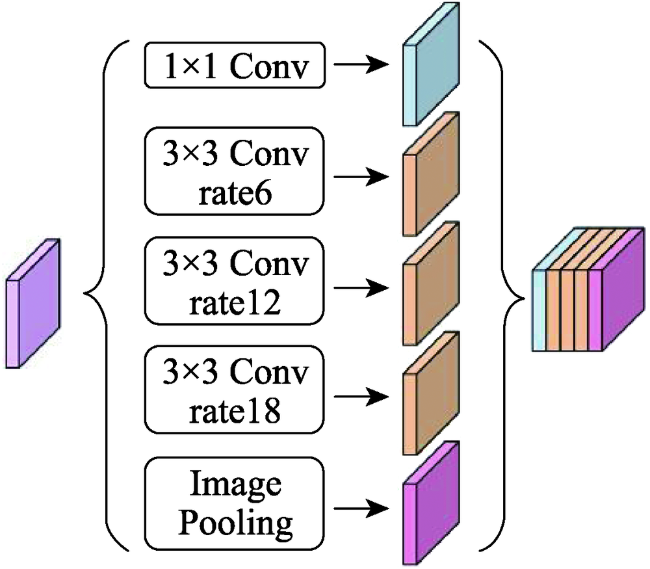
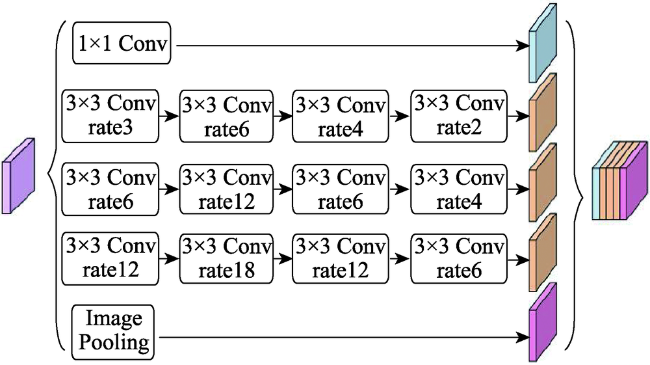
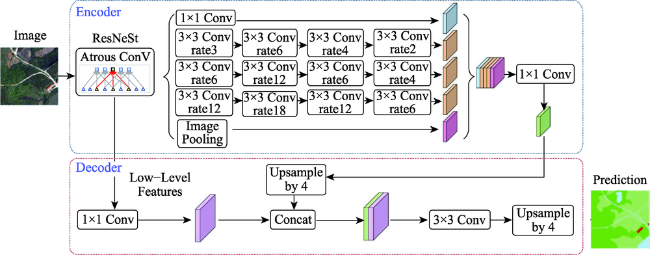
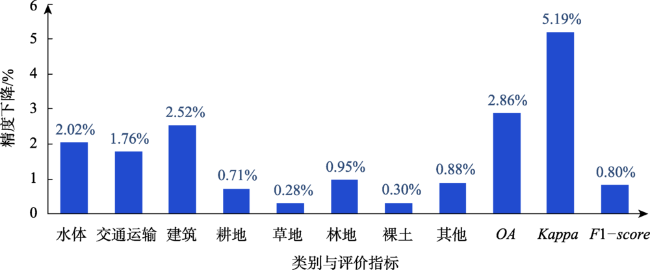
遥感卫星数据是地球表面信息的重要来源,但利用传统的遥感分类方法进行土地覆盖分类局限性大、过程繁琐、解译精度依赖专家经验,而深度学习方法可以自适应地提取地物更多深层次的特征信息,适用于高分辨率遥感影像的土地覆盖分类。文中对高分辨率影像中水体、交通运输、建筑、耕地、草地、林地、裸土等进行高精度分类,结合遥感多地物分类的特点,以DeepLabV3+模型为基础,作出了以下改进:① 骨干网络的改进,使用ResNeSt代替ResNet作为骨干网络;② 空洞空间金字塔池化模块的改进,首先在并联的每个分支的前一层增加一个空洞率相对较小的空洞卷积,其次在分支后层加入串联的空洞率逐渐减小的空洞卷积层。使用土地覆盖样本库和自制样本库进行模型训练、测试。结果表明,改进模型在2个数据集的精度和时间效率均明显优于原始DeepLabV3+模型:土地覆盖样本库总体精度达到88.08%,自制样本库总体精度达到85.22%,较原始DeepLabV3+模型分别提升了1.35%和3.4%,时间效率每epoch减少0.39 h。改进模型能够为数据量以每日TB级增加的高分影像提供更加快速精确的土地覆盖分类结果。
衡雪彪 , 许捍卫 , 唐璐 , 汤恒 , 许怡蕾 . 基于改进全卷积神经网络模型的土地覆盖分类方法研究[J]. 地球信息科学学报, 2023 , 25(3) : 495 -509 . DOI: 10.12082/dqxxkx.2023.220435
Remote sensing satellite data are essential source of earth surface information. However, traditional remote sensing classification methods usually have limitations and include cumbersome processes, and the accuracy of interpretation depends on the expert experience. Deep learning methods can adaptively extract more detailed feature information from field objects and are suitable for land cover classification of high-resolution remote sensing images. Based on the DeepLabV3+ model, this paper makes the following improvements: (1) Improvement of the backbone network. We use ResNeSt instead of ResNet as the backbone network; (2) The improvement of the hole space pyramid pooling module. First, a hole convolution with a relatively small hole rate is added to the previous layer of the parallel branch, and then a series of hole convolution layers with a gradually decreasing hole rate are added to the back layer of the branch. We use the land cover sample database and the self-made sample database respectively for model training and classify water bodies, transportation, buildings, cultivated land, grasslands, forests, bare soil, etc. from high-resolution images. Our results show that the accuracy and time efficiency of the improved model using the two databases are significantly higher than those of the original DeepLabV3+ model. The overall accuracy using the land cover sample database and self-made sample database reach 88.08% and 85.22%, respectively, which are 1.35% and 3.4% higher than that using the original DeepLabV3+ model, respectively. Also the time cost decreases by 0.39h per epoch. The improved model can provide faster and more accurate land cover classification results for high-resolution imageries that increases in terabytes of data per day.
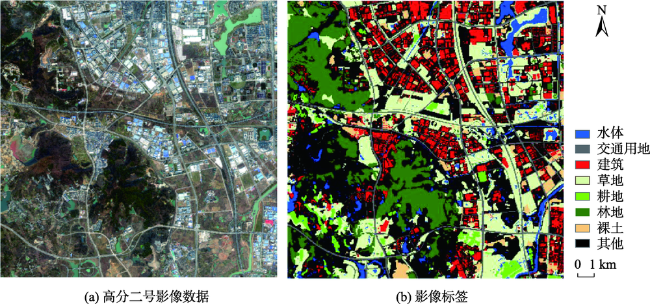
表1 土地覆盖分类系统Tab. 1 Land cover classification system |
| 一级大类 | 代码 | 二级小类 | 分类示例 |
|---|---|---|---|
| 水体 | 1 | 水体 | 河流、湖泊、水库、坑塘、沟渠、海洋 |
| 交通运输 | 道路 | 快速路、主干路、次干路、支路 | |
| 2 | 机场 | 飞行区、航站楼等 | |
| 火车站 | 火车站站台及候车厅 | ||
| 建筑 | 3 | 建筑物 | 住宅、工厂等人工建筑 |
| 耕地 | 4 | 普通耕地 | 普通耕地 |
| 农业大棚 | 耕地另一种形式,如温室 | ||
| 草地 | 5 | 自然草地 | 自然草地 |
| 绿地绿化 | 包括公园绿地、生态景观绿地、防护绿地等人工草地 | ||
| 林地 | 6 | 自然林 | 乔木林、灌木林 |
| 人工林 | 果园林、苗圃等 | ||
| 裸土 | 7 | 自然裸土 | 自然裸土、戈壁、沙漠 |
| 人为裸土 | 因建筑需求等原因破坏地表覆盖而造成裸土裸露的地表 | ||
| 其他 | 光伏 | 太阳能光伏发电板 | |
| 8 | 停车场 | 社会停车场用地、公共交通场站 | |
| 操场 | 篮球场、排球场、羽毛球场、网球场等 | ||
| 其他无法确定地物 | - |
表2 预实验精度评价Tab. 2 Pre-experimental precision evaluation (%) |
| DeepLabV3+ | U-Net | SegNet | |
|---|---|---|---|
| 水体 | 94.23 | 93.84 | 93.91 |
| 交通运输 | 82.47 | 80.26 | 80.53 |
| 建筑 | 90.39 | 87.13 | 87.70 |
| 耕地 | 84.09 | 81.37 | 81.76 |
| 草地 | 82.81 | 81.04 | 81.73 |
| 林地 | 91.18 | 89.65 | 89.03 |
| 裸土 | 83.94 | 82.17 | 82.33 |
| 其他 | 81.44 | 78.47 | 79.21 |
| OA | 86.73 | 84.76 | 85.68 |
| Kappa | 84.47 | 82.67 | 83.54 |
| F1-score | 86.39 | 84.65 | 85.42 |
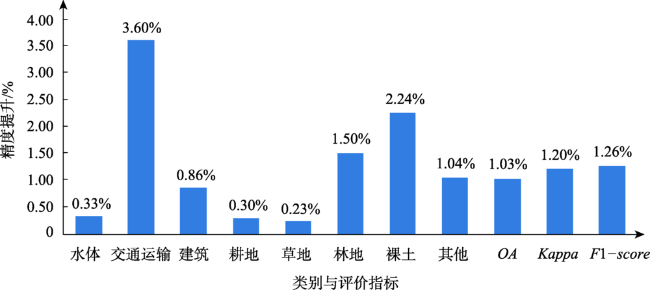
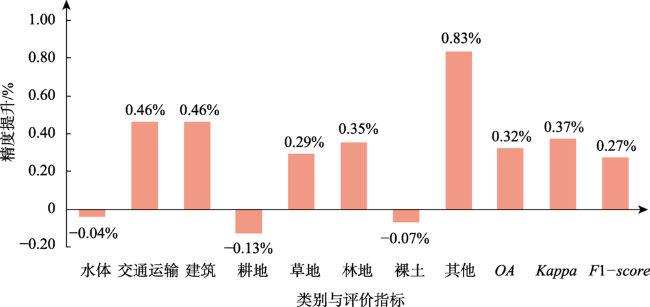
表3 验证集精度与效率评价Tab. 3 Verification set precision and efficiency evaluation (%) |
| D | D+R | D+R+A | |
|---|---|---|---|
| 水体 | 94.23 | 94.56 | 94.52 |
| 交通运输 | 82.47 | 86.07 | 86.53 |
| 建筑 | 90.39 | 91.25 | 91.70 |
| 耕地 | 84.09 | 84.39 | 84.26 |
| 草地 | 82.81 | 83.04 | 83.33 |
| 林地 | 91.18 | 92.68 | 93.03 |
| 裸土 | 83.94 | 86.17 | 86.10 |
| 其他 | 81.44 | 82.47 | 83.31 |
| OA | 86.73 | 87.76 | 88.08 |
| Kappa | 84.47 | 85.67 | 86.04 |
| F1-score | 86.39 | 87.65 | 87.92 |
| 平均每个epoch训练时间/h | 1.89 | 1.48 | 1.50 |
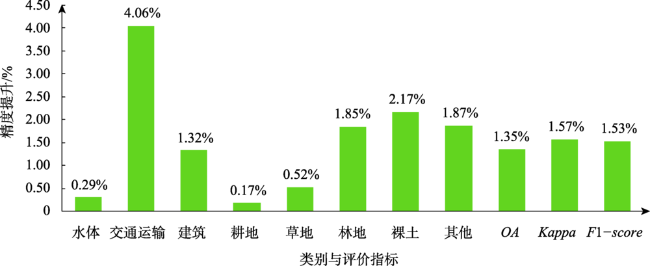
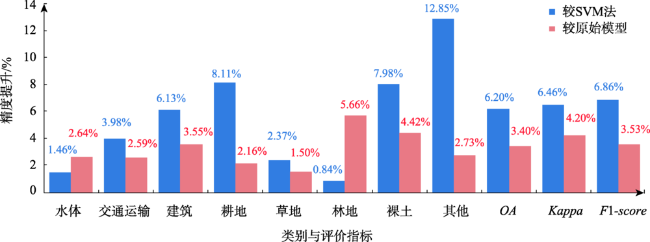
表4 测试结果精度评价Tab. 4 Test result precision evaluation (%) |
| SVM | DeepLabV3+ | 改进的DeepLabV3+ | |
|---|---|---|---|
| 水体 | 91.05 | 89.87 | 92.51 |
| 交通运输 | 80.79 | 82.18 | 84.77 |
| 建筑 | 83.05 | 85.63 | 89.18 |
| 耕地 | 75.44 | 81.39 | 83.55 |
| 草地 | 80.69 | 81.56 | 83.06 |
| 林地 | 86.96 | 82.14 | 87.80 |
| 裸土 | 77.82 | 81.38 | 85.80 |
| 其他 | 69.58 | 79.70 | 82.43 |
| OA | 79.02 | 81.82 | 85.22 |
| Kappa | 74.39 | 76.65 | 80.85 |
| F1-score | 80.25 | 83.58 | 87.11 |
| [1] |
刘纪远, 张增祥, 张树文, 等. 中国土地利用变化遥感研究的回顾与展望——基于陈述彭学术思想的引领[J]. 地球信息科学学报, 2020, 22(4):680-687.
[
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
周星宇, 张继贤, 高绵新, 等. 高分辨率遥感影像下沿海地区地表覆盖信息的提取[J]. 测绘通报, 2017(2):19-24.
[
|
| [9] |
|
| [10] |
|
| [11] |
刘浩, 骆剑承, 黄波, 等. 基于特征压缩激活Unet网络的建筑物提取[J]. 地球信息科学学报, 2019, 21(11):1779-1789.
[
|
| [12] |
李森, 彭玲, 胡媛, 等. 基于FD-RCF的高分辨率遥感影像耕地边缘检测[J]. 中国科学院大学学报, 2020, 37(4):483-489.
[
|
| [13] |
|
| [14] |
郭颖, 李增元, 陈尔学, 等. 一种改进的高空间分辨率遥感影像森林类型深度学习精细分类方法:双支FCN-8s[J]. 林业科学, 2020, 56(3):48-60.
[
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}