
面向遥感影像场景分类的类中心知识蒸馏方法
|
刘 潇(1999— ),女,山东临沂人,硕士生,主要从事遥感图像智能解译研究。 E-mail: liuxiao99919@163.com |
收稿日期: 2022-10-12
修回日期: 2023-01-28
网络出版日期: 2023-04-27
Class-centric Knowledge Distillation for RSI Scene Classification
Received date: 2022-10-12
Revised date: 2023-01-28
Online published: 2023-04-27
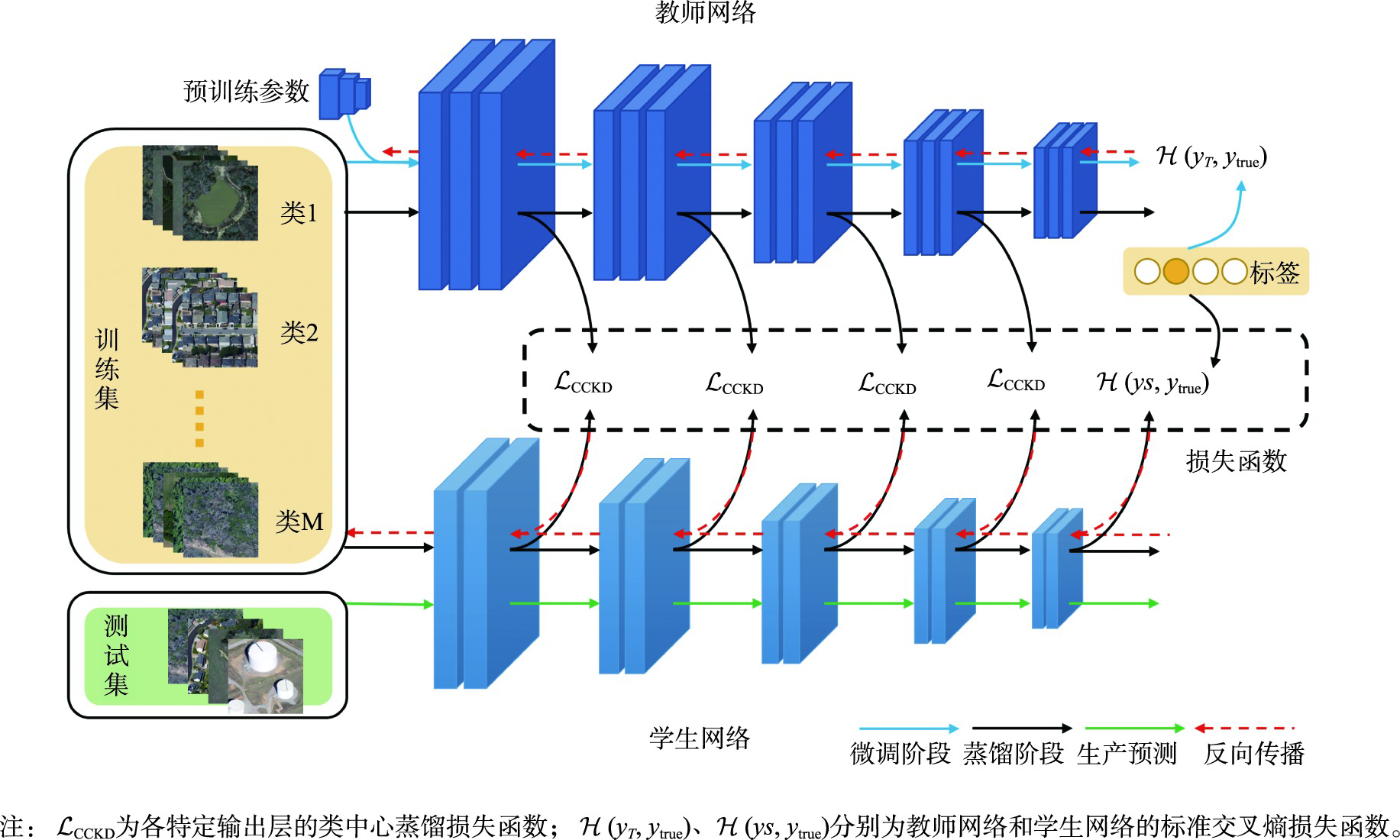
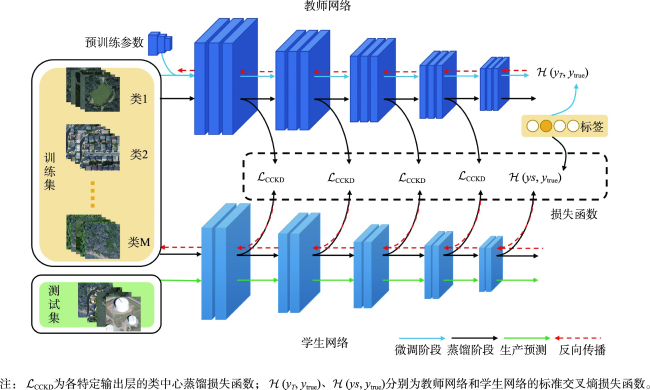
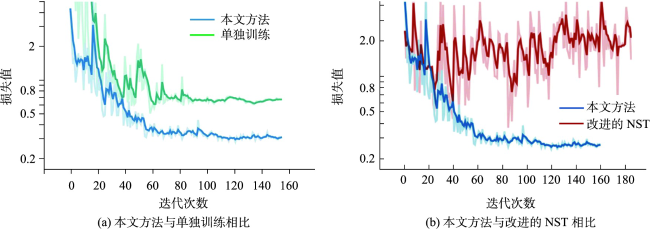
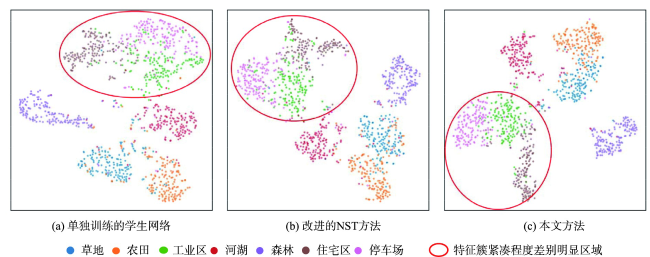
卷积神经网络已广泛应用于遥感影像场景分类任务,然而优秀的模型体量大,无法部署到资源受限的边缘设备中,直接应用现有的知识蒸馏方法压缩模型,忽略了场景数据的类内多样性和类间相似性。为此,本文提出一种类中心知识蒸馏方法,旨在获得一个紧凑高效且精度高的遥感影像场景分类网络。首先对预训练的教师网络进行微调,然后基于设计的类中心蒸馏损失将教师网络强大的特征提取能力迁移到学生网络,通过约束师生网络提取的同类特征分布中心的距离完成知识的转移,同时在蒸馏过程中结合真值标签训练,最后学生网络单独用于预测。实验在4个数据集上与8种先进的蒸馏方法在不同训练比率、不同师生架构下进行了比较,本文方法均达到最高分类精度。其中,在训练比率为60%的RSC11、UCM、RSSCN7及AID数据集中,相比于性能最好的其他蒸馏方法,师生网络属同系列时分类总体精度分别提升了2.42%、2.74%、2.95%和1.07%。相似技术对比实验及可视化分析进一步证明了本文方法优异的性能。本文所提出的类中心知识蒸馏方法更好地传递了复杂网络所提取的类内紧凑、类间离散的特征知识,提高了轻量网络分类的性能。
刘潇 , 刘智 , 林雨准 , 王淑香 , 左溪冰 . 面向遥感影像场景分类的类中心知识蒸馏方法[J]. 地球信息科学学报, 2023 , 25(5) : 1050 -1063 . DOI: 10.12082/dqxxkx.2023.220781
Convolutional neural networks have been widely used in the task of Remote Sensing Image Scene Classification (RSISC) and have achieved extraordinary performance. However, these excellent models have large volume and high computational cost, which cannot be deployed to resource-constrained edge devices. Moreover, in the RSISC task, the existing knowledge distillation method is directly applied to the compression model, ignoring the intra-class diversity and inter-class similarity of scene data. To this end, we propose a novel class-centric knowledge distillation method, which aims to obtain a compact, efficient, and accurate network model for RSISC. The proposed class-centric knowledge distillation framework for remote sensing image scene classification consists of two streams, teacher network flow and student network flow. Firstly, the remote sensing image scene classification dataset is sent into the teacher network pre-trained on a large-scale dataset to fine-tune the parameters. Then, the class-centric knowledge of the hidden layer is extracted from the adjusted teacher network and transferred to the student network based on the designed class center distillation loss, which is realized by constraining the distance of the distribution center of similar features extracted by the teacher and student network, so that the student network can learn the powerful feature extraction ability of the teacher network. The distillation process is combined with the truth tag supervision. Finally, the trained student network is used for scene prediction from remote sensing images alone. To evaluate the proposed method, we design a comparison experiment with eight advanced distillation methods on classical remote sensing image scene classification with different training ratios and different teacher-student architectures. Our results show that: compared to the best performance of other distillation methods, in the case of the teacher-student network belonging to the same series, the overall classification accuracy of our proposed method is increased by 1.429% and 2.74%, respectively, with a given training ratio of 80% and 60%; and in the case of teacher-student networks belonging to different series, the classification accuracy is increased by 0.238% and 0.476%, respectively, with the two given ratios. Additionally, supplementary experiments are also carried out on a small data set of RSC11 with few classes and few samples, a multi-scale data set of RSSCN7 with few classes and multiple books, and a large complex data set of AID with many classes of heterogeneous samples. The results show that the proposed method has good generalization ability. Trough the comparison experiments with similar techniques, it is found that the proposed method can maintain excellent performance in challenging categories through confusion matrix, and the proposed distillation loss function can better deal with noise through testing error curve. And visualization analysis also shows that the proposed method can effectively deal with the problems of intra-class diversity and inter-class similarity in remote sensing image scenes.
| 算法1 类中心知识蒸馏算法 |
|---|
| 第一阶段:微调教师网络 |
| 输入:教师网络模型 ,预训练参数,训练样本 |
| 计算标准交叉熵损失函数 |
| 反向传播更新 的参数,直到损失函数收敛 |
| 输出:教师网络模型 |
| 第二阶段:通过类中心蒸馏训练学生网络 |
| 输入:教师网络模型 ,学生网络模型 ,训练样本 |
| 初始化:学生网络参数 和超参数 |
| 按标签 整理训练集 每批次从随机类中 抽取随机的样本 |
| 根据式(7)计算总体损失函数 |
| 反向传播更新学生网络的参数 ,直到损失函数收敛 |
| 输出:学生网络模型 ,参数 |
| 第三阶段:测试学生网络 |
| 输入:学生网络模型 ,测试样本 |
| 输出:预测结果 |
| 按标签 整理训练集 每批次从随机类中 抽取随机的样本 |
表1 遥感影像场景分类数据集Tab. 1 Remote sensing image scene classification dataset |
| 数据集 | 分辨率/m | 类别数/个 | 尺寸/mm | 每类样本数/个 | 样本总数/个 | 特点 |
|---|---|---|---|---|---|---|
| RSC11 | 0.2 | 11 | 512 × 512 | 约100 | 1232 | 小型的遥感影像场景分类数据集 |
| UCM | 0.3 | 21 | 256 × 256 | 100 | 2100 | 经典的高分辨率土地利用数据集 |
| RSSCN7 | - | 7 | 400 × 400 | 400 | 2800 | 涵盖4个采样尺度的, 类内多样性大的场景分类数据集 |
| AID | 0.5~0.8 | 30 | 600 × 600 | 200~400 | 10000 | 复杂的多源、多分辨率、类间相似性高、样本不均衡的航空图像数据集 |
表2 师生网络结构及输出层特征信息Tab. 2 Network structure of T/S models and Information about the features of the output layer |
| 网络名称 | ResNet50 | ResNet18 | MobileNetV2 |
|---|---|---|---|
| 卷积池化层 | |||
| 卷积层1 | |||
| 输出层特征1 | |||
| 卷积层2 | |||
| 输出层特征2 | |||
| 卷积层3 | |||
| 输出层特征3 | |||
| 卷积层4 | |||
| 输出层特征4 | |||
| 全局池化层 |
注:F表示设计蒸馏网络中间输出层的特征图; 表示特征图尺寸为 ,通道数为 。 |
表3 UCM数据集上各种知识蒸馏方法的总体精度Tab. 3 Overall accuracy of various knowledge distillation methods on UCM dataset (%) |
| 蒸馏方法 | 师生架构 (Model T/S) | 同系列 (ResNet-50/ ResNet-18) | 不同系列 (ResNet-50/MobileNet-V2) | ||
|---|---|---|---|---|---|
| 训练比率 | 80% | 60% | 80% | 60% | |
| Baseline | 92.14 | 90.00 | 91.43 | 90.48 | |
| 响应 | KD | 95.48 | 92.38 | 93.33 | 90.24 |
| DKD | 95.71 | 91.91 | 94.52 | 92.14 | |
| 特征 | NST | 94.05 | 91.67 | 92.62 | 90.48 |
| VID | 93.57 | 89.41 | 92.38 | 89.05 | |
| 网络层间关系 | KDSVD | 92.62 | 90.36 | 92.62 | 89.88 |
| ReviewKD | 94.29 | 92.62 | 94.29 | 91.07 | |
| 实例关系 | RKD | 94.52 | 92.02 | 92.38 | 87.38 |
| SP | 93.33 | 91.43 | 80.48 | 59.05 | |
| 类中心 | 本文方法 | 97.14 | 95.36 | 94.76 | 92.62 |
注:Baseline是指单独训练学生网络的结果。在所有方法中精度最高的结果表示为粗体,次高的表示为下划线。结果取10次实验平均值。 |
表4 网络模型尺寸对比Tab. 4 Comparison of model size |
| 模型 | FLOPs (G) | Parameters (M) | 压缩率/% |
|---|---|---|---|
| ResNet50 | 32.88 | 23.55 | |
| ResNet18 | 14.55 | 11.19 | 47.52 |
| MobileNetV2 | 2.50 | 2.25 | 9.55 |
表5 多个数据集在60%训练比率及同构师生网络条件下的总体精度Tab. 5 Overall accuracy on multiple datasets with 60% training ratio and homogeneous T/S network (%) |
| 数据集 | 教师网络 | 学生网络 | 响应 | 特征 | 网络层间关系 | 实例关系 | 类中心 | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| KD | DKD | NST | VID | KDSVD | ReviewKD | RKD | SP | 本文方法 | |||
| RS_C11 | 92.35 | 90.14 | 91.95 | 90.95 | 89.74 | 88.13 | 87.73 | 90.34 | 89.74 | 87.73 | 94.37 |
| RSSCN7 | 91.07 | 88.75 | 88.30 | 87.32 | 87.59 | 87.41 | 87.05 | 88.21 | 88.75 | 86.52 | 91.70 |
| AID | 95.68 | 88.98 | 92.73 | 93.03 | 91.43 | 88.96 | 89.20 | 92.58 | 91.45 | 91.65 | 94.10 |
注:教师网络为ResNet-50,展示的是经预训练-微调后的分类结果,学生网络为ResNet-18,表示的是不经蒸馏单独训练的结果。在所有方法中精度最高的结果表示为粗体,次高的表示为下划线,斜体粗体意味着超过教师分类精度。结果取10次实验平均值。 |
表6 RSC11数据集上对比实验的结果Tab.6 Results of comparative experiments on RSC11 Dataset (%) |
| Student | Teacher | NST | NST_all | 本文方法 | 较次高 提升精度 | |
|---|---|---|---|---|---|---|
| 总体精度 | 90.14 | 92.35 | 89.74 | 92.56 | 94.37 | 1.81 |
注:精度最高的结果表示为粗体,次高的表示为下划线 |
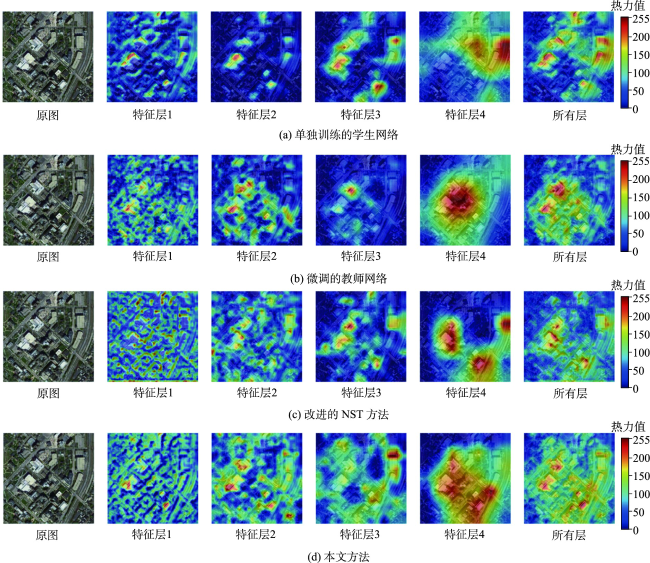
表7 对比实验在RSC11数据集上的精度混淆矩阵Tab. 7 Accuracy confusion matrix of comparison experiment on RSC11 Dataset (%) |
| 单独训练的学生网络 | 微调的教师网络 | ||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 密林 | 草地 | 港口 | 高建筑 | 低建筑 | 立交 | 铁路 | 居民区 | 公路 | 疏林 | 储存罐 | 密林 | 草地 | 港口 | 高建筑 | 低建筑 | 立交 | 铁路 | 居民区 | 公路 | 疏林 | 储存罐 | ||
| 密林 | 98.21 | 1.79 | 密林 | 100 | |||||||||||||||||||
| 草地 | 100 | 草地 | 100 | ||||||||||||||||||||
| 港口 | 97.22 | 2.78 | 港口 | 100 | |||||||||||||||||||
| 高建筑 | 91.11 | 2.22 | 2.22 | 4.44 | 高建筑 | 97.62 | 2.38 | ||||||||||||||||
| 低建筑 | 85.42 | 6.25 | 8.33 | 地建筑 | 91.67 | 4.17 | 2.08 | 2.08 | |||||||||||||||
| 立交 | 2.33 | 74.42 | 2.33 | 18.6 | 2.33 | 立交 | 2.27 | 68.18 | 9.09 | 20.45 | |||||||||||||
| 铁路 | 3.12 | 3.12 | 87.5 | 6.25 | 铁路 | 8.00 | 88.00 | 4.00 | |||||||||||||||
| 居民区 | 1.61 | 1.61 | 87.1 | 4.84 | 4.84 | 居民区 | 1.79 | 98.21 | |||||||||||||||
| 公路 | 1.89 | 1.89 | 9.43 | 3.77 | 83.02 | 公路 | 3.28 | 13.11 | 8.20 | 75.41 | |||||||||||||
| 疏林 | 2.17 | 97.83 | 疏林 | 100 | |||||||||||||||||||
| 储存罐 | 5.71 | 2.86 | 91.43 | 储存罐 | 100 | ||||||||||||||||||
| 基于改进NST方法训练的学生网络 | 基于本文方法训练的学生网络 | ||||||||||||||||||||||
| 密林 | 草地 | 港口 | 高建筑 | 低建筑 | 立交 | 铁路 | 居民区 | 公路 | 疏林 | 储存罐 | 密林 | 草地 | 港口 | 高建筑 | 低建筑 | 立交 | 铁路 | 居民区 | 公路 | 疏林 | 储存罐 | ||
| 密林 | 100 | 密林 | 100 | ||||||||||||||||||||
| 草地 | 100 | 草地 | 100 | ||||||||||||||||||||
| 港口 | 92.31 | 2.56 | 5.13 | 港口 | 100 | ||||||||||||||||||
| 高建筑 | 90.91 | 4.55 | 2.27 | 2.27 | 高建筑 | 97.73 | 2.27 | ||||||||||||||||
| 地建筑 | 2.50 | 95.00 | 2.5 | 低建筑 | 95.24 | 2.38 | 2.38 | ||||||||||||||||
| 立交 | 89.19 | 5.41 | 5.41 | 立交 | 86.11 | 5.56 | 2.78 | 5.56 | |||||||||||||||
| 铁路 | 3.12 | 3.12 | 87.5 | 3.12 | 3.12 | 铁路 | 3.33 | 6.67 | 90.00 | ||||||||||||||
| 居民区 | 1.67 | 91.67 | 3.33 | 3.33 | 居民区 | 1.69 | 1.69 | 1.69 | 93.22 | 1.69 | |||||||||||||
| 公路 | 14.75 | 3.28 | 81.97 | 公路 | 15.15 | 3.03 | 81.82 | ||||||||||||||||
| 疏林 | 2.17 | 97.83 | 疏林 | 100 | |||||||||||||||||||
| 储存罐 | 7.14 | 92.86 | 储存罐 | 2.33 | 97.67 | ||||||||||||||||||
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
郭子慧, 刘伟. 深度学习和遥感影像支持的矢量图斑地类解译真实性检查方法[J]. 地球信息科学学报, 2020, 22(10):2051-2061.
[
|
| [9] |
余东行, 张保明, 赵传, 等. 联合卷积神经网络与集成学习的遥感影像场景分类[J]. 遥感学报, 2020, 24(6):717-727.
[
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
彭瑞, 赵文智, 张立强, 等. 基于多尺度对比学习的弱监督遥感场景分类[J]. 地球信息科学学报, 2022, 24(7):1375-1390.
[
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
杨宏炳, 迟勇欣, 王金光. 基于剪枝网络的知识蒸馏对遥感卫星图像分类方法[J]. 计算机应用研究, 2021, 38(8):2469-2473.
[
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
Maaten L van der and Hinton G. Visualizing data using t-sne[J]. Journal of Machine Learning Research, 2008, 9(86):2579-2605.
|
| [48] |
|
/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}