
顾及地理语义的地图检索意图形式化表达与识别
|
桂志鹏(1982— ),男,宁夏吴忠人,博士,副教授,主要从事高性能地理计算与时空大数据分析相关研究。E-mail: zhipeng.gui@whu.edu.cn |
收稿日期: 2023-01-13
修回日期: 2023-02-21
网络出版日期: 2023-06-02
基金资助
国家自然科学基金项目(42090011)
国家自然科学基金项目(41971349)
国家重点研发计划项目(2021YFE0117000)
Map Retrieval Intention Formalization and Recognition by Considering Geographic Semantics
Received date: 2023-01-13
Revised date: 2023-02-21
Online published: 2023-06-02
Supported by
National Natural Science Foundation of China(42090011)
National Natural Science Foundation of China(41971349)
National Key Research and Development Program of China(2021YFE0117000)
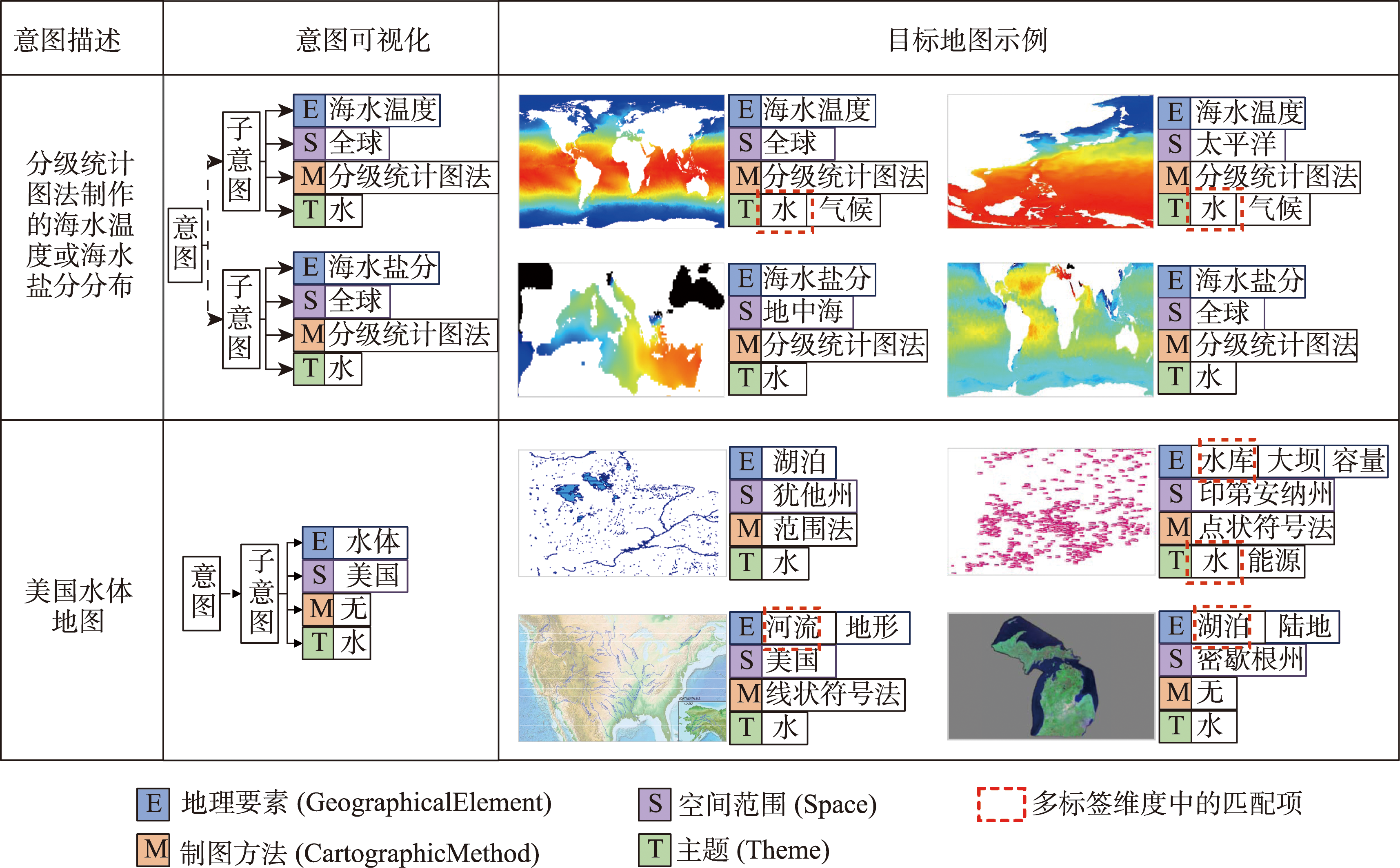
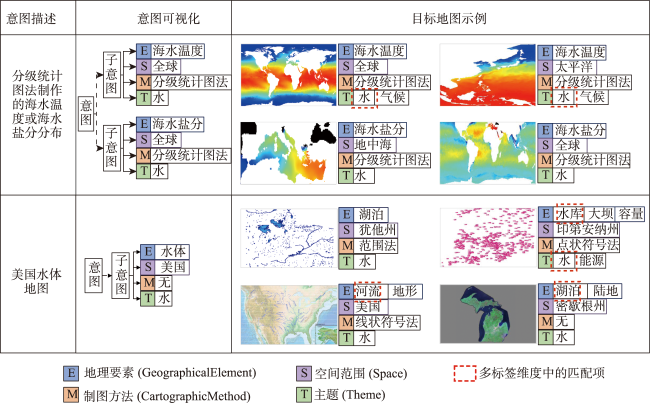
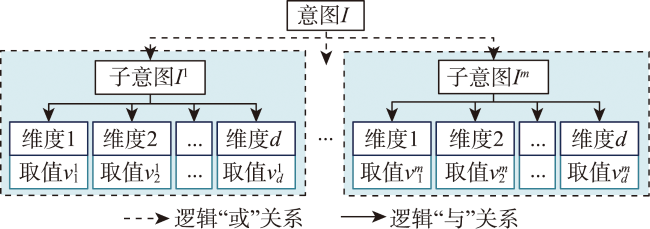
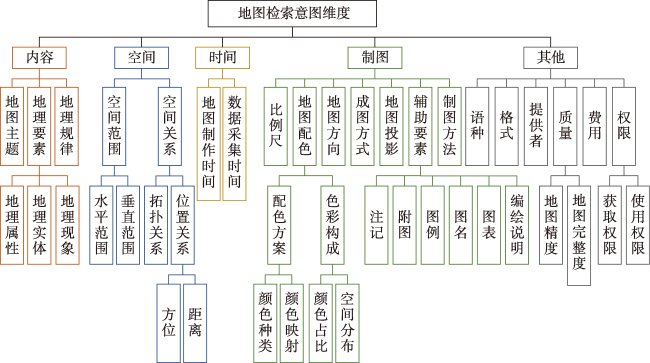
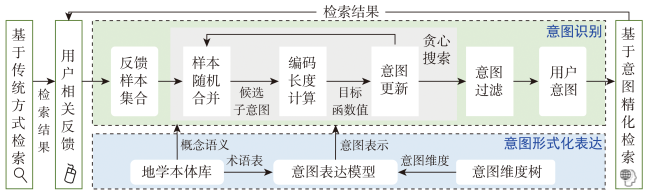
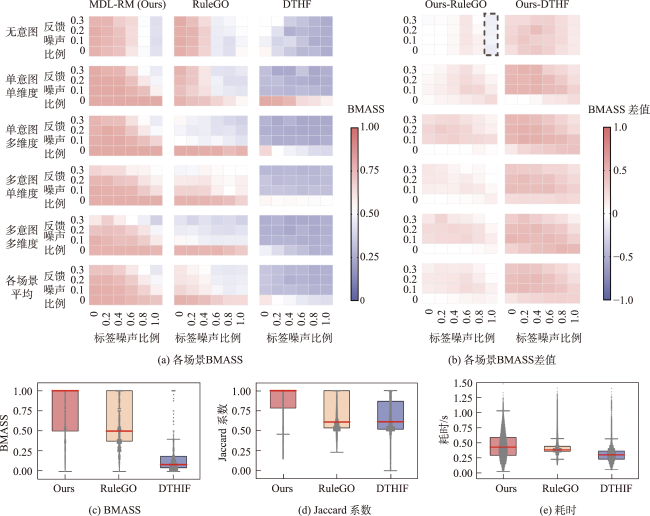
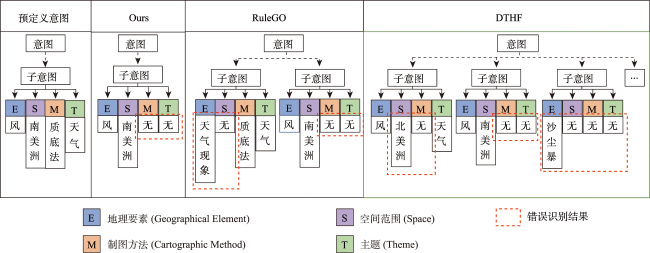
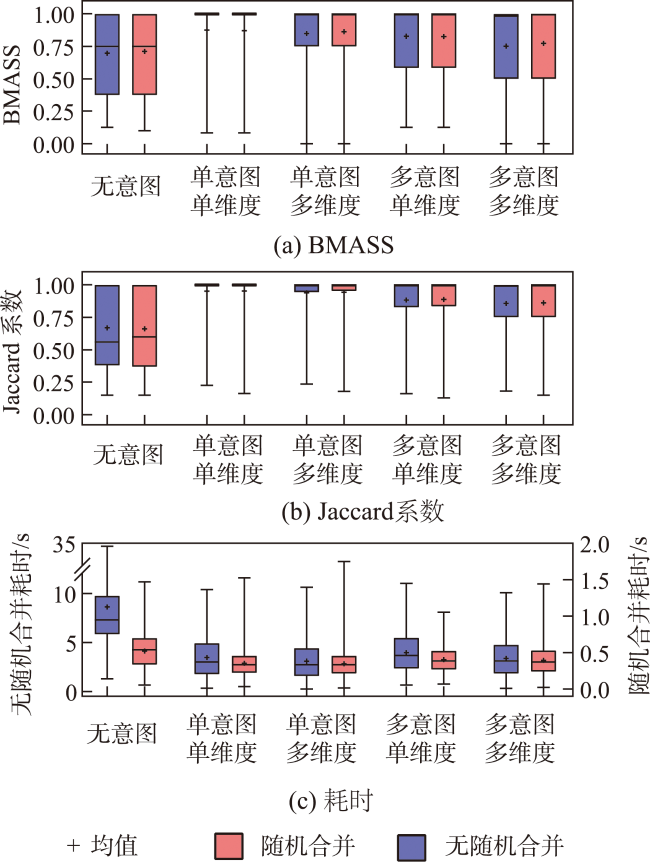
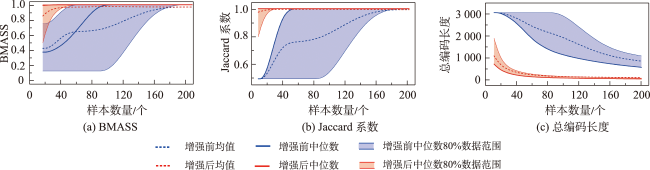
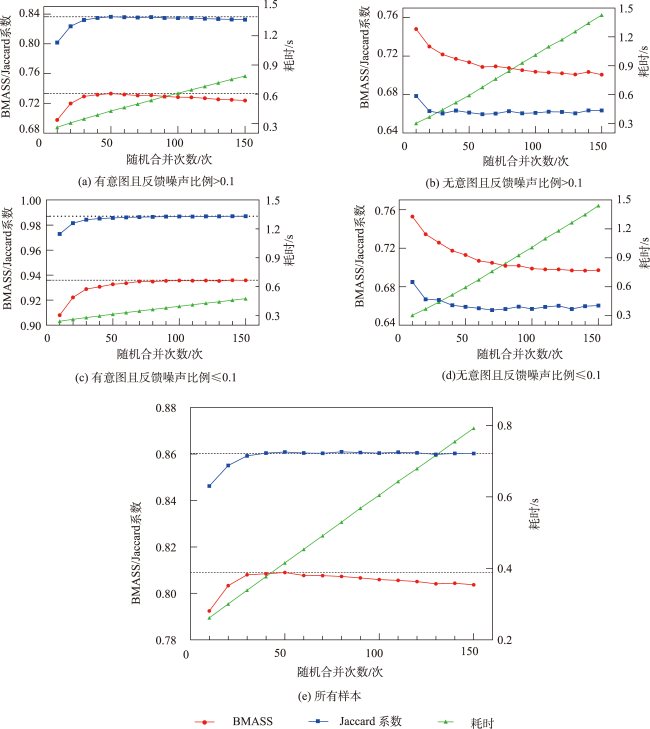
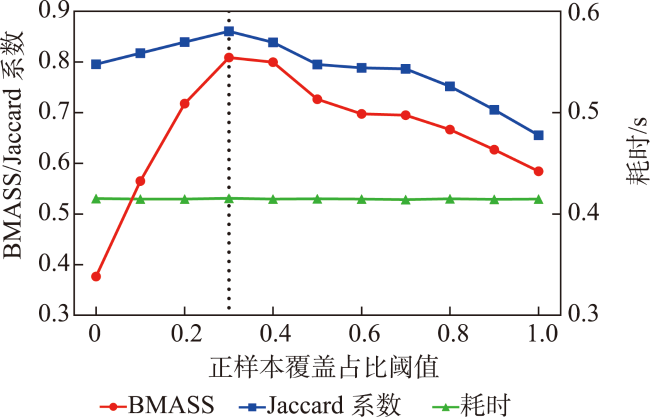
主流地图检索方法多基于元数据文本匹配或图像内容相似度计算,缺乏对用户意图的主动理解,导致检索结果欠佳;而现有意图识别方法无法准确表达与识别复杂地理概念联合约束的地图资源检索需求。为此,本文提出一种顾及地理语义的地图检索意图形式化表达与识别方法,旨在利用相关反馈样本“感知”用户需求,以提升检索精度。该方法通过地理本体约束“意图-子意图-维度分量”模型的构建,实现检索需求的语义化描述;并将意图识别视为组合优化问题,基于最小描述长度准则、顾及地理概念从属关系的样本随机合并策略及贪心搜索实现最优意图识别。实验结果表明,相比基于频繁项集挖掘的RuleGO、决策树的DTHF算法,本文方法具有更高的识别准确度与噪声容忍度;随机合并策略可在不降低识别准确性的情况下有效缩短平均求解耗时;样本增强策略保证算法在样本规模仅为20时仍具有较高识别准确度。该方法可望应用于地理信息门户,提升各类地理信息资源共享与发现的服务品质。
桂志鹏 , 胡晓辉 , 刘欣婕 , 凌志鹏 , 姜屿涵 , 吴华意 . 顾及地理语义的地图检索意图形式化表达与识别[J]. 地球信息科学学报, 2023 , 25(6) : 1186 -1201 . DOI: 10.12082/dqxxkx.2023.230019
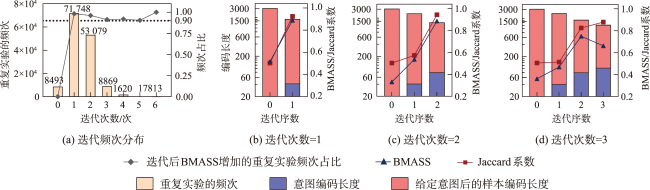
Mainstream map retrieval methods for spatial data infrastructures are mainly based on metadata text matching or image similarity calculation, but such approaches lack active perception and understanding of user retrieval intention, and in turn fail to truly meet user requirements. While existing intention recognition methods are incapable to express and recognize map retrieval demands with joint constraints of complex geographic concepts. To address this issue, this paper proposes a map retrieval intention formalization and recognition method by considering geographic semantics, aiming to improve the accuracy of map retrieval in an intention-driven and explainable manner by using relevance feedback samples. More specifically, a formalization model constrained by geographic ontology in the form of "intention-sub-intention-dimension component" is designed for expressing user's map retrieval intention. With the support of the formalization model, a recognition algorithm based on Minimum Description Length (MDL) principle and Random Merging (RM) strategy, named MDL-RM, is proposed by treating intention recognition as a combinational optimization problem. MDL-RM takes the description length of the sample set from relevance feedback as the optimization goal, merges samples randomly with the assistance of geographic ontologies and semantic similarities among geographic terminologies to generate sub-intention candidates, and searches the optimal intention using a greedy search approach. In order to evaluate the accuracy of recognized intention, we proposed a semantic metric, named Best Map Average Semantic Similarity (BMASS), and calculated it along with Jaccard index in five typical map retrieval scenes. Meanwhile, we analyzed the time cost and the influence of parameter settings and validated the effectiveness of random merge and sample augmentation strategy. The experimental results on the synthetic data demonstrate that the proposed method has higher accuracy and sample noise tolerance in most retrieval scenes comparing with the method based on Gene Ontology (RuleGO) and the Decision Tree learning method with Hierarchical Features (DTHF). The random merge strategy can reduce average computing time effectively without declining accuracy, and the sample augmentation strategy facilitates retrieval intention recognition even when the sample size is as low as 20. The proposed method is expected to be adapted and applied into geoportals and catalogue services to improve the service quality and user experiences upon the sharing and discovery of geographic information resources.
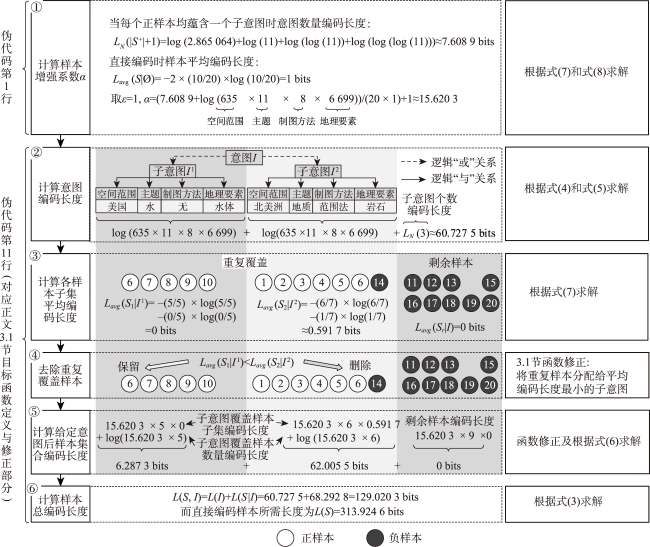
图6 针对给定意图的相关反馈样本集合总编码长度计算示例Fig. 6 Illustration of coding length calculation of relevance feedback sample set under given retrieval intention |
表1 相关反馈样本集合示例Tab.1 Example of relevance feedback sample set |
| 正样本 | 负样本 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 编号 | 空间范围 | 主题 | 制图方法 | 地理要素 | 编号 | 空间范围 | 主题 | 制图方法 | 地理要素 |
| 1 | 加拿大 | 地质 | 范围法 | 岩石 | 11 | 巴西 | 地质 | 范围法 | 沉积岩 |
| 2 | 美国 | 地质 | 范围法 | 变质岩 | 12 | 智利 | 地质 | 范围法 | 混合岩 |
| 3 | 北美洲 | 地质 | 范围法 | 沉积岩 | 13 | 缅因州 | 水 | 分级统计图 | 隔水层 |
| 4 | 内华达州 | 地质 | 范围法 | 斜长石 | 14 | 美国 | 地质 | 范围法 | 沉积岩 |
| 5 | 墨西哥 | 地质 | 范围法 | 橄榄岩 | 15 | 佛罗里达州 | 水 | 范围法 | 防洪堤 |
| 6 | 加利福尼亚州 | 水、地质 | 点状符号法、范围法 | 泉水、沉积岩 | 16 | 印第安纳州 | 生物多样性 | 分级统计图 | 鸟类 |
| 7 | 犹他州 | 水 | 质底法 | 湖泊 | 17 | 南美洲 | 水 | 分级统计图 | 降水 |
| 8 | 内华达州 | 水 | 范围法 | 湿地 | 18 | 加拿大 | 水 | 线状符号法 | 河流 |
| 9 | 佛罗里达州 | 水 | 范围法 | 水库 | 19 | 北美洲 | 地质 | 范围法 | 矿物 |
| 10 | 美国 | 水 | 线状符号法 | 河流 | 20 | 巴西 | 地质 | 分级统计图 | 土壤 |
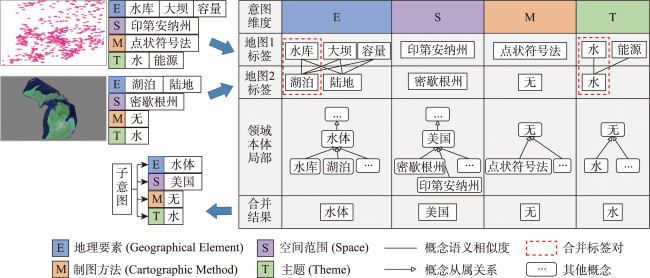
图7 基于反馈样本语义合并的子意图生成Fig. 7 Sub-intention generation based on semantic merging of feedback samples |
| 算法1: 基于最短描述长度准则与随机合并策略的地图检索意图识别算法(MDL-RM) |
|---|
| 输入:反馈样本集合 ,各意图维度本体 ,随机合并数量 ,正样本覆盖比例阈值 输出:地图检索子意图集合 1 calculate ; /*计算样本增强系数*/ 2 , , ; /*初始化子意图 集合、总编码长度与剩余样本集合*/ 3 repeat ; /*初始化候选子意图集合数组*/ 5 for i from 0 to do 6 ; ; /*生成候选子意图*/ 8 ; /*生成候选子意图集合*/ ; 10 end for ; /*获取使得总编码长度最小 的候选子意图集合*/ ; 13 if then 14 15 end if 16 until ; /*过滤 中正样本覆盖比例低于 的子意图*/ 18 return |
| [1] |
王家耀, 成毅. 论地图学的属性和地图的价值[J]. 测绘学报, 2015, 44(3):237-241.
[
|
| [2] |
闾国年, 袁林旺, 俞肇元. 地理学视角下测绘地理信息再透视[J]. 测绘学报, 2017, 46(10):1549-1556.
[
|
| [3] |
成晓强, 杨敏, 桂志鹏, 等. 信息量与相似度约束下的网络地图服务缩略图自动生成算法[J]. 测绘学报, 2017, 46(11):1891-1898.
[
|
| [4] |
|
| [5] |
孟婵媛, 李勤超, 李宏伟, 等. 基于本体的地理信息查询检索方法研究[J]. 测绘科学, 2008, 33(S1):251-253,188.
|
| [6] |
苗立志, 胥婕, 周亚, 等. 应用描述词汇约简的OGC地理信息服务演绎推理[J]. 测绘学报, 2015, 44(9):1029-1035,1062.
[
|
| [7] |
王东旭, 诸云强, 潘鹏, 等. 地理数据空间本体构建及其在数据检索中的应用[J]. 地球信息科学学报, 2016, 18(4):443-452.
[
|
| [8] |
邬群勇, 郑孝苗, 康凌骏. 语义地理信息服务的三级匹配发现算法[J]. 厦门大学学报(自然科学版), 2012, 51(2):195-199.
[
|
| [9] |
|
| [10] |
高勇, 姜丹, 刘磊, 等. 一种地理信息检索的定性模型[J]. 北京大学学报(自然科学版), 2016, 52(2):265-273.
[
|
| [11] |
张敏, 桂志鹏, 成晓强, 等. 一种WMS领域主题文本提取及元数据扩展方法[J]. 武汉大学学报·信息科学版, 2019, 44(11):1730-1738.
[
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
李牧闲, 桂志鹏, 成晓强, 等. 多核学习与用户反馈结合的WMS图层检索方法[J]. 测绘学报, 2019, 48(10):1320-1330.
[
|
| [16] |
|
| [17] |
葛芸, 江顺亮, 叶发茂, 等. 基于ImageNet预训练卷积神经网络的遥感图像检索[J]. 武汉大学学报·信息科学版, 2018, 43(1):67-73.
[
|
| [18] |
|
| [19] |
解虹. 数字化环境下交互式信息检索[M]. 北京: 科学出版社, 2010.
[
|
| [20] |
陈翀, 刘晓兵, 徐谷子, 等. 一种搜索引擎的查询意图发现的新方法[J]. 情报学报, 2012, 31(3):242-249.
[
|
| [21] |
|
| [22] |
|
| [23] |
严锐, 李石君. 基于查询意图识别与主题建模的文档检索算法[J]. 计算机工程, 2018, 44(3):189-194.
[
|
| [24] |
张瑞芳, 郭克华. 面向个性化站点的用户检索意图建模方法[J]. 计算机工程与应用, 2018, 54(6):37-43.
[
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
肖珑, 苏品红, 姚伯岳. 国家图书馆舆图元数据规范和著录规则[M]. 北京: 国家图书馆出版社, 2014.
[
|
| [31] |
Content Standard for Digital Geospatial Metadata(FGDC-STD-001-1998)[S].
|
| [32] |
黄仁涛. 专题地图编制[M]. 武汉: 武汉大学出版社, 2003.
[
|
| [33] |
查正军, 郑晓菊. 多媒体信息检索中的查询与反馈技术[J]. 计算机研究与发展, 2017, 54(6):1267-1280.
[
|
| [34] |
曾安, 李晓兵, 杨海东, 等. 基于最小描述长度和K2的贝叶斯网络结构学习算法[J]. 东北师大学报(自然科学版), 2014, 46(3):53-58.
[
|
| [35] |
|
| [36] |
|
| [37] |
李星洁. 形式学习理论与相关归纳逻辑问题研究[D]. 昆明: 云南师范大学, 2020.
[
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
GeoNames. GeoNames[EB/OL]. http://geonames.org/, 2005.
|
| [44] |
|
| [45] |
|
| [46] |
|
/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}