
基于时空组Lasso与分层贝叶斯时空模型的变量选择方法
|
王 玲(1974— ),女,北京人,博士,教授,主要从事数据挖掘、模式识别等研究。E-mail: lingwang@ustb.edu.cn |
收稿日期: 2022-10-10
修回日期: 2023-02-08
网络出版日期: 2023-06-30
基金资助
国家自然科学基金项目(62076025)
国家自然科学基金项目(61572073)
广东省基础与应用基础研究基金(2023A1515011320)
Variable Selection Method based on Spatio-temporal Group Lasso and Hierarchical Bayesian Spatio-temporal Model
Received date: 2022-10-10
Revised date: 2023-02-08
Online published: 2023-06-30
Supported by
National Natural Science Foundation of China(62076025)
National Natural Science Foundation of China(61572073)
Guangdong Basic and Applied Basic Research Foundation(2023A1515011320)
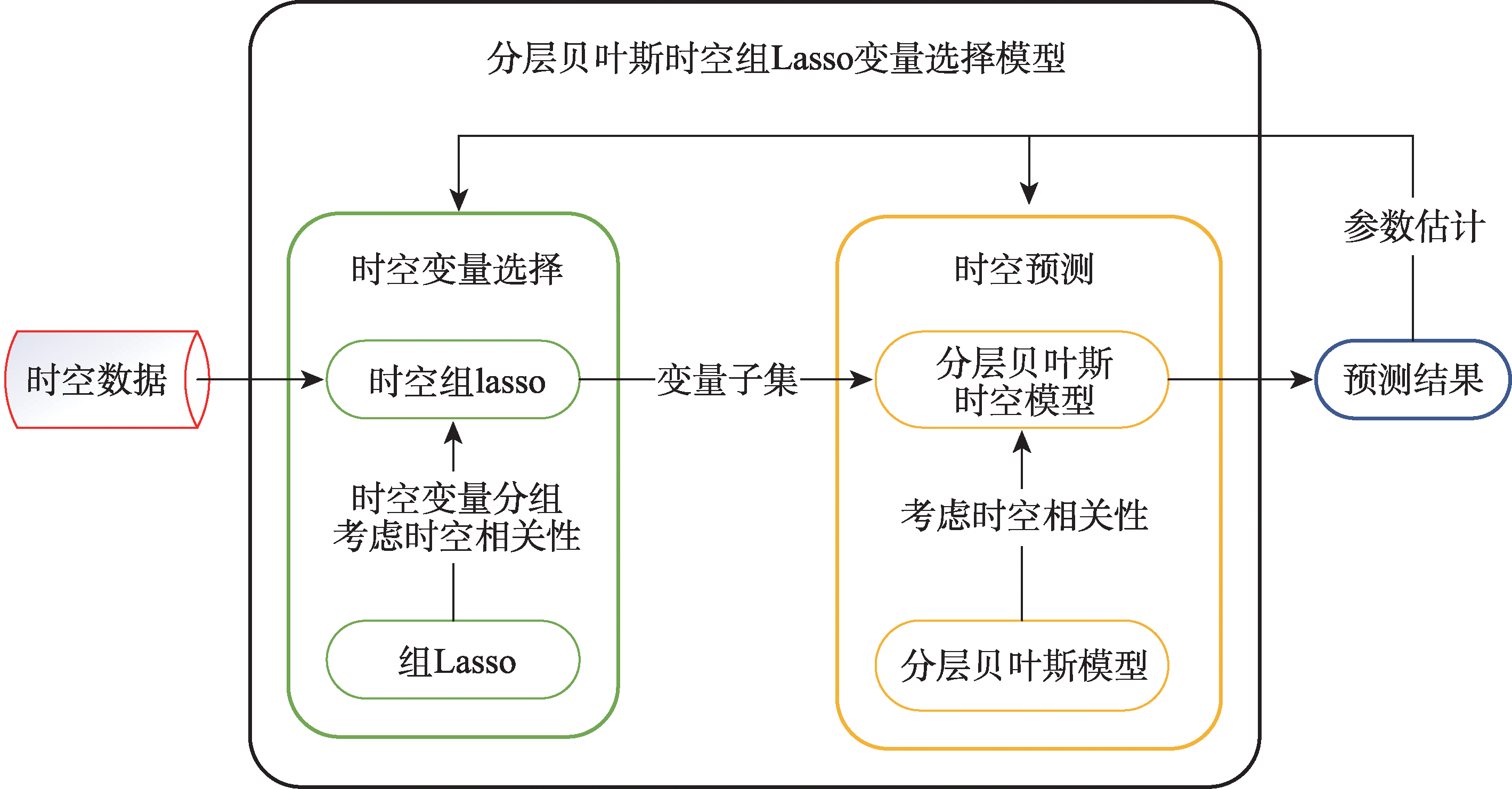
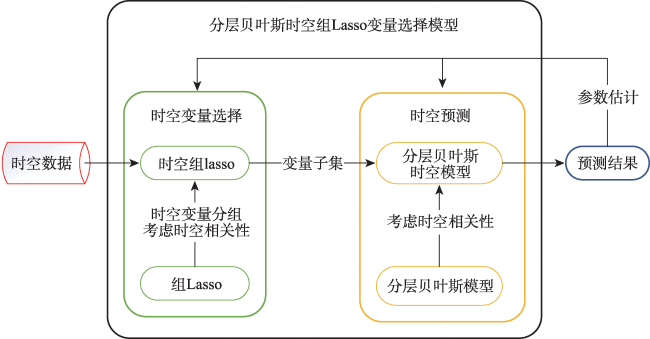
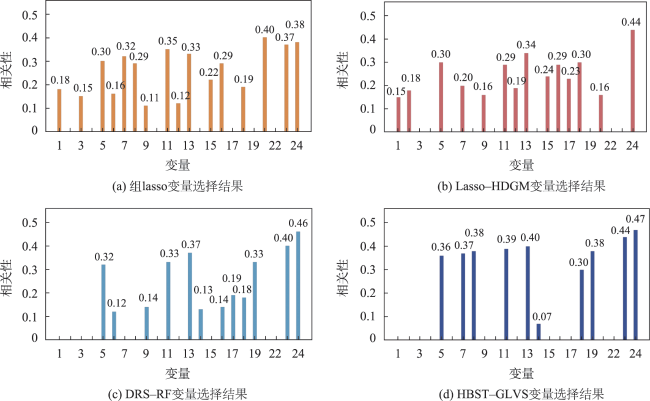
从高维度、大数据量的时空数据中有效选择变量是时空数据领域的重要问题之一,现有的时空数据变量选择的方法在变量选择的过程中未充分考虑时空相关性,时空变量选择阶段与预测阶段分开进行,且往往需要人为设定时空点个数阈值判定变量的取舍,从而无法较为准确的选择对因变量影响最大的变量子集,导致后续预测效果较差。本文针对上述不足,提出了一种基于时空组Lasso与分层贝叶斯时空模型的变量选择方法,称为分层贝叶斯时空组Lasso变量选择模型(Hierarchical Bayesian Spatio-temporal Group Lasso Variable Selection Method, HBST-GLVS),该方法首先利用时空组Lasso进行变量选择,通过引入最大时间滞后和最大空间邻域充分考虑时空相关性,并根据时空数据连续性,将同一时空变量的时空点进行整体惩罚,避免人为设定时空点个数引起局部片面性。然后,利用分层贝叶斯时空模型对变量选择的效果进行验证,将变量选择过程与模型验证过程置于同一框架下进行参数的调整,从而得到最优的变量子集。实验结果表明,与现有方法相比,本文方法在北京空气质量数据集、波特兰交通流数据集上的RMSE(Root Mean Square Error)和MAE(Mean Square Error)可分别降低9.6%~25.7%以及6.6%~15.9%。
王玲 , 康子豪 . 基于时空组Lasso与分层贝叶斯时空模型的变量选择方法[J]. 地球信息科学学报, 2023 , 25(7) : 1312 -1324 . DOI: 10.12082/dqxxkx.2023.220769
It is one of the important issues in the field of spatio-temporal data analysis to effectively select variables from high-dimensional and large-scale spatio-temporal data. As the most important features of spatio-temporal data, the temporal and spatial correlation of spatio-temporal data must be considered to make effective variable selection. However, existing spatio-temporal data variable selection methods do not fully consider the spatio-temporal correlation, and the variable selection stage is separated from the prediction stage. Moreover, these methods often require manual setting of a threshold of the number of spatiotemporal points to determine variables selection, which may lead to inaccurate selection of the subset of variables that have the greatest impact on the dependent variable, and result in poor prediction performance. In this paper, we propose a variable selection method based on the spatio-temporal group Lasso and the hierarchical Bayesian spatiotemporal model, called the hierarchical Bayesian Spatio-temporal Group Lasso Variable Selection method (HBST-GLVS). In this method, the spatio-temporal expansion is carried out simultaneously in the variable selection stage and prediction stage, and the best nearest neighbor time domain and space domain are determined adaptively through cross validation. In order to obtain the best prediction performance from the selection of variables, the selection of spatio-temporal variables and the prediction of spatiotemporal models are placed under the same framework, so that the selected variables and parameters correspond to the best prediction performance. In order to solve the problem of manual setting of the threshold of the number of spatio-temporal points, the variable selection is processed from the perspective of the entire sequence of spatio-temporal variables, without the threshold of the number of spatio-temporal points. Specifically, this method uses spatio-temporal group Lasso for variable selection, fully considers spatio-temporal correlation by introducing maximum time lag and maximum spatial neighborhood, and applies global penalty to all spatio-temporal points of the same variable based on spatio-temporal data continuity, thus avoiding the lopsidedness caused by artificial setting of thresholds. The effect of variable selection is validated using a hierarchical Bayesian spatio-temporal model, and the variable selection process and the model validation process are placed under the same framework for the adjustment of parameters, so as to obtain the optimal subset of variables. Our results show that the Root Mean Square Error (RMSE) and Mean Square Error (MAE) of the method in this paper can be reduced by 9.6%~25.7% and 6.6%~15.9%, based on Beijing air quality dataset and Portland traffic flow dataset, respectively, compared with the existing methods.
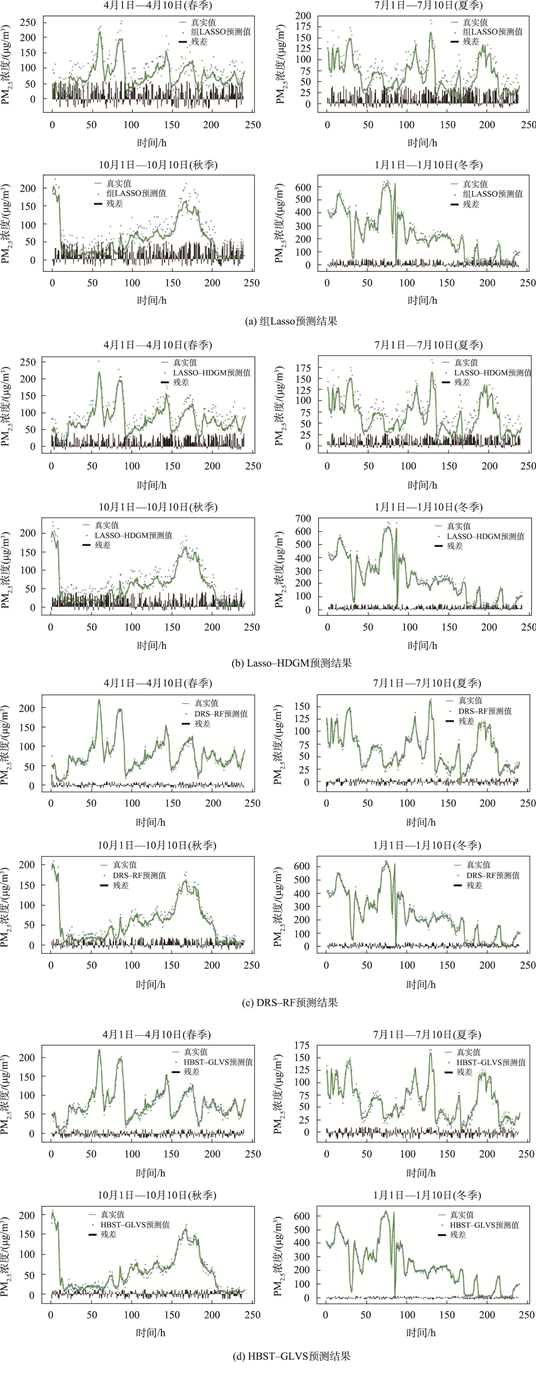
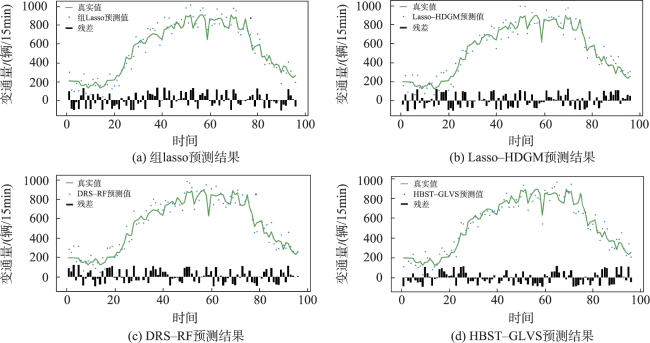
图4 各种方法在每个季节各10天中的预测结果Fig. 4 Prediction results of various methods for ten days in each season |
表1 各种方法在4个完整季节中的RMSE与平均RMSETab. 1 RMSE and average RMSE of various methods in four full seasons |
| 方法 | 春 | 夏 | 秋 | 冬 | 平均 |
|---|---|---|---|---|---|
| 组Lasso | 27.29 | 25.22 | 25.44 | 28.38 | 26.58 |
| Lasso-HDGM | 21.37 | 20.90 | 20.54 | 20.73 | 20.89 |
| DRS-RF | 14.51 | 15.73 | 17.85 | 16.90 | 16.50 |
| HBST-GLVS | 14.12 | 14.25 | 15.77 | 15.32 | 14.87 |
表2 各种方法在4个完整季节中的MAE与平均MAETab. 2 MAE and average MAE of various methods in the four full seasons |
| 方法 | 春 | 夏 | 秋 | 冬 | 平均 |
|---|---|---|---|---|---|
| 组Lasso | 20.38 | 21.25 | 19.02 | 22.20 | 20.71 |
| Lasso-HDGM | 17.89 | 18.35 | 17.25 | 18.43 | 17.98 |
| DRS-RF | 11.70 | 12.25 | 14.23 | 14.26 | 13.11 |
| HBST-GLVS | 10.89 | 10.21 | 12.98 | 12.01 | 11.02 |
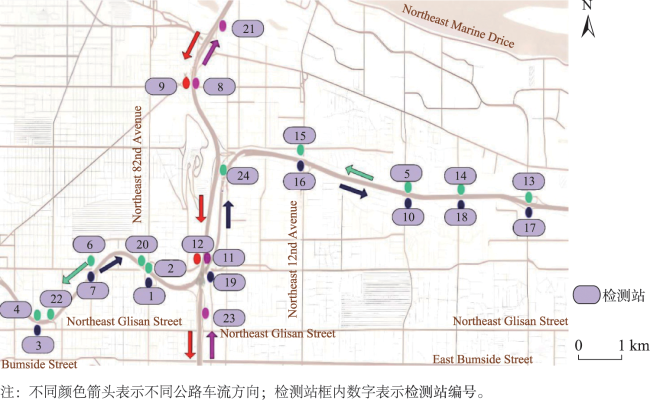
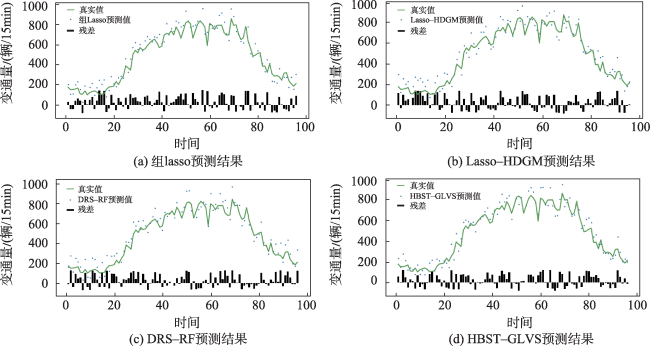
图7 不同方法对21号检测站的预测结果对比Fig. 7 Comparison of the prediction results of different methods on the 21st testing station |
表3 不同方法对21号检测站预测误差Tab. 3 Prediction error of different methods for testing station 21 (%) |
| 方法 | RMSE | MAE |
|---|---|---|
| 组Lasso | 70.86 | 84.32 |
| Lasso-HDGM | 70.31 | 78.77 |
| DRS-RF | 67.61 | 66.76 |
| HBST-GLVS | 62.47 | 60.99 |
图8 不同方法对所有检测站的平均预测结果对比图Fig. 8 Comparison of the average prediction results of different methods for all testing stations |
表4 不同方法对所有检测站的平均预测误差Tab. 4 Average prediction error of different methods for all testing stations (%) |
| 方法 | 平均 RMSE | 平均 MAE |
|---|---|---|
| 组Lasso | 76.02 | 88.53 |
| Lasso-HDGM | 74.86 | 83.32 |
| DRS-RF | 69.13 | 76.27 |
| HBST-GLVS | 62.46 | 71.23 |
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
许可, 王雅琼. 时空统计建模方法探讨[J]. 统计与决策, 2021, 37(22):11-14.
[
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
王雅琼, 徐敏亚, 王菲菲. 隐含动态地理统计校准模型——以PM2.5污染分析为例[J]. 数理统计与管理, 2021, 40(2):191-204.
[
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
陈小波, 刘祥, 韦中杰, 等. 基于GA-LSSVR模型的路网短时交通流预测研究[J]. 交通运输系统工程与信息, 2017, 17(1):60-66,81.
[
|
/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}