
基于局部-全局语义特征增强的遥感影像变化检测网络模型
|
高建文(1998—),男,安徽亳州人,硕士生,主要从事高分辨率遥感影像变化检测研究。E-mail: gaojw@nuist.edu.cn |
收稿日期: 2022-10-21
修回日期: 2022-12-11
网络出版日期: 2023-04-19
基金资助
国家自然科学基金项目(41971414)
国家自然科学基金项目(41801386)
江苏省2022年省级大学生创新创业训练计划(1514072201418)
Local-global Semantic Feature Enhancement Model for Remote Sensing Imagery Change Detection
Received date: 2022-10-21
Revised date: 2022-12-11
Online published: 2023-04-19
Supported by
National Natural Science Foundation of China(41971414)
National Natural Science Foundation of China(41801386)
Provincial College Students Innovation and Entrepreneurship Training Program of Jiangsu Province, 2022(1514072201418)
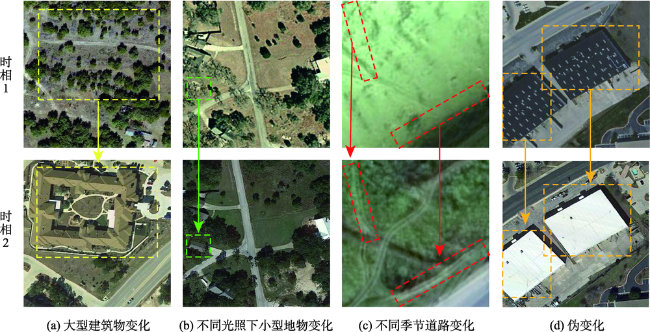
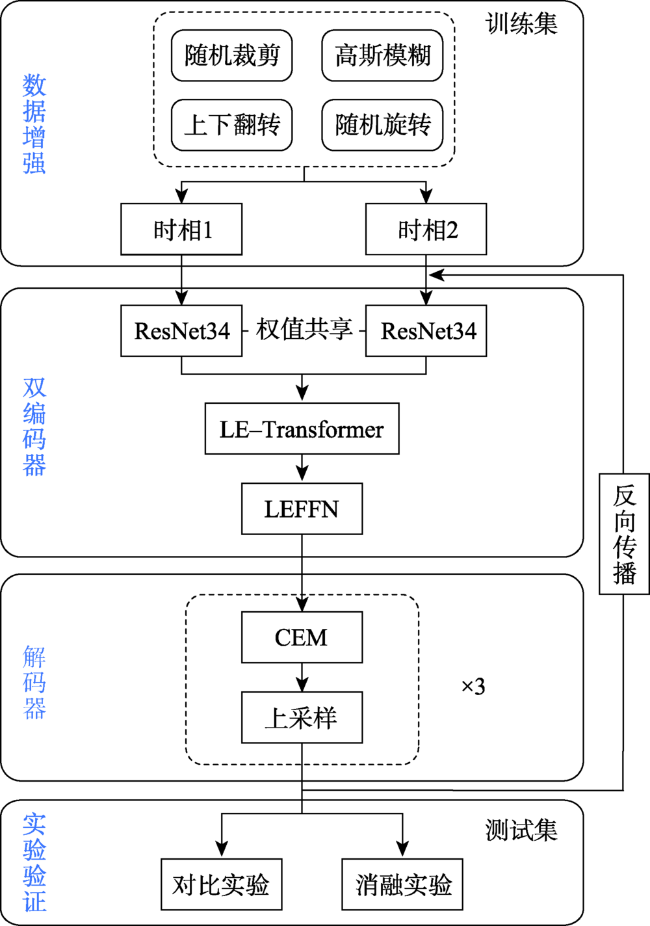
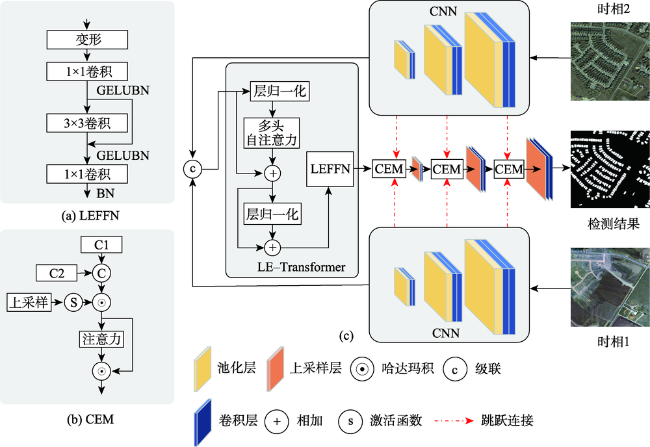
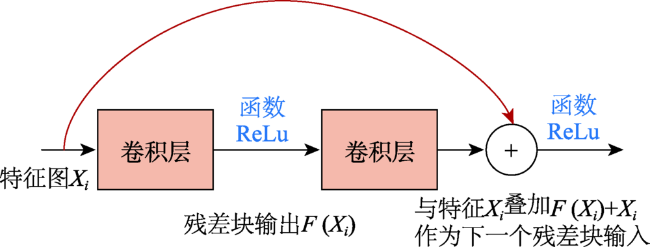
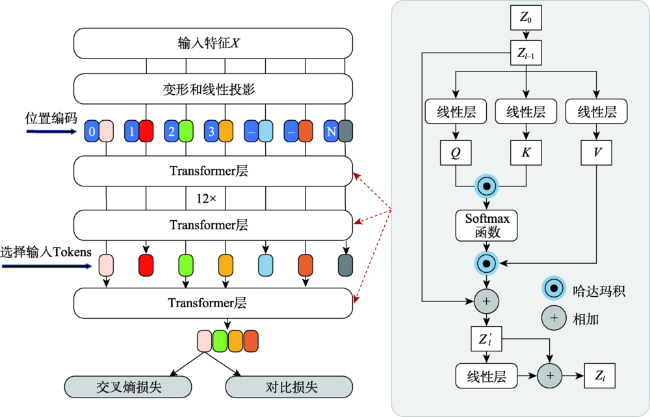
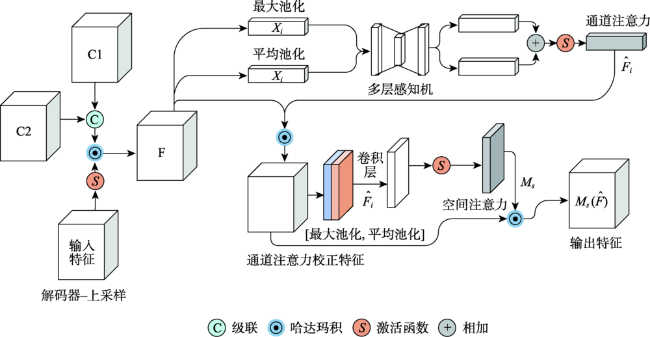
尽管卷积神经网络(Convolutional Neural Network, CNN)已广泛应用于遥感影像变化检测任务,但CNN感受野有限,难以有效提取全局语义信息。针对上述问题,本文提出一种用于变化检测任务的端到端局部-全局特征增强的编-解码网络模型(Local-Global Feature Enhancement Network,LGE-Net)。在编码部分,LGE-Net利用CNN_ResNet34骨干网络分别获得双时相遥感影像局部语义特征,级联后输入Locally Enhanced Transformer(LE-Transformer)结构捕获远距离语义依赖,提取深层全局语义特征。在解码部分,嵌入语义增强模块(Context Enhancement Module,CEM)连接解码特征与多尺度局部特征,实现变化对象的准确定位与分割。此外,针对LE-Transformer各分块内部以及相邻分块序列间缺乏局部信息交互问题,设计了局部特征增强前馈网络(Locally Enhanced Feed Forward Network,LEFFN)。在LEVIR-CD和CDD变化检测数据集上的综合对比试验表明,本文提出LGE-Net模型取得的F1-score分别达到91.06%和94.78%,显著优于其他对比模型,可更加精准识别变化区域,进一步减少误检以及漏检率,且具有良好的泛化能力。

高建文 , 管海燕 , 彭代锋 , 许正森 , 康健 , 季雅婷 , 翟若雪 . 基于局部-全局语义特征增强的遥感影像变化检测网络模型[J]. 地球信息科学学报, 2023 , 25(3) : 625 -637 . DOI: 10.12082/dqxxkx.2023.220809
Convolutional Neural Network (CNN) has achieved promising results in change detection using remote sensing images. However, CNN performs poorly on global semantic information extraction due to its limited receptive field. To this end, we propose an end-to-end encoding-decoding local-global feature enhancement network, termed as LGE-Net, which introduces locally enhanced Transformers (LE-Transformer) for capturing global semantic feature representation. Specifically, the LGE-Net uses the CNN backbone network to obtain local semantic features of dual-phase remote sensing images and cascades the extracted local features into the LE-Transformer layer to extract deep global semantic features. Then, in the decoder, the features are cascaded, up-sampled, and finally connected with multi-scale local features by semantic enhancement modules (CEMs). In addition, a local feature-enhanced feed-forward network (LEFFN) is designed to enhance local information interaction in the LE-Transformer blocks and their adjacent blocks. Extensive experiments on the two publicly available datasets (i.e., LEVIR-CD and CDD) show that the proposed LGE-Net can accurately and efficiently identify changed regions, reduce false and missed detections, and thus has a better generalization ability, compared to other state-of-the-art change detection methods.
表1 2个数据集上的变化检测性能Tab. 1 Changes detection accuracy on two datasets (%) |
| 模型 | LEVIR-CD | CDD | |||||||
|---|---|---|---|---|---|---|---|---|---|
| P | R | F1-score | IoU | P | R | F1-score | IoU | ||
| FC-EF | 87.57 | 78.14 | 82.58 | 70.34 | 76.28 | 71.01 | 73.55 | 58.17 | |
| STANet | 85.00 | 91.40 | 88.10 | 78.70 | 88.00 | 94.30 | 91.10 | 83.60 | |
| BIT | 90.50 | 89.42 | 89.96 | 81.75 | 95.15 | 92.41 | 93.76 | 88.25 | |
| UNet++_MSOF | 89.08 | 85.37 | 87.19 | 77.28 | 89.36 | 87.22 | 88.27 | 79.00 | |
| DSIFN | 93.30 | 86.21 | 89.61 | 81.18 | 88.09 | 96.22 | 91.97 | 85.14 | |
| ChangeFormer | 92.05 | 88.81 | 90.40 | 82.41 | 94.28 | 94.16 | 94.17 | 92.37 | |
| LGE-Net | 92.28 | 89.87 | 91.06 | 83.59 | 96.21 | 93.38 | 94.78 | 92.71 | |
注:黑色加粗数值表示性能最优。 |
表2 消融实验结果Table 2 Ablation experimental results |
| 模型 | LE-Transformer | CEM | LEFFN | P/% | R/% | F1-score/% | IoU/% |
|---|---|---|---|---|---|---|---|
| LGE-Net | √ | √ | √ | 92.28 | 89.87 | 91.06 | 83.59 |
| A | × | √ | √ | 92.46 | 89.32 | 90.87 | 83.26 |
| B | √ | × | √ | 92.21 | 89.56 | 90.87 | 83.27 |
| C | √ | √ | × | 91.80 | 89.92 | 90.85 | 83.24 |
注:√表示包含本模块,×表示不包含本模块。 |
| [1] |
|
| [2] |
|
| [3] |
张良培, 武辰. 多时相遥感影像变化检测的现状与展望[J]. 测绘学报, 2017, 46(10):1447-1459.
[
|
| [4] |
|
| [5] |
王铭佳, 黄亮. 利用指数熵的多时相遥感影像变化检测方法[J]. 遥感信息, 2017, 32(3):81-85.
[
|
| [6] |
季欣然, 黄亮, 陈朋弟. 结合变化向量分析和直觉模糊聚类的遥感影像变化检测方法[J]. 全球定位系统, 2020, 45(6):100-106.
[
|
| [7] |
|
| [8] |
|
| [9] |
梁哲恒, 黎宵, 邓鹏, 等. 融合多尺度特征注意力的遥感影像变化检测方法[J]. 测绘学报, 2022, 51(5):668-676.
[
|
| [10] |
|
| [11] |
任秋如, 杨文忠, 汪传建, 等. 遥感影像变化检测综述[J]. 计算机应用, 2021, 41(8):2294-2305.
[
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
刘博斐, 雒琛. 基于遥感数据的变化检测问题综述[J]. 电子技术与软件工程, 2021(5):160-164.
[
|
| [19] |
田青林, 秦凯, 陈俊, 等. 基于注意力金字塔网络的航空影像建筑物变化检测[J]. 光学学报, 2020, 40(21):47-56.
[
|
| [20] |
|
| [21] |
袁洲, 郭海涛, 卢俊, 等. 融合UNet++网络和注意力机制的高分辨率遥感影像变化检测算法[J]. 测绘科学技术学报, 2021, 38(2):155-159.
[
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
/
| 〈 |
|
〉 |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}