
面向路网匹配的层次化语义相似性度量模型
|
王玉竹(1989—),女,甘肃文县人,博士生,主要从事地图自动综合方面的研究。E-mail: lz_wangyuzhu@163.com |
收稿日期: 2022-11-20
修回日期: 2022-12-28
网络出版日期: 2023-04-19
基金资助
国家自然科学基金项目(41930101)
国家自然科学基金地区基金项目(42161066)
甘肃省高等学校产业支撑计划项目(2022CYZC-30)
Hierarchical Semantic Similarity Metric Model Oriented to Road Network Matching
Received date: 2022-11-20
Revised date: 2022-12-28
Online published: 2023-04-19
Supported by
National Natural Science Foundation of China(41930101)
Regional Fund of National Natural Science Foundation of China(42161066)
Industrial Support and Program Project of Universities in Gansu Province(2022CYZC-30)
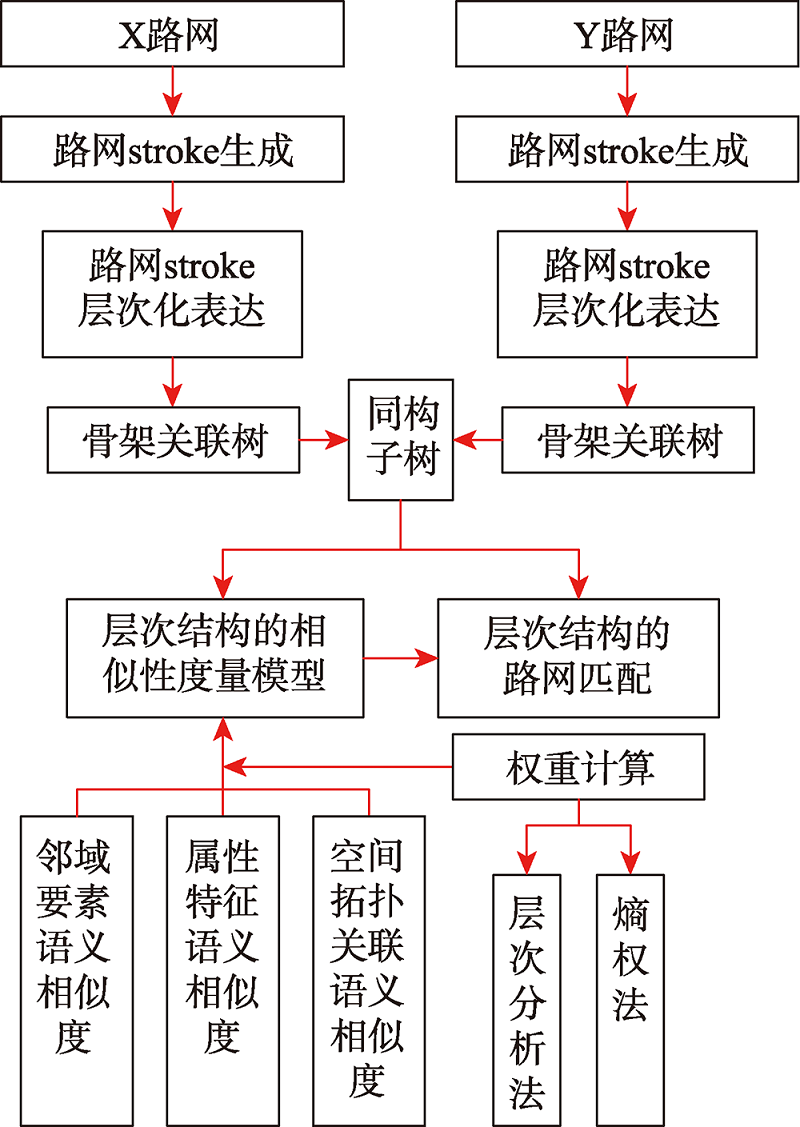
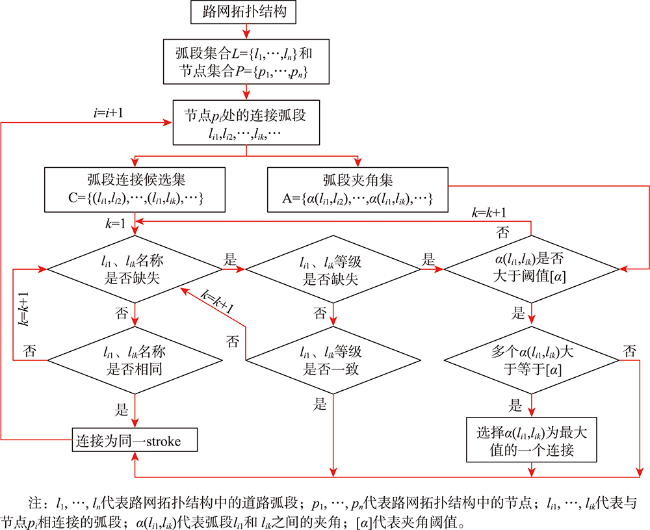
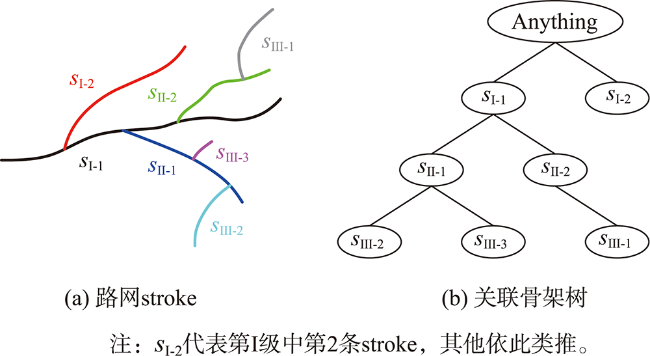
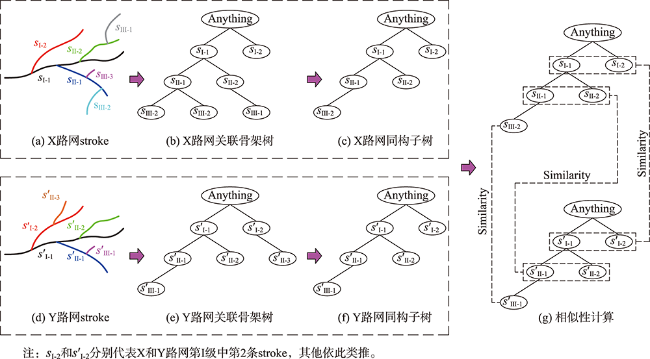
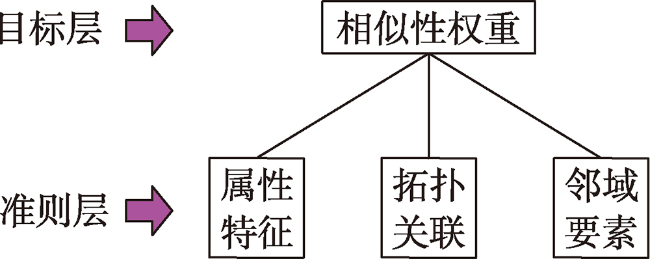
当前路网主要借助属性表中若干特征项的属性信息对其进行语义相似性评估,很少顾及到路网的分级层次结构、空间拓扑信息以及邻域要素信息,一定程度上影响着语义相似性评估结果的准确性。针对上述问题,本文提出一种“整体(骨架树)→部分(同构子树)→个体(stroke)”的路网层次化语义相似性度量模型,该模型顾及了路网属性特征项、上下级拓扑关联和邻域POI的语义信息,突破了传统模型仅以路网属性特征项的语义信息作为相似性评估指标的局限性。① 利用stroke技术表达路网,并对其进行分级;② 将路网数据映射到关联骨架树,进而建立考虑其层次性的路网相似性度量模型;③ 利用层次分析法和熵权法分别确定约束指标权值,并通过加权法计算路网的语义相似度。将该模型应用到路网匹配实验中,并与既有模型进行对比,结果表明利用本文提出的语义相似性度量模型,同时结合同构子树进行道路匹配,不仅可以提高匹配结果的准确性,而且可以提高匹配效率。对于文中案例所选的路网,拓扑关联语义信息对匹配结果的影响较邻域POI语义信息更显著,且与遍历法相比,以同构子树作为参照进行路网匹配,其匹配速率得到明显提升。
王玉竹 , 闫浩文 , 禄小敏 . 面向路网匹配的层次化语义相似性度量模型[J]. 地球信息科学学报, 2023 , 25(4) : 714 -725 . DOI: 10.12082/dqxxkx.2023.220901
The road network data have characteristics such as multiple sources and heterogeneity, which affect the data sharing and integrating to some extent. As a solution to deal with this problem, this study proposes a same-name road matching technology, which mainly depends on road similarity metric and its matching strategy. The semantic similarity is a more effective metric than geometric similarity, therefore it is of great theoretical value and practical significance to conduct road network matching based on semantic similarity metric. At present, the semantic similarity of road networks is mainly evaluated by the attribute information of some feature items in the attribute table, with little concern for the hierarchical structure of road network, spatial topology information, and neighborhood element information, which has limitation in the estimation accuracy of the semantic similarity results. To address the above problems, a hierarchical semantic similarity metric model named "whole (skeleton tree) → part (isomorphic subtree) → individual (stroke)" is proposed in this paper, in which the semantic information of attribute feature items, topological association of upper and lower classes, and POIs in the neighborhood of the road network is taken into account, thereby overcoming the limitation of the traditional model. Firstly, the road network is expressed using stroke technique and ranked hierarchically. Next, the road network data are mapped to the associated skeleton tree according to the hierarchical relationship between various classes of stroke, and then a road network similarity metric model is established considering the hierarchical nature. Finally, the weights of constraint indexs are determined using hierarchical analysis and entropy weighting method respectively, and the semantic similarity of the road network is calculated using the weighting method. The model proposed in this paper is verified in the road network matching experiments and compared with the existing iterative model. The results show that the proposed matching road network using the semantic similarity metric model combined with isomorphic sub-trees can not only improve the accuracy of matching results but also increase the matching efficiency. From the case study of the road network conducted in the paper, the topology association semantic information has a more significant impact on the matching results than that of neighborhood POI semantic information, and the matching efficiency is remarkably improved when using isomorphic subtrees as reference for road network matching compared with the iterative method.
表1 相似性判断矩阵Tab. 1 Similarity judgment matrix |
| M | Z1 | Z2 | Z3 |
|---|---|---|---|
| Z1 | 1 | 2 | 4 |
| Z2 | 1/2 | 1 | 3 |
| Z3 | 1/4 | 1/3 | 1 |
表2 1-10阶矩阵RI值Tab. 2 RI of 1-10th order matrix |
| 矩阵阶数 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| RI | 0 | 0 | 0.58 | 0.90 | 1.12 | 1.24 | 1.32 | 1.41 | 1.45 | 1.49 |
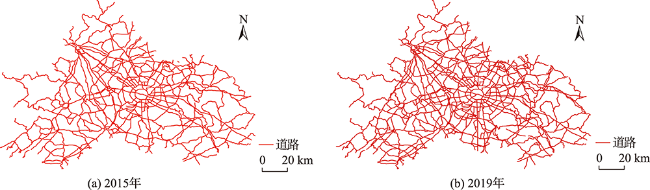
表3 提取stroke前后不同年份的路网数据统计信息对比Tab. 3 Comparison of statistical information of road network data with different years before and after extracting stroke |
| 年份 | 原数据 | Stroke处理后 | |||
|---|---|---|---|---|---|
| 弧段数量 | 节点数量/个 | 弧段数量 | 节点数量/个 | ||
| 2015 | 1050 | 1162 | 324 | 915 | |
| 2019 | 1737 | 1876 | 402 | 1623 | |
表4 语义相似性指标权值Tab. 4 Index weights of semantic similarity |
| 指标权重 | 年份 | 指标权重 | 年份 | ||
|---|---|---|---|---|---|
| 2015 | 2019 | 2015 | 2019 | ||
| wp | 0.562 | 0.562 | wp5 | 0.112 | 0.115 |
| wr | 0.321 | 0.321 | wp6 | 0.092 | 0.093 |
| wv | 0.117 | 0.117 | wp7 | 0.092 | 0.094 |
| wpc | 0.379 | 0.386 | wp8 | 0.041 | 0.037 |
| wpn | 0.361 | 0.371 | wp9 | 0.062 | 0.064 |
| wpg | 0.260 | 0.243 | wp10 | 0.062 | 0.057 |
| wp1 | 0.063 | 0.058 | wp11 | 0.062 | 0.063 |
| wp2 | 0.102 | 0.107 | wp12 | 0.098 | 0.093 |
| wp3 | 0.082 | 0.083 | wp13 | 0.057 | 0.059 |
| wp4 | 0.075 | 0.077 | |||
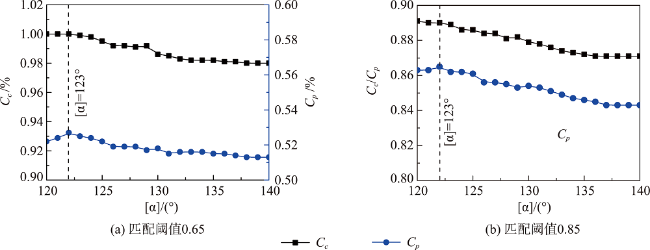
表5 不同匹配阈值下查全率和查准率Tab. 5 Recall ratio and precision ratio with different matching thresholds |
| 匹配阈值 | 语义相似性模型 | |||||||
|---|---|---|---|---|---|---|---|---|
| 文献[16] | 本文 | |||||||
| Cc | Cp | t/s | Cc | Cp | t/s | |||
| 0.65 | 1.00 | 0.37 | 42.15 | 1.00 | 0.52 | 21.35 | ||
| 0.70 | 0.92 | 0.54 | 1.00 | 0.69 | ||||
| 0.75 | 0.82 | 0.68 | 0.93 | 0.75 | ||||
| 0.80 | 0.74 | 0.80 | 0.89 | 0.86 | ||||
| 0.85 | 0.66 | 0.89 | 0.82 | 0.92 | ||||
| 0.90 | 0.62 | 0.94 | 0.76 | 0.99 | ||||
| 0.95 | 0.53 | 0.99 | 0.68 | 1.00 | ||||
| 1.00 | 0.48 | 1.00 | 0.56 | 1.00 | ||||
表6 各种方法的具体信息Tab. 6 Details of each method |
| 方法 | 相似度计算指标 | 匹配方法 |
|---|---|---|
| 方法1 | 属性特征语义 | 以同构子树为参照的层次匹配法 |
| 方法2 | 属性特征语义、邻域POI语义 | 以同构子树为参照的层次匹配法 |
| 方法3 | 属性特征语义、拓扑关联语义 | 以同构子树为参照的层次匹配法 |
| 方法4 | 属性特征语义、拓扑关联语义 | 遍历法 |
表7 各方法得到的查全率和查准率Tab. 7 Recall ratio and precision ratio obtained by each method |
| 匹配 阈值 | 方法1 | 方法2 | 方法3 | 方法4 | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Cc | Cp | t(s) | Cc | Cp | t(s) | Cc | Cp | t(s) | Cc | Cp | t(s) | ||||
| 0.65 | 1.00 | 0.38 | 14.14 | 1.00 | 0.39 | 18.42 | 1.00 | 0.44 | 16.76 | 1.00 | 0.41 | 152.41 | |||
| 0.70 | 0.93 | 0.54 | 0.96 | 0.56 | 0.98 | 0.61 | 0.97 | 0.58 | |||||||
| 0.75 | 0.84 | 0.69 | 0.91 | 0.69 | 0.94 | 0.72 | 0.92 | 0.72 | |||||||
| 0.80 | 0.78 | 0.80 | 0.83 | 0.82 | 0.88 | 0.83 | 0.86 | 0.80 | |||||||
| 0.85 | 0.66 | 0.88 | 0.76 | 0.90 | 0.81 | 0.91 | 0.80 | 0.88 | |||||||
| 0.90 | 0.63 | 0.95 | 0.71 | 0.96 | 0.72 | 0.97 | 0.71 | 0.91 | |||||||
| 0.95 | 0.56 | 0.98 | 0.64 | 0.99 | 0.69 | 1.00 | 0.67 | 0.98 | |||||||
| 1.00 | 0.48 | 1.00 | 0.50 | 1.00 | 0.51 | 1.00 | 0.48 | 1.00 | |||||||
| [1] |
杨敏, 艾廷华, 周启. 顾及道路目标stroke特征保持的路网自动综合方法[J]. 测绘学报, 2013, 42(4):581-587,594.
[
|
| [2] |
李琛强, 娄宁, 杨永崇, 等. 西安市路网时空演变与城市空间变化关系研究[J]. 测绘科学, 2021, 46(11):173-180,200.
[
|
| [3] |
王庆国, 张昆仑. 复杂网络理论的武汉市路网结构特征[J]. 测绘科学, 2019, 44(4):66-71.
[
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
刘闯, 钱海忠, 王骁, 等. 利用城市骨架线网的道路和居民地联动匹配方法[J]. 测绘学报, 2016, 45(12):1485-1494.
[
|
| [8] |
孙群. 空间数据相似性研究的若干基本问题[J]. 测绘科学技术学报, 2013, 30(5):439-442.
[
|
| [9] |
孙群. 多源矢量空间数据融合处理技术研究进展[J]. 测绘学报, 2017, 46(10):1627-1636.
[
|
| [10] |
陈万鹏, 崔虎平. 基于相似性度量的城市路网实体匹配算法[J]. 测绘与空间地理信息, 2018, 41(12):39-42,46.
[
|
| [11] |
刘闯, 钱海忠, 王骁, 等. 顾及上下级空间关系相似性的道路网联动匹配方法[J]. 测绘学报, 2016, 45(11):1371-1383.
[
|
| [12] |
邓红艳, 武芳, 王辉连, 等. 基于拓扑相似性的道路网综合模型[J]. 测绘科学技术学报, 2008, 25(3):183-187.
[
|
| [13] |
安晓亚, 孙群, 尉伯虎. 利用相似性度量的不同比例尺地图数据网状要素匹配算法[J]. 武汉大学学报(信息科学版), 2012, 37(2):224-228,241.
[
|
| [14] |
吴冰娇, 王中辉, 杨飞. 用于多尺度道路网匹配的语义相似性计算模型[J]. 测绘科学, 2022, 47(3):166-173.
[
|
| [15] |
谭永滨, 唐瑶, 李小龙, 等. 语义支持的地理要素属性相似性计算模型[J]. 遥感信息, 2017, 32(1):126-133.
[
|
| [16] |
赵云鹏, 孙群, 刘新贵, 等. 面向地理实体的语义相似性度量方法及其在道路匹配中的应用[J]. 武汉大学学报·信息科学版, 2020, 45(5):728-735.
[
|
| [17] |
翟仁健, 武芳, 黄博华, 等. 城市道路网面域层次结构特征的识别与表达[J]. 测绘科学技术学报, 2014, 31(4):413-418.
[
|
| [18] |
何海威, 钱海忠, 刘海龙, 等. 道路网层次骨架控制的道路选取方法[J]. 测绘学报, 2015, 44(4):453-461,470.
[
|
| [19] |
田晶, 何青松, 颜芬. 道路网stroke生成问题的形式化表达与新算法[J]. 武汉大学学报·信息科学版, 2014, 39(5):556-560.
[
|
| [20] |
|
| [21] |
|
| [22] |
罗国玮, 叶嘉媛, 王金凤. 基于多特征相似性的多源POI匹配方法[J]. 测绘通报, 2022(4):96-100.
[
|
| [23] |
郑业晴, 朱欣焰, 张发明, 等. 基于路网相似性的路段行程时间估计[J]. 计算机应用研究, 2018, 35(6):1681-1685.
[
|
| [24] |
张玲. POI的分类标准研究[J]. 测绘通报, 2012(10):82-84.
[
|
| [25] |
刘海龙, 钱海忠, 王骁, 等. 采用层次分析法的道路网整体匹配方法[J]. 武汉大学学报·信息科学版, 2015, 40(5):644-651.
[
|
| [26] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}