
融合多特征的轨迹数据自适应聚类方法
|
刘敬一(1992—),女,河北石家庄人,博士,主要从事时空大数据挖掘与智能应用研究。E-mail: jingyiliu24@163.com |
收稿日期: 2023-02-15
修回日期: 2023-04-07
网络出版日期: 2023-06-30
基金资助
中国博士后科学基金项目(2021M703021)
湖南省自然科学基金项目(2021JJ40727)
河北省人才择优自主基金项目(B2021003031)
湖南省自然资源厅科研项目(2013-17)
湖南省自然资源厅科研项目(2014-12)
湖南省自然资源厅科研项目(2015-09)
湖南省自然资源厅科研项目(2017-15)
An Automatic Trajectory Clustering Method Integrating Multiple Features
Received date: 2023-02-15
Revised date: 2023-04-07
Online published: 2023-06-30
Supported by
China Postdoctoral Science Foundation(2021M703021)
Hunan Provincial Natural Science Foundation of China(2021JJ40727)
Hebei Provincial Independent Fund for Talent Selection(B2021003031)
The Scientific Research Project of Natural Resources Department of Hunan Province(2013-17)
The Scientific Research Project of Natural Resources Department of Hunan Province(2014-12)
The Scientific Research Project of Natural Resources Department of Hunan Province(2015-09)
The Scientific Research Project of Natural Resources Department of Hunan Province(2017-15)
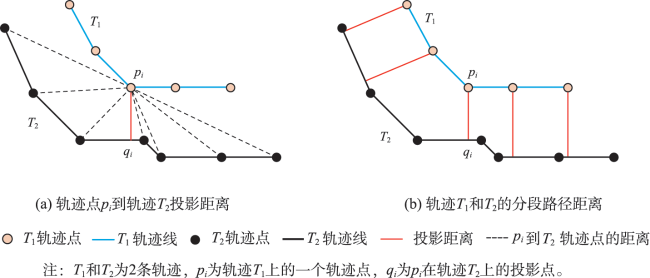
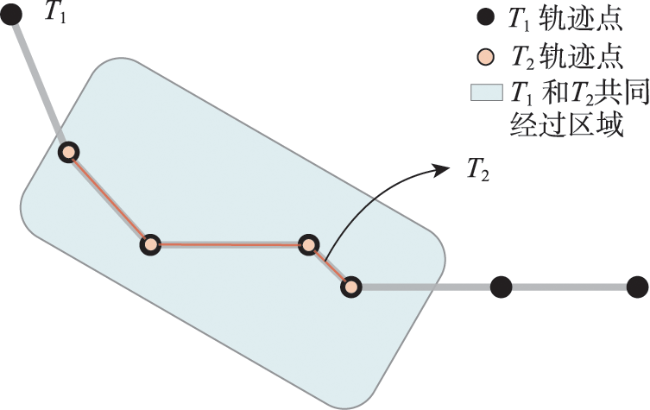
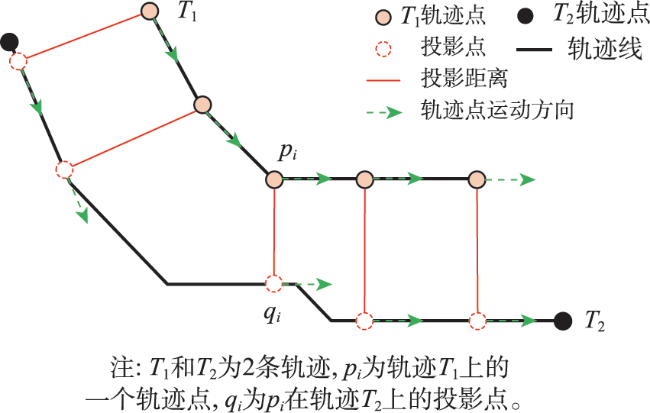
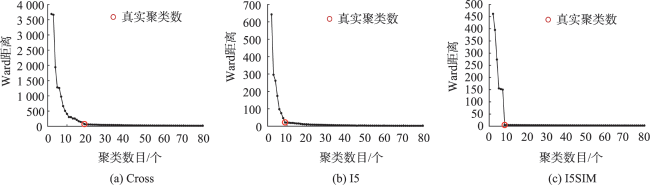
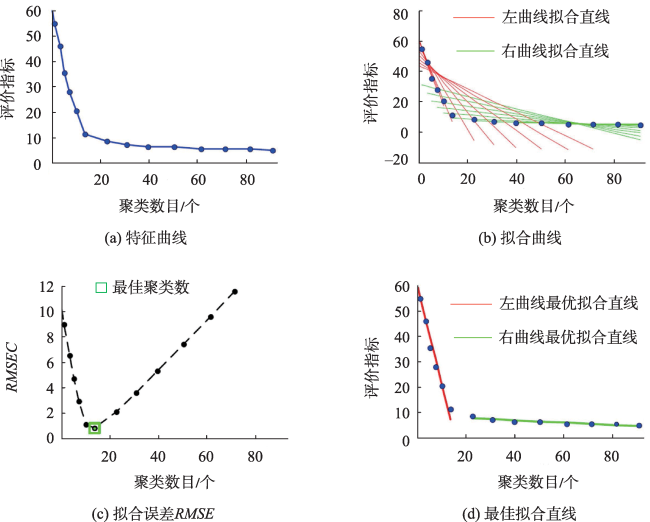
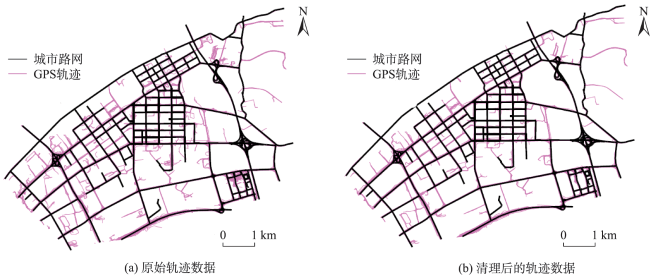
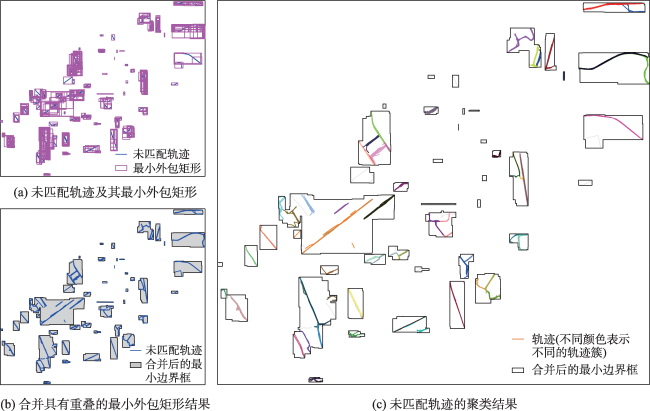
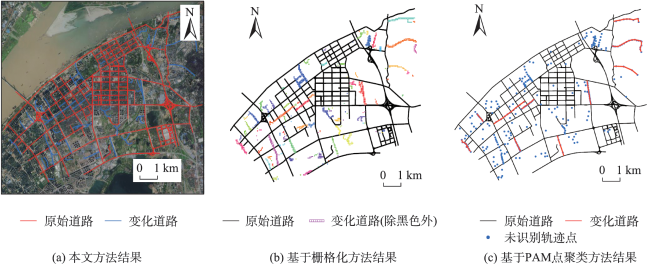
轨迹聚类是空间数据挖掘领域的一个研究热点,对城市交通规划、路网结构提取与更新等具有重要意义。轨迹聚类包括轨迹相似性度量和聚类参数设置2个核心问题。然而,由于轨迹的形态结构特征复杂,现有轨迹相似性度量指标存在对噪声敏感或未充分考虑轨迹运动方向一致性的问题,且大多数聚类算法仍需人为设置参数,聚类挖掘结果的质量受到用户主观经验的影响。针对上述问题,本文提出了一种融合多特征的移动轨迹自适应聚类方法。首先,通过融合轨迹的空间邻近性和运动方向特征定义了一种对噪声鲁棒的轨迹相似性度量指标—DSPD距离;在此基础上,通过扩展Ward层次聚类方法提出了一种基于中心轨迹概念的空间层次聚类算法,该算法使用DSPD距离作为相似性度量指标,利用聚类特征曲线自动确定最佳聚类参数。以11组模拟轨迹数据和武汉市真实轨迹数据为例进行实验与分析,结果表明,本文方法在顾及空间邻近性的基础上,可以有效区分不同移动方向的轨迹簇,同时,利用轨迹数据特征自动确定聚类参数,降低了挖掘结果的主观性。

刘敬一 , 彭举 , 唐建波 , 胡致远 , 郭琦 , 姚晨 , 陈金勇 . 融合多特征的轨迹数据自适应聚类方法[J]. 地球信息科学学报, 2023 , 25(7) : 1363 -1377 . DOI: 10.12082/dqxxkx.2023.230066
Trajectory clustering is a hot research topic in the field of spatial data mining, which is of great significance to many applications such as urban traffic control, road network construction and update. Trajectory clustering involves grouping similar trajectories into clusters where trajectory similarity measurement and clustering parameter setting are two core issues in the process of clustering. However, due to the complex morphological and structural characteristics of trajectories, the existing trajectory similarity measures are sensitive to noise or do not fully consider the consistency of trajectory motion direction. In addition, most clustering algorithms still need to manually set parameters, and the quality of clustering results is affected by the subjective experience of users. To address the above problems, this paper proposes an adaptive trajectory clustering algorithm. The proposed algorithm has two main components: a new trajectory similarity measure called Directed Segment-Path Distance (DSPD) and an improved hierarchical clustering algorithm based on the concept of central trajectory. The DSPD metric is a fusion of the spatial proximity and motion direction features of trajectories, providing a robust similarity measure. The enhanced hierarchical clustering algorithm extends the Ward hierarchical clustering algorithm by defining central trajectories and use the DSPD metric as the trajectory similarity measure. In addition, the proposed algorithm also utilizes the clustering characteristic curve to determine the optimal clustering parameters automatically. This eliminates the need for manual parameter tuning and reduces the subjectivity of clustering results. To evaluate the effectiveness of the proposed algorithm, experiments were conducted on both the simulated datasets and real-world trajectories of Wuhan. We first compared the effect of the DSPD with other commonly used trajectory similarity measures (i.e., Hausdorff distance, Fréchet distance, DTW distance, and LCSS distance) using the same clustering algorithm on the 11 sets of simulated datasets. The evaluation was based on the Adjusted Rand Index (ARI). Then we conducted another comparative analysis to access the effectiveness of the improved clustering algorithm in contrast to an average link-based hierarchical clustering algorithm. Finally, to verify the practicability of the proposed algorithm, we applied it to the process of road network updating. The experimental results show that the proposed DSPD measure outperforms alternative distance metrics on the ARI evaluation indicator. It can effectively distinguish moving trajectory clusters in different directions while considering the spatial proximity of trajectories, thus enhancing the accuracy and effect of the trajectory clustering. Furthermore, the proposed algorithm can significantly reduce the subjectivity of clustering results and provide suggestions for practical applications such as urban road network extraction and update.
| 算法1 基于中心轨迹概念的层次聚类算法 |
|---|
| Input: (a)移动轨迹数据集S (b)聚类数目k Output:轨迹簇TC1, TC2, …, TCk 1. 将S中的每个轨迹作为单独的簇,记为TC1, TC2, …, TCN,其中N为当前轨迹簇的数目; 2. 根据式(9)计算每个轨迹簇的中心轨迹; 3. 基于各簇的中心轨迹,根据式(10)计算轨迹簇间的Ward距离D(TCi, TCj)(1 ≤ i ≤ N,1 ≤ j ≤ N, j ≠ i); 4. 合并Ward距离最小的2个轨迹簇,如{TCi, TCj}=TCi(i < j),并删除TCj,使轨迹簇的数目N减1; 5. 重复执行2、3、4步骤,直到当前轨迹簇的数目N为k时停止; 6. 返回最后生成的k个轨迹簇,记为TC1, TC2, …, TCk,算法结束。 |
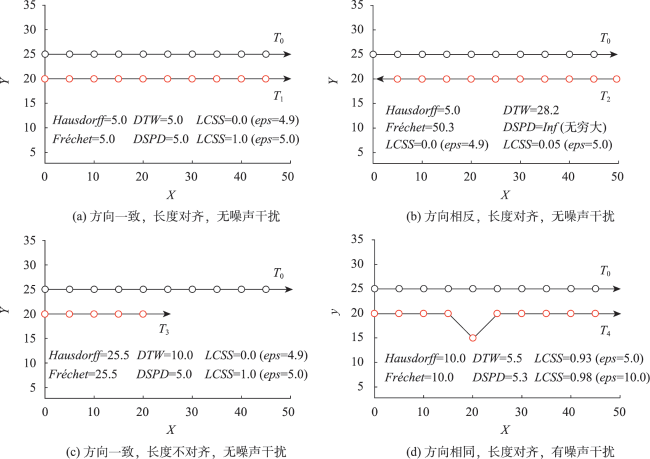
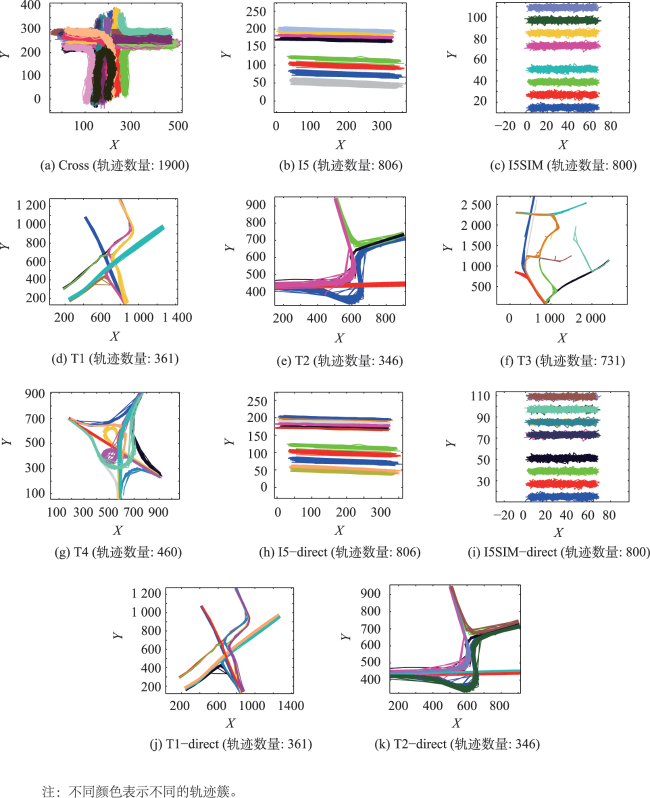
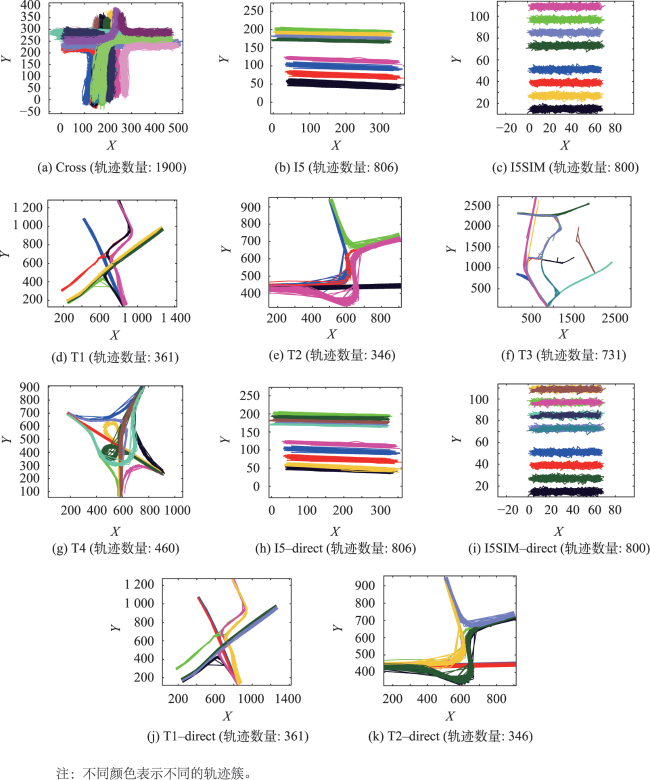
表1 不同相似性度量指标下模拟轨迹数据的聚类结果的有效性评价Tab. 1 Validity evaluation of cluster results for simulated trajectory datasets under different similarity metrics |
| 簇数/个 | Hausdorff | Fréchet | DTW | LCSS | DSPD | |
|---|---|---|---|---|---|---|
| Cross | 19 | 0.993 | 0.996 | 0.939 | 0.841 | 0.896 |
| I5 | 8 | 0.387 | 0.388 | 0.669 | 0.962 | 0.987 |
| I5SIM | 8 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| T1 | 7 | 0.466 | 0.575 | 0.575 | 0.948 | 0.885 |
| T2 | 5 | 0.578 | 0.775 | 0.747 | 0.983 | 1.000 |
| T3 | 10 | 0.621 | 0.665 | 0.809 | 0.953 | 0.960 |
| T4 | 10 | 0.831 | 0.679 | 0.712 | 0.833 | 0.993 |
| I5-direct | 11 | 0.194 | 0.297 | 0.460 | 0.814 | 0.839 |
| I5SIM-direct | 12 | 0.874 | 1.000 | 1.000 | 1.000 | 1.000 |
| T1-direct | 10 | 0.545 | 0.589 | 0.651 | 0.988 | 0.957 |
| T2-direct | 9 | 0.602 | 0.660 | 0.570 | 0.963 | 0.975 |
| 平均精度 | - | 0.645 | 0.693 | 0.739 | 0.935 | 0.954 |
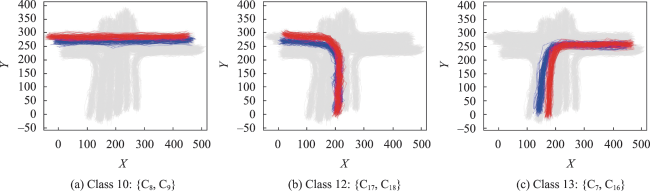
图8 模拟数据的聚类结果Fig. 8 Clustering results by the proposed method with different clusters in different colors |
表2 模拟轨迹数据聚类结果的有效性评价Tab. 2 Validity evaluation of cluster results for simulated trajectory datasets |
| 模拟数据 | 簇数/个 | 聚类参数k估计值 | ARI | 模拟数据 | 簇数/个 | 聚类参数k估计值 | ARI |
|---|---|---|---|---|---|---|---|
| Cross | 19 | 16 | 0.852 | T4 | 10 | 10 | 0.993 |
| I5 | 8 | 8 | 0.993 | I5-direct | 11 | 10 | 0.961 |
| I5SIM | 8 | 8 | 1.000 | I5SIM-direct | 12 | 12 | 1.000 |
| T1 | 7 | 7 | 0.912 | T1-direct | 8 | 8 | 0.861 |
| T2 | 5 | 5 | 1.000 | T2-direct | 9 | 8 | 0.965 |
| T3 | 10 | 11 | 0.982 |
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
郑宇. 城市计算概述[J]. 武汉大学学报·信息科学版, 2015, 40(1):1-13.
[
|
| [6] |
|
| [7] |
刘瑜, 康朝贵, 王法辉. 大数据驱动的人类移动模式和模型研究[J]. 武汉大学学报·信息科学版, 2014, 39(6):660-666.
[
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
牟乃夏, 徐玉静, 张恒才, 等. 移动轨迹聚类方法研究综述[J]. 测绘通报, 2018, 0(1):1-7.
[
|
| [13] |
|
| [14] |
|
| [15] |
朱燕, 李宏伟, 樊超, 等. 基于聚类的出租车异常轨迹检测[J]. 计算机工程, 2017, 43(2):16-20.
[
|
| [16] |
|
| [17] |
代维秀, 陈占龙, 谢鹏. 居民出行与轨迹行为交互模式挖掘与关联技术[J]. 测绘学报, 2021, 50(4):532-543.
[
|
| [18] |
|
| [19] |
杨伟, 艾廷华. 运用约束Delaunay三角网从众源轨迹线提取道路边界[J]. 测绘学报, 2017, 46(2):237-245.
[
|
| [20] |
李渊, 郭晶, 陈一平. 基于多源数据的旅游者视觉行为模式与感知评估方法[J]. 地球信息科学学报, 2022, 24(10):2004-2020.
[
|
| [21] |
杨伟, 艾廷华. 基于车辆轨迹大数据的道路网更新方法研究[J]. 计算机研究与发展, 2016, 53(12):2681-2693.
[
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
Vijaya,
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
|
| [51] |
|
| [52] |
|
| [53] |
|
| [54] |
吴涛, 向隆刚, 龚健雅. 路网更新的轨迹-地图匹配方法[J]. 测绘学报, 2017, 46(4):507-515.
[
|
| [55] |
|
| [56] |
|
| [57] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}