
一种集成词汇-结构-语义表示的地址匹配策略
|
亢孟军(1983— ),男,河南三门峡人,副教授,博导,研究方向为空间信息可视化、地名地址处理、地理信息软件开发、地理智能计算。E-mail: mengjunk@whu.edu.cn |
收稿日期: 2022-10-13
修回日期: 2022-11-30
网络出版日期: 2023-06-30
基金资助
自然资源部城市国土资源监测与仿真重点实验室开放基金资助课题(KF-2019-04-064)
国家重点研发计划项目(2022YFC3005700)
An Integrated Processing Strategy Considering Vocabulary, Structure and Semantic Representation for Address Matching
Received date: 2022-10-13
Revised date: 2022-11-30
Online published: 2023-06-30
Supported by
The Open Fund of Key Laboratory of Urban Land Resources Monitoring and Simulation, Ministry of Natural Resources(KF-2019-04-064)
National Key Research and Development Program of China(2022YFC3005700)
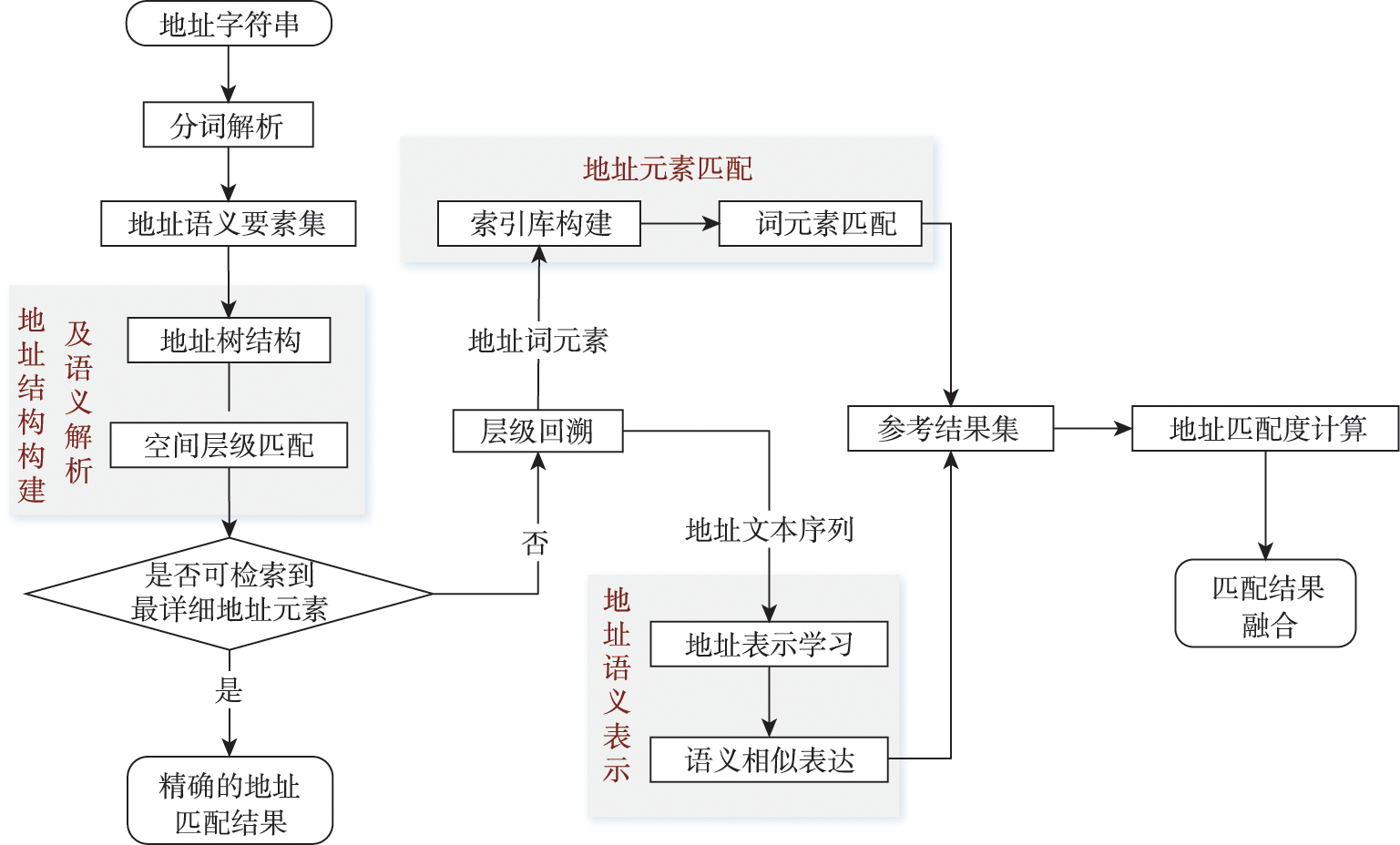
地址匹配是地理编码的核心基础,本文针对现有地址匹配算法与地址数据库反馈交互局限性问题,提出词汇-结构-语义三层解构地址的匹配处理策略。词汇层通过地名词典和结合尾字特征的正则表达式定义粒度剖分规则,以地址词元素为基本单元完成词汇级别解析;结构层定义地址模式类型以实例化数据组织,完成顾及上下地址层级结构的模型匹配;语义层抽象地址语义形式化表达,实现融合深度语义的地址匹配。同时,本文在综合地址词元素筛选、地址层级结构剖分和地址语义理解基础上对经过完全解析的地址数据不断反哺作为数据参考,从而实现数据库支持下的算法逻辑绑定与结果集成。本文以浙江省湖州市德清县地址数据作为实例进行验证,实验结果表明,在低重复率的多次采样实验下,平均匹配率达到92.83%,正确率为95.37%;通过实例分析表明,本文方法在完善地址参考库的基础上改进算法性能和精度,能有效解决地址结构缺失和语义近似推断,适应多样地址类型。
亢孟军 , 何欣阳 , 刘诚 , 王明军 , 高宇灵 . 一种集成词汇-结构-语义表示的地址匹配策略[J]. 地球信息科学学报, 2023 , 25(7) : 1378 -1385 . DOI: 10.12082/dqxxkx.2023.220784
Address matching refers to the process of matching the description address with the address in the standard address library, which is the core foundation of geocoding. It can convert the location description information into spatial coordinates, so as to build the association between texts and coordinates. Usually, Chinese address data has the problems of ambiguous expression, low standardization, and poor overall data quality. The current situation of Chinese data have greatly increased the construction cost of address reference library, which puts forward higher requirements for address matching algorithms and prompts the exploration of adopting integrated address matching strategies in practice. According to the fact that there has limited interaction between the existing address matching algorithms and address database feedback, this paper presents an integrated processing strategy for address matching. It describes a progressive logical matching strategy from vocabulary, structure, and semantics levels, which can support data organization while realizing deep text parsing. The vocabulary level parses the address structure to achieve word segmentation and text filtering from the character perspective; The structure level defines data organization of the address model and completes the quick indexing under hierarchical structure; The semantic level is the formal expression of address semantics, integrating semantic understanding and information extraction methods. Besides, on the basis of comprehensive address element filtering, hierarchical structure subdivision, and semantic understanding, we continuously feed back the fully parsed address data as reference to achieve the algorithm logic binding and results integration supported by the database. Thus, the efficiency of engine construction and the quality of algorithm are effectively improved. In order to verify our proposed strategy,we select the address data of Deqing County, Huzhou City, Zhejiang Province to carry out a comparison experiment. The results show that our strategy achieves stable and satisfied results indicated by matching rate, accuracy, and time indicators. Compared with the classical address matching algorithms, our strategy has obvious advantages in increasing the accuracy and saving time. The average matching rate is 92.83%, and the accuracy rate is 95.37%, under the low repetition rate multiple sampling experiment. Our results indicate that the proposed strategy can effectively solve the matching problems such as address element missing and approximate semantic calculation and improve the matching degree, matching rate, and matching efficiency. For addressing text elements that may indicate multiple spatial meanings, it is necessary to further combine spatial topology analysis to optimize the accuracy of address element recognition.
表1 地址模式形式化表达Tab. 1 Formal epression of address model |
| 要素类别 | 形式化表达 | 描述 |
|---|---|---|
| 线状拓扑类 | 存在线性拓扑关系的类别,以道路门牌号为主 | |
| 面状拓扑类 | 存在面状拓扑关系的类别,以大型社区为主 | |
| 楼栋类 | 具体到楼栋单体的地理要素 | |
| 单元类 | 指在多单元的楼栋中明确单元位置的类别 | |
| 楼层类 | 明确楼层的类别 | |
| 户号类 | 明确某楼层具体户号的类别。 | |
| 地标类 | 指呈面状或点状形态的地址元素类别 | |
| 方位描述 | 指描述与某一具体位置相关方位的描述词 | |
| 距离描述 | 指描述与某一具体位置相关距离的描述词 |
表2 地址元素类别常见组合Tab. 2 Common combinations of address categories |
| 组合方式 | 示例 |
|---|---|
| + | 三里湾路1号 |
| + + | 三里湾路1-1号 |
| + + | 西郊路192号庆元新村 |
| + + + | 西郊路192-1号庆元新村 |
| + + + | 环城北路142号德意房产1幢 |
| + + + | 环城北路128号10幢3单元 |
| + + + + | 环城北路128号10幢3单元101室 |
表3 地址匹配度统计结果Tab. 3 Statistics of address match degree |
| 匹配度区间 | 样本1 | 样本2 | 样本3 | |||||
|---|---|---|---|---|---|---|---|---|
| 匹配条目 | 匹配率/% | 匹配条目 | 匹配率/% | 匹配条目 | 匹配率/% | |||
| <60% | 196 | 1.96 | 145 | 1.45 | 120 | 1.20 | ||
| 60%~75% | 241 | 2.41 | 223 | 2.23 | 243 | 2.43 | ||
| 75%~85% | 326 | 3.26 | 294 | 2.94 | 364 | 3.64 | ||
| 85%~100% | 9 237 | 92.37 | 9 338 | 93.38 | 9 273 | 92.73 | ||
| 总条目/条 | 10 000 | 10 000 | 10 000 | |||||
表4 地址匹配实验结果Tab. 4 Experimental result of address matching |
| 数据集 | 匹配率/% | 正确率/% | 时间/s |
|---|---|---|---|
| 样本1 | 92.37 | 95.52 | 0.101 9 |
| 样本2 | 93.38 | 95.15 | 0.109 7 |
| 样本3 | 93.73 | 95.43 | 0.102 8 |
| 平均值 | 92.83 | 95.37 | 0.104 8 |
表5 随机样本重复度Tab. 5 Repeatability of random sample |
| 数据集 | 重复率/% |
|---|---|
| 样本1-样本2 | 3.21 |
| 样本1-样本3 | 2.95 |
| 样本2-样本3 | 2.96 |
表6 成功匹配的地址示例Tab. 6 Examples of successfully matched addresses |
| 原地址 | 说明 | 匹配结果 |
|---|---|---|
| 武康街道余英坊2幢1号 | 地址要素不完整,缺少“吉祥社区”级别地址要素 | 浙江省湖州市德清县武康街道吉祥社区余英坊2幢1号室 |
| 兴康南路88号 | 地址要素不完整,仅有“道路+门牌号”级地址要素 | 浙江省湖州市德清县武康街道祥和社区兴康南路88号 |
| 雷甸镇新立村外婆桥 | 存在地址要素文本书写错误,错别字“新立村”为“新利村” | 浙江省湖州市德清县雷甸镇新利村外婆桥6号 |
| 武康镇欧诗漫街65-1号 | 存在同义词 “武康镇”与“武康街道” | 浙江省湖州市德清县武康街道振兴社区欧诗漫街65-1号 |
| 北湖东街266-1 | 缺少尾字特征“号” | 浙江省湖州市德清县阜溪街道北湖东街266-1号 |
| 武康东升街 | 缺少尾字特征“街道” | 浙江省湖州市德清县武康街道春晖社区东升街 |
| 佳得利商贸城21幢2号 | 仅有POI要素 | 浙江省湖州市德清县武康街道振兴社区佳得利商贸城21幢 |
表7 不同匹配方法对比结果Tab. 7 Comparison of different matching methods |
| 匹配方法 | 匹配率/% | 正确率/% | 时间/s |
|---|---|---|---|
| 地址树 | 91.49 | 93.16 | 0.073 7 |
| 全文检索 | 89.35 | 92.99 | 0.128 1 |
| Word2Vec | 73.32 | 80.29 | 0.725 4 |
| 本文 | 92.83 | 95.37 | 0.104 8 |
| [1] |
|
| [2] |
Lan, Longley. Geo-referencing and mapping 1901 census addresses for England and Wales[J]. ISPRS International Journal of Geo-Information, 2019, 8(8):320. DOI:10.3390/ijgi8080320
|
| [3] |
|
| [4] |
|
| [5] |
张志军, 邱俊武, 亢孟军, 等. 城市地址模型概念框架的关键问题[J]. 测绘通报, 2018(9):96-102.
[
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
亢孟军, 杜清运, 王明军. 地址树模型的中文地址提取方法[J]. 测绘学报, 2015, 44(1):99-107.
[
|
| [12] |
|
| [13] |
张雪英, 闾国年, 李伯秋, 等. 基于规则的中文地址要素解析方法[J]. 地球信息科学学报, 2010, 12(1):9-16.
[
|
| [14] |
应申, 李威阳, 贺彪, 等. 基于城市地址树的地址文本匹配方法[J]. 地理信息世界, 2017, 24(6):81-86.
[
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
李晓林, 张懿, 李霖. 基于地址语义理解的中文地址识别方法[J]. 计算机工程与科学, 2019, 41(3):551-558.
[
|
| [22] |
|
| [23] |
宋子辉. 自然语言理解的中文地址匹配算法[J]. 遥感学报, 2013, 17(4):788-801.
[
|
| [24] |
徐流畅. 预训练深度学习架构下的语义地址匹配与语义空间融合模型研究[D]. 杭州: 浙江大学, 2020.
[
|
| [25] |
张琛, 陈张建, 刘江涛, 等. Lucene自适应分词的地址匹配方法改进与实现[J]. 测绘科学, 2021, 46(10):185-193.
[
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
钟艾妮. 基于Word2Vec的中文地址匹配[D]. 武汉: 武汉大学, 2020.
[
|
/
| 〈 |
|
〉 |

{kind=link}
{kind=link}