
M2T多源知识图谱融合的空间场景描述文本自动生成框架
|
陈晖萱(1999— ),女,山西临汾人,硕士生,主要从事地理人工智能应用研究。E-mail: hxchen@cnic.cn |
收稿日期: 2023-01-28
修回日期: 2023-04-01
网络出版日期: 2023-06-02
基金资助
国家自然科学基金项目(41971366)
国家自然科学基金项目(91846301)
中央高校基本科研业务费项目(BUCTRC:202132)
M2T: A Framework of Spatial Scene Description Text Generation based on Multi-source Knowledge Graph Fusion
Received date: 2023-01-28
Revised date: 2023-04-01
Online published: 2023-06-02
Supported by
National Natural Science Foundation of China(41971366)
National Natural Science Foundation of China(91846301)
Fundamental Research Funds for the Central Universities(BUCTRC:202132)
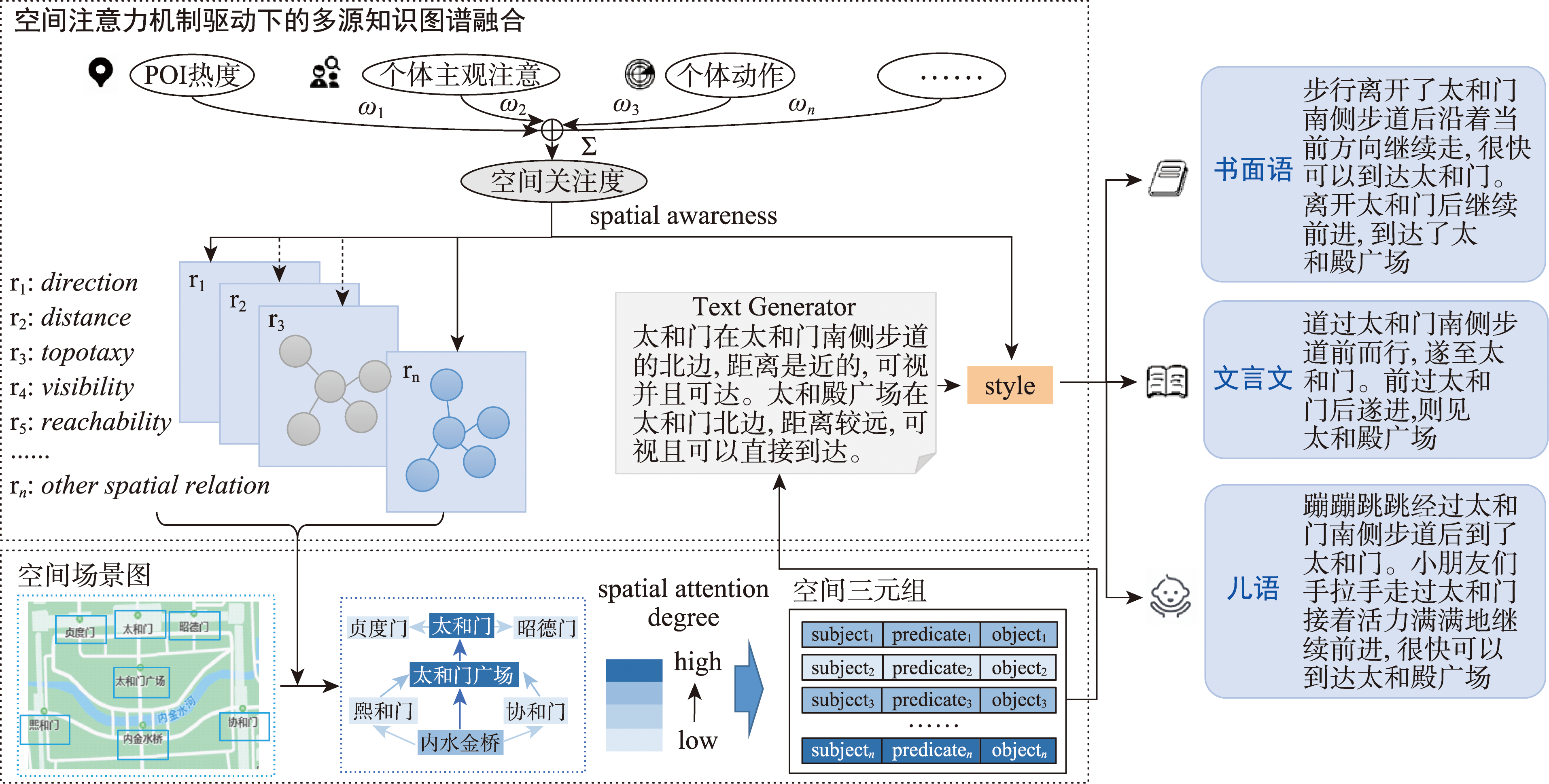
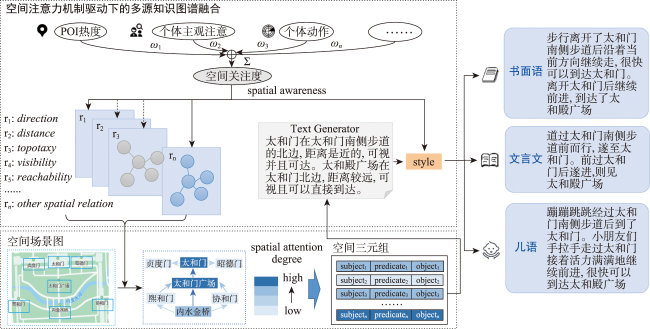
面向自然语言的地理空间场景描述一直是地理信息科学的重要研究方向,传统方法更注重空间关系的遍历性描述,难以融合人类空间认知,与人类自然语言有较大的差距。地理空间场景自然语言描述的本质是地理空间二维向量转换词空间一维向量的过程。本文提出M2T空间场景自然语言表达框架,通过空间场景理解、语言合成和注意力感知3个知识图谱,在多源知识图谱的融合机制下,生成自然语言空间场景描述文本。其中空间场景描述知识图谱解决遍历空间关系剪枝难题,同时通过建立空间关系图谱建立空间场景之间关联,支持空间场景连续表达;自然语言风格知识图谱建立空间表达与语言风格的关联,实现了贴切于空间自然语言表达的多样化语言风格;空间关注度知识图谱根据空间场景主体和客体交互状态,建立注意力矩阵捕捉自然语言空间表达的细微之处。以北京故宫为例设计的原型系统,实验表明系统生成结果与人类游记接近,且内容覆盖更完整,风格更多样,验证了M2T框架的有效性,并展现了空间场景自然语言描述应用的潜在价值。
陈晖萱 , 郭旦怀 , 葛世寅 , 王婧 , 王彦棡 , 陈峰 , 杨微石 . M2T多源知识图谱融合的空间场景描述文本自动生成框架[J]. 地球信息科学学报, 2023 , 25(6) : 1176 -1185 . DOI: 10.12082/dqxxkx.2023.230034
Natural language is an effective tool for humans to describe things, with diversity and ease of dissemination, and can contain human spatial cognitive results. How to use natural language to describe geographic spatial scenes has always been an important research direction in spatial cognition and geographic information science, providing important application values in personalized unmanned tour guides, blind navigation, virtual space scene interpretation, and so on. The essence of natural language description of geographic spatial scenes is the process of transforming the two-dimensional vector of geographic space into a one-dimensional vector in word space. Traditional models perform well in handling spatial relationships, but are somewhat inadequate in natural language description: (1) spatial relationship description models are one-way descriptions of the environment by humans, without considering the impact of the environment on the description; (2) spatial scenes emphasize traversal-based descriptions of spatial relationships, where each set of spatial relationships is equally weighted, which is inconsistent with the varying attention paid by humans to geographic entities and spatial relationships in the environment; (3) the spatial relationship calculation of traditional models is a static description of a single scene, which is difficult to meet the requirement of dynamic description of continuous scenes in practical applications; (4) the natural language style of traditional models is mechanical, lacking necessary knowledge support. This article proposes a spatial scene natural language generation framework Map2Text (M2T) that integrates multiple knowledge graphs. The framework establishes knowledge graphs for spatial relationships, language generation style, and spatial attention, respectively, and realizes the fusion of multiple knowledge graphs and the generation of natural language descriptions of spatial scenes within a unified framework. The spatial scene description knowledge graph solves the pruning problem of traversing spatial relationships, and establishes the relationship between spatial scenes by building a spatial relationship graph, supporting continuous expression of spatial scenes; the natural language style knowledge graph establishes the relationship between spatial expression and language style, achieving diversified language styles that are appropriate for spatial natural language expression; the spatial attention knowledge graph captures the nuances of natural language spatial expression by establishing an attention matrix based on the interaction state between the subject and object of the spatial scene. An experimental prototype system designed based on the Beijing Forbidden City demonstrates that the system-generated results are close to human travel notes, with more complete content coverage and more diverse styles, verifying the effectiveness of the M2T framework and demonstrating the potential value of natural language description of spatial scenes.
| Spots: [... ['id': id, 'name': name, 'type':[transit, spot], 'architecture': [dian, gong, tang, ge, lou, men, zhai, xuan, guan, ting, qiao, huayuan, else] 'description':... ] ... ] |
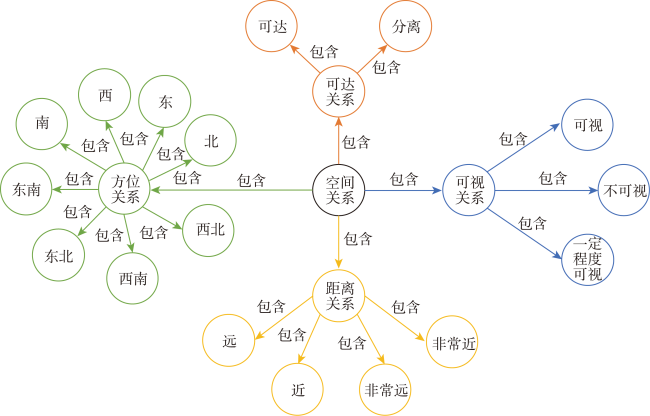
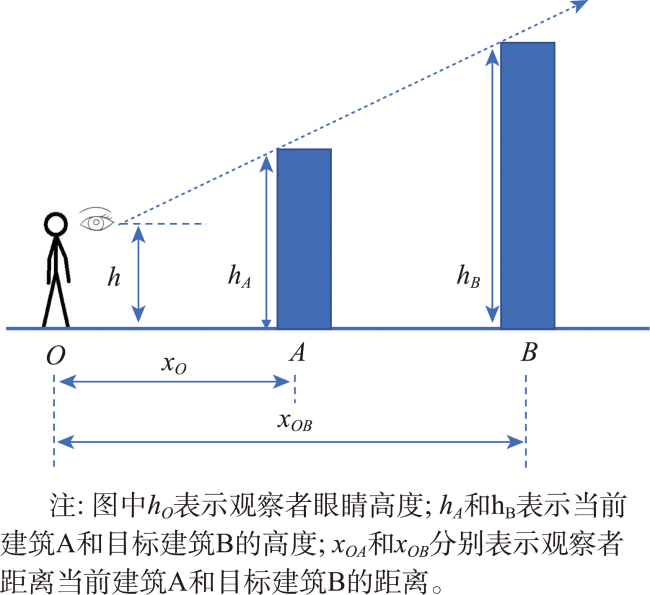
| Palacerelationship: [... ['subjectid': subjectid, 'objectid': objectid, 'reationshipid': relationshipid, 'relationship': [direction, attention, distance, higher, visibility, reachability] ] ... ] |
| 算法1:空间场景描述文本生成算法 |
|---|
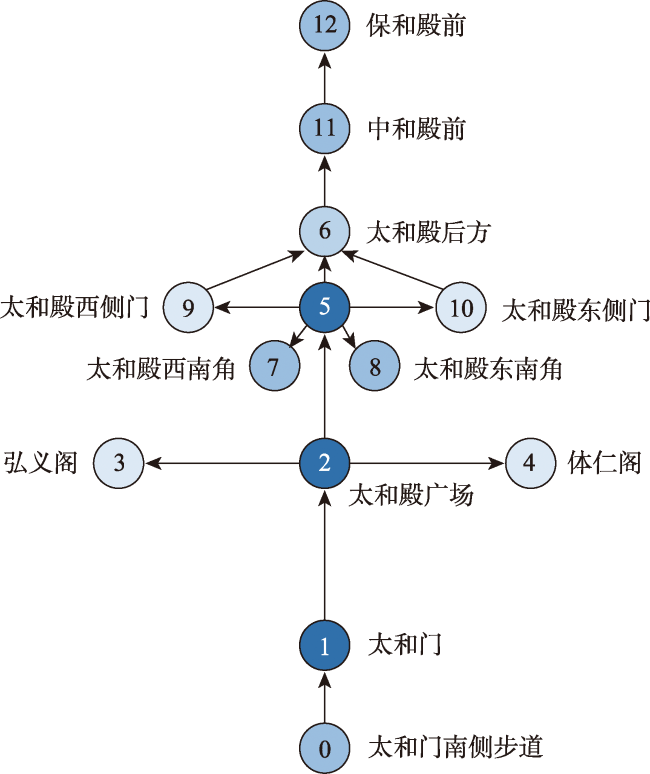
| 输入:POI路线 R 输出:空间场景描述句子 1 while q.empty( )=0 do 2 u=q.get( ); 3 ard=AttnSort(u.adjacent( )); 4 for v in ard do 5 if u.type='transit' then 6 do action(arrive); 7 do action(forward) 8 end 9 else 10 do action(arrive); 11 do action(lookaround); 12 do action(forward) 13 end 14 end 15 end |
表1 M2T系统与网络游记输出文本对比Tab. 1 Comparison between M2T system and online travel notes |
| 书面语(M2T) | 文言文(M2T) | 儿语版(M2T) | 传统游记 |
|---|---|---|---|
| 步行离开了午门后沿着当前方向继续走,很快可以到达太和门。离开太和门后继续前进,到达了太和殿广场。太和殿广场是故宫中最大的广场,广场上空旷宁静,十分庄严肃穆。朝着太和殿广场的正西方向坐落着弘义阁。太和殿广场距离弘义阁很远。弘义阁相比于太和殿广场高出很多 | 道过午门前而行,遂至太和门。前过太和门后遂进,则见太和殿广场。上旷静,严肃肃清。望之太和殿广场之西立弘义阁。太和殿广场与弘义阁久之乃至。弘义阁比于此太和殿广场需仰而望之 | 蹦蹦跳跳经过午门后继续前进,到达了太和门。小朋友们手拉手走过太和门接着活力满满地继续前进,很快可以到达太和殿广场。太和殿广场好大呀,站在广场上觉得自己很渺小。小脚丫迈着步伐继续向前进太和殿广场之正西方向出现了弘义阁。从太和殿广场到弘义阁要走很长一段路。弘义阁比起太和殿广场好高呀 | 今年暑假,我怀着快乐的心情来到了故宫。进入午门,绕过太和门,就来到了广场。这里据说是当年百官朝拜的地方 |
| 面向太和殿后方的正北方向出现了中和殿。两者距离不是很远,高度相当,能够步行到达 | 望之太和殿后方之北见中和殿。不出数步乃至。中和殿前相之太和殿后方高庶几乎。在太和殿后方,能以通此 | 小脑袋朝北方向看见了中和殿前。太和殿后方跟中和殿前距离不是很远,走一会就到了。中和殿前相比于太和殿肩并肩,高度差不多。停下脚步站在太和殿后方,小朋友可以直接走路就能到达 | 我们穿过太和门,来到太和殿。太和殿后面是中和殿,中和殿是皇帝上朝前休息的地方 |
| [1] |
杜清运, 任福. 空间信息的自然语言表达模型[J]. 武汉大学学报·信息科学版, 2014, 39(6):682-688.
[
|
| [2] |
|
| [3] |
郭旦怀. 基于空间场景相似性的地理空间分析[M]. 北京: 科学出版社, 2016.
[
|
| [4] |
赵伟, 吴金娜. 浅谈地图的发展史[J]. 城市勘测, 2022(5):111-116.
[
|
| [5] |
马耀峰, 李君轶. 旅游者地理空间认知模式研究[J]. 遥感学报, 2008, 12(2):378-384.
[
|
| [6] |
王晓明, 刘瑜, 张晶. 地理空间认知综述[J]. 地理与地理信息科学, 2005, 21(6):1-10.
[
|
| [7] |
张卫锋. 跨媒体数据语义分析技术研究[D]. 杭州: 杭州电子科技大学, 2019.
[
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}