
网络游记文本中旅游行程链提取方法
|
阮 陵(1990— ),男,安徽铜陵人,博士,讲师,主要研究方向为旅游大数据分析、旅游地理分析等。 E-mail: rling1990@163.com |
Copy editor: 蒋树芳 黄光玉
收稿日期: 2023-09-21
修回日期: 2024-02-05
网络出版日期: 2024-03-27
基金资助
国家自然科学基金项目(42301258)
国家自然科学基金项目(42171403)
A Method of Itinerary Chain Extraction from Online Travel Notes
Received date: 2023-09-21
Revised date: 2024-02-05
Online published: 2024-03-27
Supported by
National Natural Science Foundation of China(42301258)
National Natural Science Foundation of China(42171403)
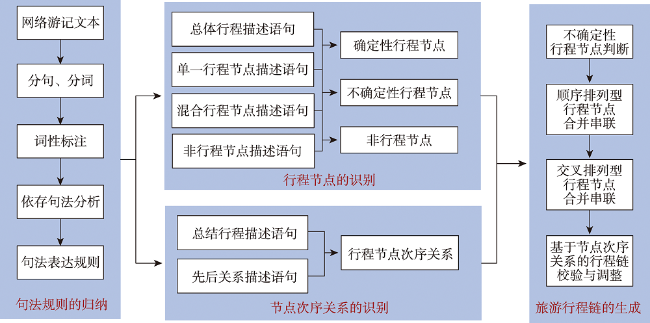
网络游记是旅游者在互联网上发布的自述性旅游过程记录,描述了旅游的前后过程和感受体验。从网络游记文本中提取旅游行程链,分析行程结构,能给游客的行程制定、线路设计提供重要的参考。传统的游记文本行程提取大多依赖于人工识别文本中的行程节点,再进行串联、合并处理,工作量较大。自动提取游记文本中的旅游行程链,能够提高数据处理和分析效率。本文基于自然语言处理技术,在深入分析游记网络文本的段落结构和表达特点的基础上,归纳了行程节点和节点次序关系的句法表达规则,构建了行程节点触发词表,进而提出了基于句法规则的旅游行程链提取方法,主要包含行程节点的识别、节点次序关系的识别和旅游行程链的生成,能实现网络游记文本的旅游行程重构。本文采集了蚂蜂窝平台17 226篇南京市网络游记文本数据,采用最长公共子序列算法,开展了本文方法的试验验证。通过对比分析,本文方法提取的旅游行程链和人工识别的真实行程链相似度达到86.14%,高于实体关系抽取领域的BERT-BiLSTM-CasRel深度学习模型的83.1%。相比现有关系提取类深度学习方法需要开展大量的数据标注,本文方法计算更加便捷,准确率相对较高,仅需构建区域旅游点名录,即可实现网络游记文本中行程信息的自动提取。
阮陵 , 葛军莲 , 张翎 , 王黎淑 , 王晓宣 . 网络游记文本中旅游行程链提取方法[J]. 地球信息科学学报, 2024 , 26(2) : 477 -487 . DOI: 10.12082/dqxxkx.2024.230570
. Online travel notes are self-reported records published by tourists on the Internet, which describe the process of their trip and experience. Extracting itinerary chain from online travel notes and analyzing itinerary structure, can provide important reference for tourists' itinerary formulation and route design. The traditional itinerary extraction mostly relies on manual recognition, and some methods proposed in current studies require extensive data annotation, which is a large workload. Automatic extraction of itinerary chain from online travel notes accurately can improve the efficiency of data processing, which is an open issue and worth of study. In this paper, a syntactic rule-based travel chain extraction method was proposed based on natural language processing technology, which includes the identification of travel nodes, the recognition of nodes order and the generation of itinerary chain. First of all, the paragraph structure and expression characteristics of itinerary in online travel notes were analyzed, and the syntactic expression rules of travel nodes and nodes order were summarized based on word segmentation and dependency syntax analysis of related statements. Secondly, the travel nodes matched by syntactic rules, can be divided into deterministic travel nodes, uncertain travel nodes and non-travel nodes. Thirdly, through regular expression and syntactic rules match, the order of travel nodes was recognized from the specific itinerary description statement. Finally, the uncertain travel nodes were distinguished based on nodes context analysis, and the sequential and cross-arranged travel nodes were merged and connected in series. Meanwhile, the order of nodes in the connected series were verified and adjusted based on previously recognized node orders, and the itinerary chain was generated. In order to verify the effectiveness of proposed method, 17 226 online travel notes text data of Nanjing city were collected on Mafengwo platform, and the longest common subsequence algorithm was used to carry out the experimental verification. Through comparative analysis, the similarity between the extracted result by this method and the real travel chain identified by manual is 86.14%, which is higher than the BERT-BiLSTM-CasRel deep learning model in the field of entity relation extraction (83.1%). Compared with the existed relation extraction method in deep learning field, the proposed method is more convenient in calculation and does not require extensive data annotation. The limitation of method is the construction of regional travel site directory. In the future work, the strong semantic understanding ability of large language model would be carried out to improve the accuracy and data processing efficiency in itinerary chain extraction.
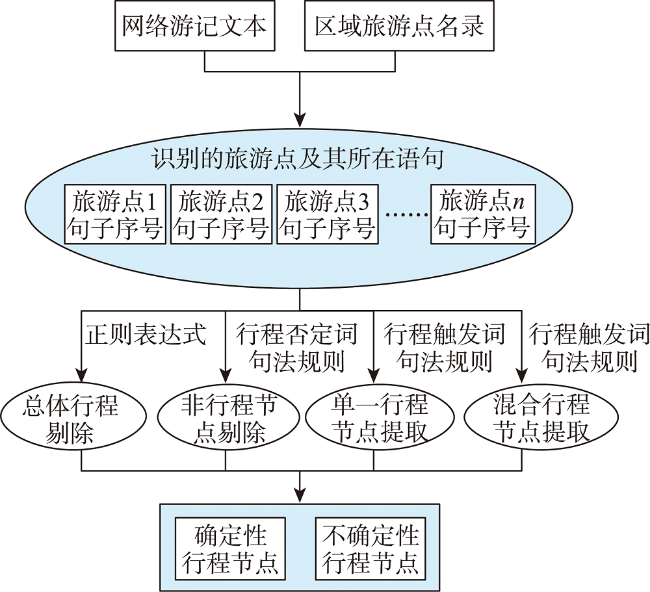
表1 旅游点在游记文本中的表达形式Tab.1 The expression of scenic spots in online travel notes |
| 序号 | 类型 | 示例语句 | 句法结构特征 |
|---|---|---|---|
| 1 | 总体行程 | (1)第一天,中山陵,明孝陵,美龄馆,音乐台 (2)中山陵-明孝陵-灵谷寺-美龄宫 | 多个旅游点在一句话中连续排列 |
| 2 | 单一行程 节点 | (1)办理完取车后续后,直接去了夫子庙景区。 (2)吃完早餐,出发去了总统府 | “去、前往、逛”等助动词和旅游点构成动宾关系 |
| (1)栖霞山是个好地方,环境清幽,空气好,人少 (2)牛首山的景色确实不错,景区里面有游览车,不想走路可以坐游览车 (3)南京庙山湖。适合喜欢拍照的人前往打卡,没有人没有店没有喧嚣,只有一片 安静的风景 | 旅游点是主语或者主语的定语,结构为主谓关系 | ||
| 3 | 非行程 节点 | (1)我是下午2点左右到明孝陵,后边没有时间去音乐台和中山陵了 (2)今天计划是去南京博物院,却发现门票已经预约完了 (3)本来打算跟我妈去旁边的瞻园逛逛,老妈兴趣不大,拉着我要去买咸水鸭 | “没有、计划、本来、打算”等排除词衔接旅游点 |
| 4 | 混合行程 节点 | (1)玄武湖公园西靠明城墙,是中国最大的皇家园林湖泊 (2)音乐台在中山陵的东南角,非常近,从中山陵出来往前走一会便是 | 旅游点作为空间参照,方位词的定语 |
| (1)可能很多人去过中山陵、明孝陵,未必知道旁边藏着这美龄宫 (2)莫愁湖位于南京水西门外,相比于玄武湖,这里的人流量要少的多 | 旅游点用于语义对比,语义关联,句法结构不明显 |
表2 旅游点识别的句法规则Tab. 2 The syntactic rules of tourist spot recognition |
| 编号 | 规则名称 | 句法化 | 句法规则 |
|---|---|---|---|
| 1 | 总体行程描述 | <旅游点>+<连接字符>+<旅游点> | tp/cs/tp/cs |
| 2 | 行程触发词加旅游点 | <行程触发词>+<助动词>+<旅游点> | iw/u/tp |
| 3 | 旅游点单独成句 | <旅游点> | tp |
| 4 | 旅游点是句子的主语 | <旅游点>+<动词>+<名词> | tp/v/n |
| 5 | 旅游点是主语的定语 | <旅游点>+<助动词>+<名词> | tp/u/n |
| 6 | 行程否定词加旅游点 | <排除词>+<动词>+<旅游点> | nw/v/tp |
注:tp表示旅游点;iw表示行程触发词;nw表示行程否定词;cs表示连接字符;u表示助动词;n表示名词。 |
表3 行程触发词和行程否定词Tab.3 Travel trigger words and travel negative words |
| 词表类别 | 主要内容 |
|---|---|
| 行程触发词 | 前往,逛,站在,到,来,回,去,奔,上,爬,转,走,步,至,游,看,玩,经过,路过,离开,出来,走后,出去,走完,逛完,看完,去过,到达 |
| 行程否定词 | 本来,打算,计划,可能,忘,忘记,忘了,没有 |
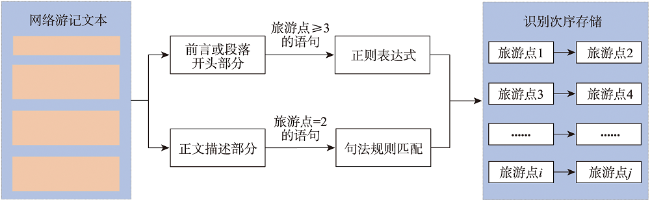
表4 节点次序关系识别的规则Tab.4 Rules for travel node sequence relation identification |
| 编号 | 规则名称 | 句法规则 |
|---|---|---|
| 1 | 总体行程 描述 | 正则表达式:[\u4e00-\u9fff]+(?:[-,→、→])[\u4e00-\u9fff]+(?:[-,→、→])*[\u4e00-\u9fff]+ |
| 2 | 先后次序 描述 | “从”+<旅游点>+“到”+<旅游点>,“离开”+<旅游点>+“到”+<旅游点>,“出了”+<旅游点>+“到”+<旅游点>,<旅游点>+“至”+<旅游点>,<旅游点>+“之后”+“到”+<旅游点>,“过了”+<旅游点>+“就是”+<旅游点>等 |
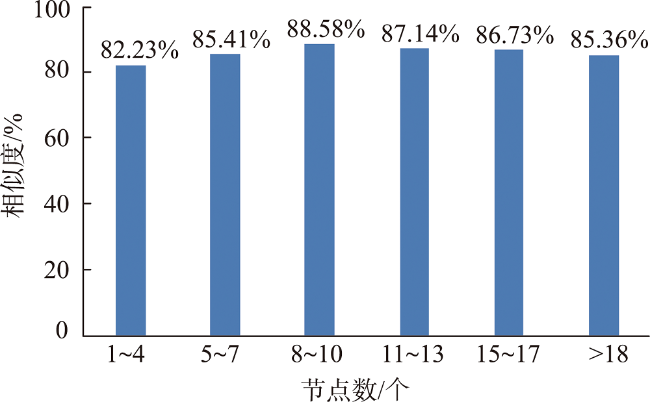
图7 不同节点数量游记文本中行程链提取的相似度分布Fig. 7 The similarity between automatic and manual extracted in different number of nodes |
表5 基于句法规则提取的行程节点和真实行程节点的对比(部分实例)Tab. 5 The comparison of extracted and real travel nodes (partial sample) |
| 序号 | 来源 | 行程节点 | 相似度/% |
|---|---|---|---|
| 1 | 提取行程 | 南京大排档→先锋书店→夫子庙→南京大屠杀纪念馆→美术馆 | 100.00 |
| 真实行程 | 南京大排档→先锋书店→夫子庙→南京大屠杀纪念馆→美术馆 | ||
| 2 | 提取行程 | 总统府→中山陵→明孝陵→美龄宫→乌衣巷→江南贡院→牛首山 | 87.50 |
| 真实行程 | 总统府→中山陵→明孝陵→美龄宫→乌衣巷→江南贡院→夫子庙→牛首山 | ||
| 3 | 提取行程 | 中山陵→明孝陵→美龄宫→夫子庙→南京博物院→南京大屠杀纪念馆 | 85.71 |
| 真实行程 | 中山陵→明孝陵→美龄宫→夫子庙→南京博物院→南京大屠杀纪念馆→南京长江大桥 | ||
| 4 | 提取行程 | 秦淮河→夫子庙→鸡鸣寺→总统府→南京博物院→大报恩寺 | 85.71 |
| 真实行程 | 秦淮河→夫子庙→白鹭洲公园→鸡鸣寺→总统府→南京博物院→大报恩寺 | ||
| 5 | 提取行程 | 总统府→1912街区→夫子庙→音乐台→中山陵→美龄宫→鸡鸣寺→玄武湖 | 88.89 |
| 真实行程 | 总统府→1912街区→夫子庙→秦淮河→音乐台→中山陵→美龄宫→鸡鸣寺→玄武湖 | ||
| 6 | 提取行程 | 大报恩寺→南京大牌档→夫子庙→江南贡院→秦淮河→颐和路→西桥→老门东→明孝陵→石象路→梅花山→鸡鸣寺 | 90.90 |
| 真实行程 | 大报恩寺→南京大牌档→夫子庙→江南贡院→秦淮河→颐和路→西桥→老门东→明孝陵→石象路→梅花山 | ||
| 7 | 提取行程 | 明孝陵→石象路→翁仲路神道→孙权纪念馆→孝陵殿→中山陵→音乐台→灵谷寺→美龄宫 | 69.23 |
| 真实行程 | 明孝陵→长生鹿苑→石象路→翁仲路神道→孙权纪念馆→碑殿→孝陵殿→中山陵→音乐台→灵谷寺→ 灵谷塔→无梁殿→美龄宫 |
注:表中红色字表示真实行程中漏提取的节点。 |
| [1] |
陈培, 张红, 杜雪楠. 基于网络游记的城市旅游目的地形象探究——以西安市为例[J]. 资源开发与市场, 2014, 30(11):1401-1404.
[
|
| [2] |
郎朗. “地方” 理论视角下的网络游记研究——以北京三里屯游记分析为例[J]. 旅游学刊, 2018, 33(9):49-57.
[
|
| [3] |
胡传东, 李露苗, 罗尚焜. 基于网络游记内容分析的风景道骑行体验研究——以318国道川藏线为例[J]. 旅游学刊, 2015, 30(11):99-110.
[
|
| [4] |
梁嘉祺, 姜珊, 陶犁. 基于网络游记语义分析和GIS可视化的游客时空行为与情绪关系实证研究——以北京市为例[J]. 人文地理, 2020, 35(2):152-160.
[
|
| [5] |
周李, 吴殿廷, 虞虎, 等. 基于网络游记的城市旅游流网络结构演化研究——以北京市为例[J]. 地理科学, 2020, 40(2):298-307.
[
|
| [6] |
闫闪闪, 张河清, 靳诚. 都市区国内旅游流网络空间关联特征[J]. 热带地理, 2021, 41(6):1313-1324.
[
|
| [7] |
柯景怡, 周子涵, 张高军. 传统节点与新型节点:深圳旅游流网络结构[J]. 陕西师范大学学报(自然科学版), 2023, 51(2):47-58.
[
|
| [8] |
|
| [9] |
刘大均. 基于游记文本的成都市亲子旅游流网络结构特征[J]. 经济地理, 2022, 42(10):224-230.
[
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
高翔, 陈炜. 旅游目的地游客满意度模型新释——基于桂林网络游记的扎根分析[J]. 旅游研究, 2017, 9(5):78-86.
[
|
| [14] |
曹李梅, 曲颖. 热带海岛型目的地情境下旅游者地方依恋:心理归因及其形成机理[J]. 人文地理, 2019, 34(5):135-141,158.
[
|
| [15] |
周慧玲, 许春晓. 基于游记行程的湖南旅游流空间网络结构特征[J]. 经济地理, 2016(10):201-206.
[
|
| [16] |
李艳. 网络游记中地方热度特产信息的抽取方法研究[J]. 微型电脑应用, 2017, 33(10):33-36.
[
|
| [17] |
姚占雷, 许鑫, 李丽梅, 等. 网络游记中的景区共现现象分析——以华东地区首批国家5A级旅游景区为例[J]. 旅游科学, 2011, 25(2):39-46,72.
[
|
| [18] |
廖启鹏, 刘超, 李维. 游客记忆视角的景观关注度研究——以黄山风景区为例[J]. 人文地理, 2019, 34(6):129-135.
[
|
| [19] |
曹阳. 城市旅游规划行程链的模型构建及其应用研究[D]. 南京: 南京师范大学, 2014.
[
|
| [20] |
曹阳, 葛军莲, 龙毅, 等. 时空协同的城市旅游行程规划模型构建[J]. 地球信息科学学报, 2019, 21(6):814-825.
[
|
| [21] |
李洋, 李实. 自然语言处理入门[M]. 北京: 清华大学出版社, 2024.
[
|
| [22] |
余丽, 陆锋, 张恒才. 网络文本蕴涵地理信息抽取:研究进展与展望[J]. 地球信息科学学报, 2015, 17(2):127-134.
[
|
| [23] |
曹青, 洪必文, 张翎, 等. 基于自然语言空间关系描述的地图近似表达方法[J]. 地球信息科学学报, 2018, 20(11):1541-1549.
[
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
高原, 施元磊, 张蕾, 等. 基于游记文本的游客游览行程重构[J]. 数据分析与知识发现, 2020, 4(2):165-172.
[
|
| [29] |
|
| [30] |
于海英, 赵俊岚. 最长公共子序列算法在程序代码相似度度量中的应用[J]. 内蒙古大学学报(自然科学版), 2008, 39(2):225-229.
[
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}