
网络文本蕴含地理信息质量评估框架
|
黄宗财(1992— ),男,江西兴国人,博士生,主要研究方向为地理信息抽取、地理知识图谱和旅游知识图谱。E-mail: huangzc@lreis.ac.cn |
收稿日期: 2022-08-22
修回日期: 2022-10-09
网络出版日期: 2023-06-02
基金资助
国家重点研发计划项目(2022YFB3904202)
国家自然科学基金项目(41631177)
国家自然科学基金项目(42001391)
A Quality Assessment Framework for Implicit Geographic Information from Web Texts
Received date: 2022-08-22
Revised date: 2022-10-09
Online published: 2023-06-02
Supported by
National Key Research and Development Program(2022YFB3904202)
National Natural Science Foundation of China(41631177)
National Natural Science Foundation of China(42001391)
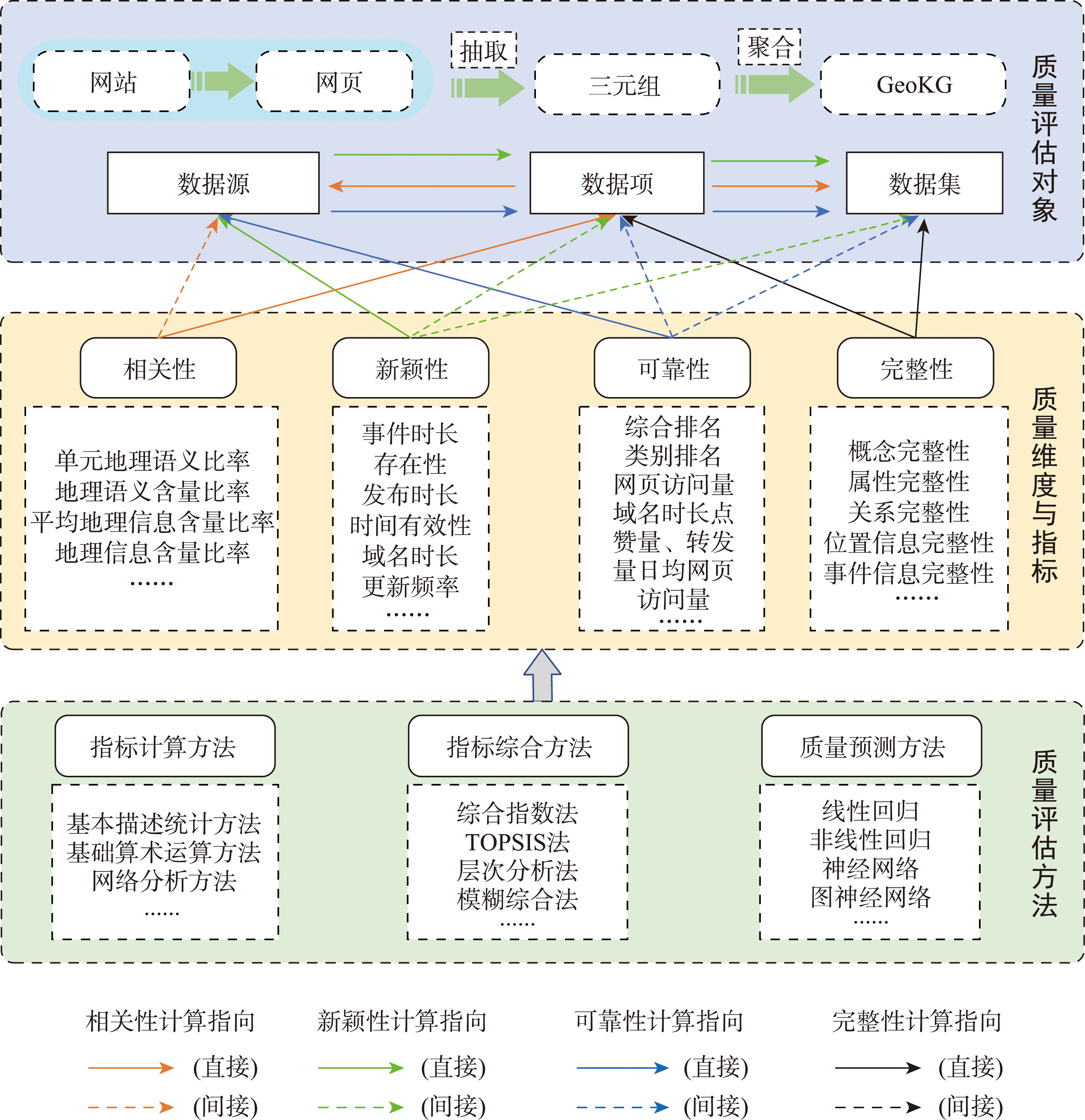
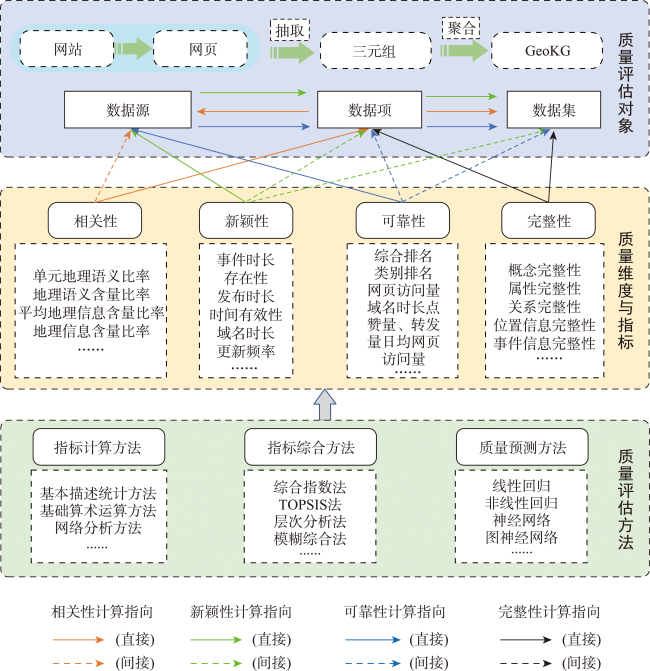
网络文本是构建和填补大规模地理知识图谱的重要地理信息来源。但网络文本来源广泛、动态性强、表达方式复杂多样、蕴含地理信息良莠不齐,网络文本蕴含地理信息质量评估面临评估对象多层次、质量维度不明确、评估指标多元化、深层次指标难获取和评估方法多样化的挑战。因此,本文提出了一种网络文本蕴含地理信息质量评估框架(QAF-GIWT)。QAF-GIWT面向网络文本获取地理信息过程,明确了数据源、数据项和数据集3层质量评估对象,针对不同层次评估对象定义了包含相关性、新颖性、可靠性和完整性4个质量维度和相应的量化评估指标,系统地梳理了质量评估过程中所涉及指标计算、指标综合和质量预测方法的特点及其适用性。其中,借助自然语言处理技术及相应的指标计算方法,构建了包含单元地理语义比率、地理语义含量比率、平均地理信息含量比率和地理信息含量比率、地理实体比率、窗口地理信息含量比率等指标。实验中针对马蜂窝等类型网站特性设计了QAF-GIWT框架,针对多层次质量指标的综合评估,采用了层次分析法进行可靠性综合评估,应用实验案例验证了QAF-GIWT框架的有效性。QAF-GIWT提供了一整套囊括质量维度、质量指标和质量评估方法的方案,可辅助进行海量异构动态的网络文本数据源的筛选和从中获取地理信息的过滤,大幅度减小信息获取的复杂度,降低数据存储冗余度。
黄宗财 , 陆锋 , 仇培元 , 彭澎 . 网络文本蕴含地理信息质量评估框架[J]. 地球信息科学学报, 2023 , 25(6) : 1121 -1134 . DOI: 10.12082/dqxxkx.2023.220617
Web texts are an important data source for constructing and completing a large-scale knowledge graph that contains a great deal of ubiquitous geographic information. However, the extensive sources, casual expression, and dynamic nature of web texts, as well as the varied quality of implicit geo-information bring great challenges such as multi-level evaluation objects, unclear quality dimensions, diversified evaluation indicators, difficult access to deep-seated indicators, and diversified evaluation methods in the process of geographic information quality assessment. Therefore, a Quality Assessment Framework for implicit Geographic Information from Web Texts (QAF-GIWT) is proposed in this study. The QAF-GIWT is oriented to the process of acquiring geographic information from web texts and defines three levels of quality evaluation objects, i.e., data source level, data item level, and dataset level. The data source level contains websites and web pages, the data item level includes the triplet-formed information extracted from the webpage, and the dataset level is the information aggregated into a Geographic Knowledge Graph (GeoKG). The QAF-GIWT defines four quality dimensions including relevance, novelty, reliability, and integrity, and proposes the corresponding quantitative evaluation indicators for different level evaluation objects including Cell Geographic Semantic Ratio (CGSR), Geographic Semantic Ratio (GSR), Average Geographic Information Ratio (AGIR), Geographic Information Ratio(GIR), Event Time Length, Triplet Existence, Publish Time, Time Validation, Domain Name Time Length, Update Frequency, Average Freshness, Comprehensive Ranking, Category Ranking, Daily Page Visit, Daily User Visit, User Attention, Picture Number, Word Number, Geographic Entities Ratio (GER), Window's Geo-Information Ratio (GIWR), Triplet Missing Rate, Event Information Missing Rate, Relation Missing Rate, Attribute Missing Rate, Location Missing Rate, Relation Redundancy, Attribute Redundancy, etc. It systematically summarizes the characteristics and applicability of the indicator calculation, indicator synthesis, and quality prediction methods involved in the quality evaluation process. Among them, with the help of natural language processing technology and corresponding quality indicator calculation methods, quality indicators are newly constructed from the deep mining of the web texts including CGSR, GSR, AVGIR, GIR, GIWR, GER, etc. In our experiment, the QAF-GIWT framework was designed to adapt to the characteristics of various types of websites e.g., Mafengwo. Aiming at the comprehensive evaluation of multi-level quality indicators, the analytic hierarchy process was used for comprehensive reliability evaluation. Our experiment verified the effectiveness of the QAF-GIWT framework. The QAF-GIWT provides a systematic scheme including quality dimensions, quality indicators, and quality assessment methods for the quality evaluation of geographic information extracted from massive, heterogeneous, and dynamic web texts. The proposed QAF-GIWT can assist in the screening of data sources and filtering of acquired information, greatly reducing the complexity of information acquisition and the redundancy of data storage, and assisting the quality control process of the acquisition of geographic information from web texts.
表1 蕴含地理信息的网站分类Tab. 1 Classification of websites containing geographical information |
| 类别 | 案例 | 网站特征 | 获取地理信息 | 质量要求排序 |
|---|---|---|---|---|
| 百科网站 | 维基百科、百度百科 | 数据量大,志愿者贡献并多人编辑审核,可信度较高 | 地理知识 | 准确性、完整性、覆盖范围、可靠性 |
| 社交网站 | 新浪微博、推特 | 更新快,数据量大,内容差异较大 | 地理事件信息 | 新颖性、可靠性、准确性、易使用性 |
| 新闻网站 | 人民网、腾讯新闻网、凤凰新闻 | 更新快,真实性高 | 地理事件信息 | 准确性、权威性、可靠性、新颖性 |
| 数据网站 | 资源环境科学数据中心、国家地球系统科学数据共享服务平台 | 数据量大,提供数据说明、数据检索和下载 | 地理数据信息 | 适用性、覆盖范围、可靠性、准确性、新颖性、可获得性 |
| 行业网站 | 马蜂窝、携程 | 聚焦业务内容,包含公司和用户内容 | 领域地理信息 | 可靠性、准确性、新颖性 |
| 企业网站 | 超图、易智瑞 | 提供公司介绍与位置信息 | 公司信息 | 可靠性、准确性、相关性、新颖性 |
| 政府网站 | 中国测绘局、中国统计局 | 提供各种测绘与地理方面规范与政策 | 政策信息 | 权威性、新颖性、准确性 |
| 论坛网站 | 地信网论坛 | 志愿者发布资源供用户阅读与下载 | 地理资料信息 | 覆盖范围、适用性、可获得性、可靠性、准确性 |
表2 QAF-GIWT中新颖性的维度、指标与值获取方式Tab. 2 Dimension, index and value acquisition method of freshness in QAF-GIWT |
| 维度 | 层次 | 指标 | 计算方式 | 公式编号 |
|---|---|---|---|---|
| 新颖性 | 数据项(三元组) | 事件时长 | 事件时长=当前时间-事件发生时间 | (5) |
| 存在性 | 存在性= | (6) | ||
| 数据源(网页) | 发布时长 | 发布时长=当前时间-网页发布时间 | (7) | |
| 时间有效性 | 时间有效性=当前时间-有效期限时间 | (8) | ||
| 数据源(网站) | 域名时长 | 域名时长=当前时间-域名创建时间 | (9) | |
| 更新频率 | 更新频率=年度网页总更新数量/365 | (10) | ||
| 数据集(GeoKG) | 平均新颖度 | 平均新颖度=总新颖度/三元组数量 | (11) |
表3 QAF-GIWT中可靠性的维度、指标与值获取方式Tab. 3 Dimensions, indicators and value acquisition methods of reliability in QAF-GIWT |
| 维度 | 层次 | 指标 | 值获取方式 | 公式编号 |
|---|---|---|---|---|
| 可靠性 | 数据源(网站) | 综合排名 | API直接获取 | |
| 类别排名 | API直接获取 | |||
| 日均网页访问量 | API直接获取 | |||
| 日均用户访问量 | API直接获取 | |||
| 域名时长 | 域名时长=当前时间-域名创建时间 | |||
| 数据源(网页) | 用户关注数量 | 爬取 | ||
| 网页的点赞数、转载数、阅读数、评论数、收藏数 | 爬取 | |||
| 文字数量、图片数量 | 计算 | |||
| 数据项(三元组) | 地理实体比率 | (12) | ||
| 窗口地理信息含量比率 | (13) | |||
| 数据集(GeoKG) | 平均可靠性 | 平均可靠性=可靠性总和/数据项数量 | (14) |
表4 QAF-GIWT中完整性的维度、指标与值获取方式Tab. 4 Dimensions, indicators and value acquisition methods of completeness in QAF-GIWT |
| 维度 | 层次 | 指标 | 值获取方式 | 公式编号 |
|---|---|---|---|---|
| 完整性 | 数据项(三元组) | 元素缺失率 | 元素缺失率=缺失三元组元素数量/3 | (15) |
| 数据项(地理事件) | 事件元素缺失率 | 事件元素缺失率=缺失事件元素数量/事件元素总数量 | (16) | |
| 数据项(地理实体) | 关系缺失率 | 关系缺失率=缺失关系数量/关系总数量 | (17) | |
| 属性缺失率 | 属性缺失率=缺失属性数量/属性总数量 | (18) | ||
| 位置信息缺失率 | 缺失为1,存在为0 | |||
| 关系冗余率 | 关系冗余率=冗余关系数量/关系总数量 | (19) | ||
| 属性冗余率 | 属性缺失率=冗余属性数量/属性总数量 | (20) | ||
| 数据集(GeoKG) | 总缺失率 | 总缺失率=(关系缺失数量+属性缺失数量+事件元素缺失率+位置信息缺失数量)/数据项总数 | (21) |
表5 网络文本蕴含地理信息质量评估方法Tab. 5 Quality evaluation method of geographic information from web texts |
| 评估对象层次 | 质量维度 | 评估方法 | 公式编号 | 方法类型 |
|---|---|---|---|---|
| 数据项 (三元组) | 相关性 | 单元地理语义比率 | 指标计算法 | |
| 可靠性 | 层次分析法 | (22) | 指标综合法 | |
| 新颖性 | 存在性×(事件时长+发布时长+时间有效+域名时长+更新频率)/5 | (23) | 指标综合法 | |
| 完整性 | (元素缺失率+事件元素缺失率+关系缺失率+属性缺失率+位置信息缺失率)/5 | (24) | 指标综合法 | |
| 数据源 (网页) | 相关性 | 地理语义含量比率 | 指标计算法 | |
| 可靠性 | (用户关注数量+点赞数量+文字数量+图片数量)/4 | (25) | 指标综合法 | |
| 新颖性 | (发布时长+时间有效+域名时长+更新频率)/4 | (26) | 指标综合法 | |
| 完整性 | - | - | ||
| 数据源 (网站) | 相关性 | 平均地理语义含量比率 | 指标计算法 | |
| 可靠性 | (综合排名+类别排名+日均网页访问量+日均用户访问量+域名时长)/5 | (27) | 指标综合法 | |
| 新颖性 | (域名时长+更新频率)/4 | (28) | 指标综合法 | |
| 完整性 | - | - | ||
| 数据集 (GeoKG) | 相关性 | (地理信息含量比率+总缺失率)/2 | (29) | 指标综合法 |
| 可靠性 | 平均可靠性 | 指标综合法 | ||
| 新颖性 | 平均新颖度 | 指标综合法 | ||
| 完整性 | 总缺失率 | 指标综合法 |
注:评估方法涉及的所有指标均经过归一化和同趋势化处理。 |
表6 可靠性计算中各层指标权重Tab. 6 Index weight of each layer in reliability calculation |
| 权重名称 | 指标权重 | 权重名称 | 指标权重 |
|---|---|---|---|
| (综合排名) | 0.092 4 | (网页点赞数) | 0.034 5 |
| (类别排名) | 0.132 5 | (文字数量) | 0.011 5 |
| (日均网页访问量) | 0.013 3 | (图片数量) | 0.005 6 |
| (日均用户访问量) | 0.022 8 | (地理实体比率) | 0.290 6 |
| (域名时长) | 0.048 2 | (窗口地理信息含量比率) | 0.290 6 |
| (用户关注数量) | 0.058 0 |
表7 网络文本蕴含地理信息质量评估案例结果Tab. 7 The cases of quality evaluation results of geographic information from web texts |
| 数据项(三元组) | 相关性 | 新颖性 | 可靠性 | 完整性 | ||
|---|---|---|---|---|---|---|
| h | r | t | ||||
| 五塔寺 | 地处 | 北京海淀区白石桥北 | 1 | 0.586 9 | 0.732 9 | 1 |
| 大北照相馆 | 始建 | 1921年 | 1 | 0.361 3 | 0.647 4 | 1 |
| 正兴德茶庄 | 号称 | “清真茶叶第一庄” | 1 | 0.361 3 | 0.645 9 | 1 |
| 交通银行旧址 | 位于 | 前门西河沿街9号 | 1 | 0.361 3 | 0.662 4 | 1 |
| 世贸天阶 | 算是 | 不错的地方 | 0.068 5 | 0.448 4 | 0.530 6 | 1 |
| 古城墙 | 开放时间 | 8:00 | 0.071 3 | 0.714 4 | 0.543 4 | 1 |
| …… | …… | …… | …… | …… | …… | …… |
| 数据源(网页) | 相关性 | 新颖性 | 可靠性 | 完整性 | ||
| http://www.mafengwo.cn/i/10003466.html | 0.287 0 | 0.449 5 | 0.680 1 | - | ||
| …… | …… | …… | …… | …… | ||
| 数据源(网站) | 相关性 | 新颖性 | 可靠性 | 完整性 | ||
| 马蜂窝 | 0.257 7 | 0.428 1 | 0.872 5 | - | ||
| 数据集(GeoKG) | 相关性 | 新颖性 | 可靠性 | 完整性 | ||
| 旅游知识图谱 | 0.754 5 | 0.423 8 | 0.406 2 | N | ||
注:N表示空。 |
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
陆锋, 余丽, 仇培元. 论地理知识图谱[J]. 地球信息科学学报, 2017, 19(6):723-734.
[
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
Fürber, Christian and Hepp, Martin, Swiqaa semantic web information quality assessment framework[C]// 19th European Conference on Information Systems. ECIS 2011, Helsinki, Finland, 9-11 June 2011.
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
田民, 刘思峰, 卜志坤. 灰色关联度算法模型的研究综述[J]. 统计与决策, 2008(1):24-27.
[
|
| [38] |
|
| [39] |
|
| [40] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}