
违背不相关性假设对Triple Collocation方法精度的影响
|
谈松林(2000— ),男,江苏南京人,硕士生,主要从事水文水资源方面与Collocation方法的研究。E-mail: tsl424@foxmail.com |
Copy editor: 蒋树芳
收稿日期: 2023-08-28
修回日期: 2023-11-10
网络出版日期: 2024-03-31
基金资助
国家自然科学基金项目(41877158)
河北省省级科技计划资助项目(19275408D)
江苏省水利科技项目(2020040)
Investigating the Impact of Violations in Orthogonality and Zero Cross-Correlation Assumption upon the Accuracy of Triple Collocation Methods
Received date: 2023-08-28
Revised date: 2023-11-10
Online published: 2024-03-31
Supported by
National Natural Science Foundation of China(41877158)
S&T Program of Hebei(19275408D)
Jiangsu Water Conservancy Science and Technology Project(2020040)
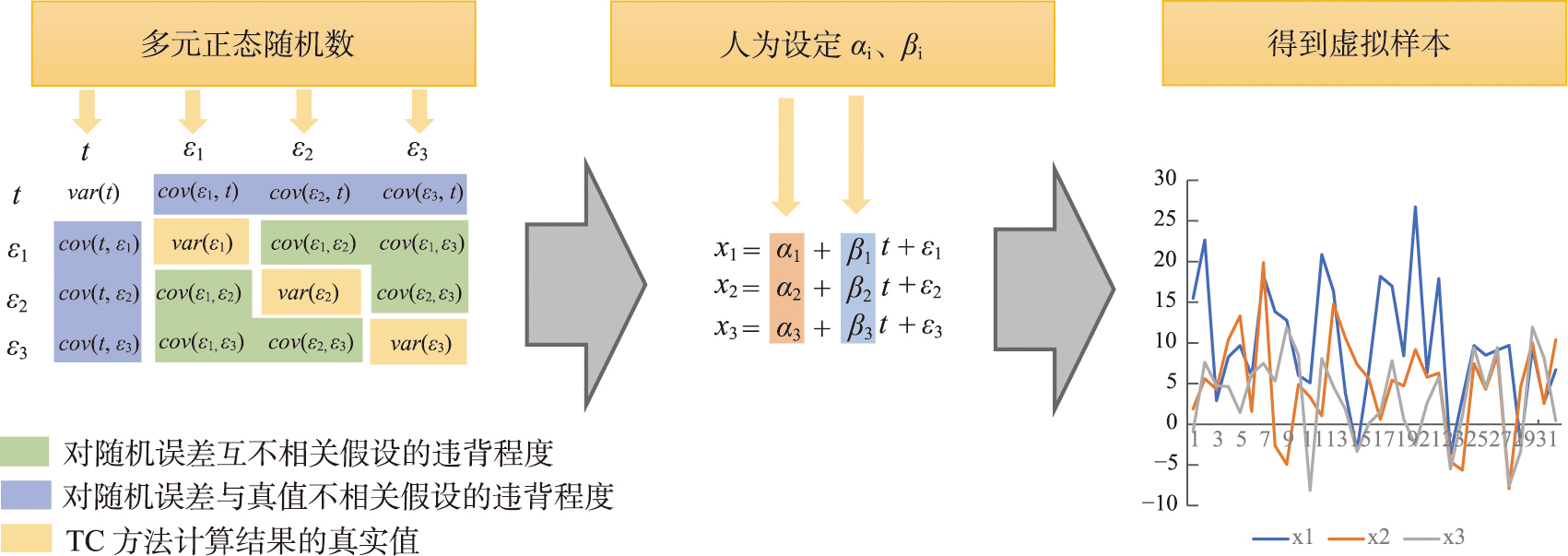
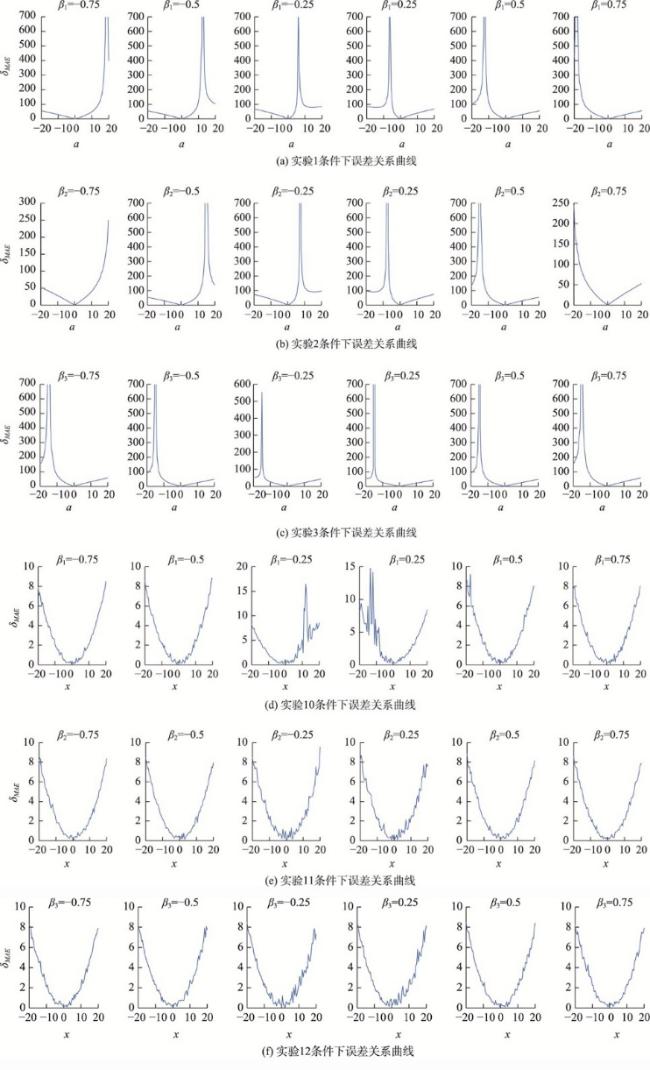
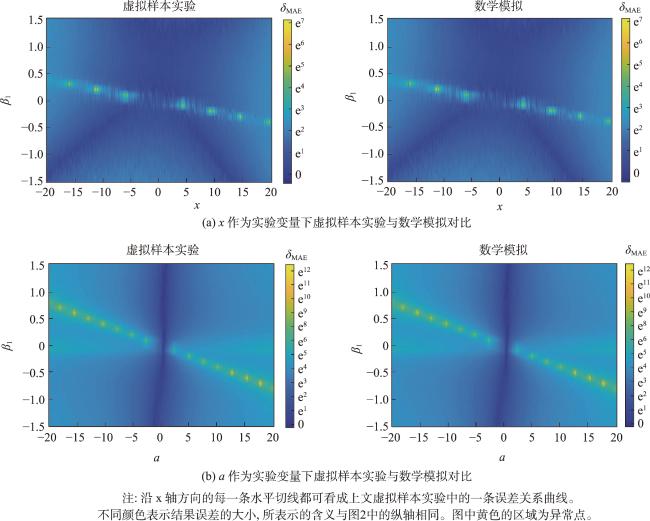
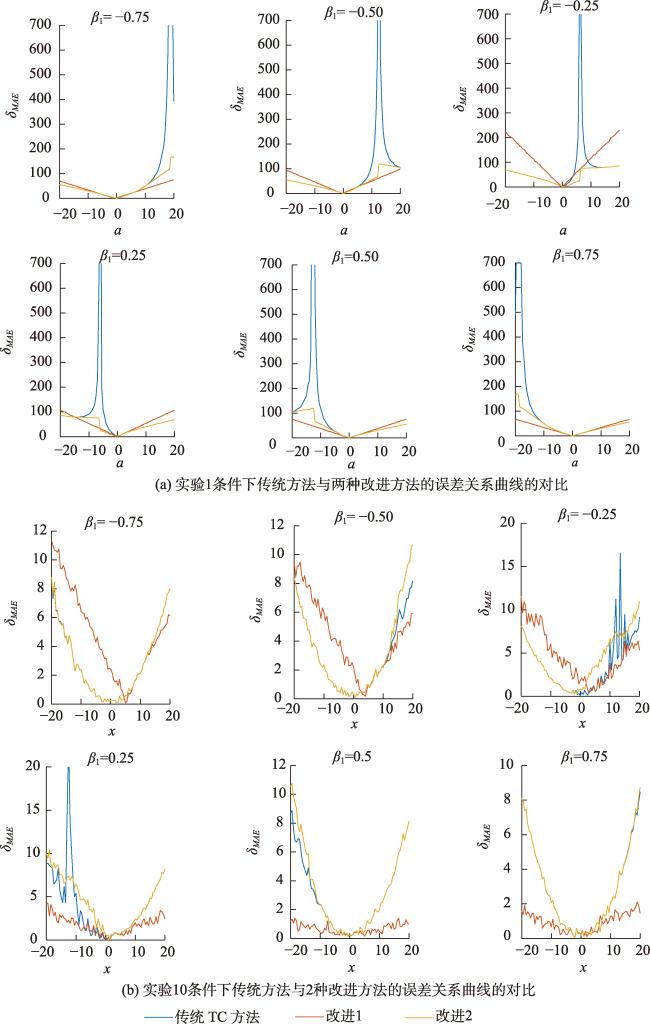
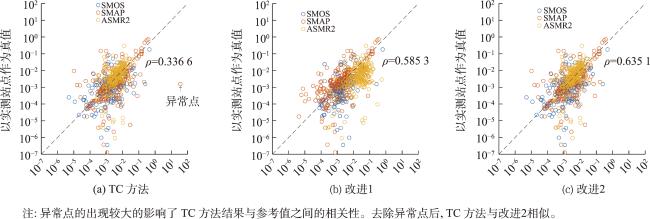
Triple Collocation(TC)方法是一种可以在未知真值情况下评估3个独立观测样本各自不确定性的方法,该方法使用的前提是误差形式假设与2组不相关性假设,但在实际使用中,这3条假设难以完全满足。其中2组不相关性假设经常面临较大的违背,并且无法得知这种假设违背对结果误差的影响。本文通过虚拟样本实验生成了多组不同程度违背不相关性假设的样本,以定量评估不同程度假设违背对结果误差的影响。结果表明,一般情况下,某一条不相关性假设的违背程度增加时,方法的结果误差会相应地呈线性或平方倍数增加;但当不相关性假设的违背处于某个特定关系时,TC方法结果的误差会突然大幅度增加,这种现象在以往的研究中并没有得到重视,后文将该现象简称为异常点。为了探求异常点出现的原因,本文从理论上推导出了违反不相关性假设与结果误差之间的关系,这种关系呈现为分式结构,而异常点的出现正是这种分式结构所致。异常点的存在影响了方法的稳定性。从差值形式的TC方法的角度来看,抑制异常点的关键在于如何更好地设计缩放系数。本文给出了2种抑制异常点的方法: ① 忽略加性偏差系数,使得缩放系数不受两组不相关性假设的影响; ② 限制缩放系数的上下限。根据实际数据分析,第2种改进方法优于第1种。第2种方法不仅保留了TC方法的准确性,而且有效地避免了异常点的出现。值得注意的是,在实际数据中,部分异常点会以负值形式出现并因计算结果不能为负而被剔除。在使用TC方法进行计算时,重复次数较少的情况下,可以不考虑异常点的影响。
谈松林 , 王洁 , 季静静 , 刘美丽 , 湛忠宇 , 刘淼 , 王丽荣 , 胡晓东 . 违背不相关性假设对Triple Collocation方法精度的影响[J]. 地球信息科学学报, 2024 , 26(3) : 591 -603 . DOI: 10.12082/dqxxkx.2024.230502
Triple Collocation (TC) is a technique for assessing the uncertainties of three samples individually without knowledge of the true values. This method is based on the assumptions of linearity, orthogonality, and zero cross-correlation. In practical use, these three assumptions are often difficult to achieve, particularly the orthogonality and zero cross-correlation assumptions, which often encounter significant violations. Moreover, we are uncertain about the impact of these assumption violations on the errors of the method's results. In this study, we simulated multiple sets of synthetic samples with varying degrees of two assumption violations to investigate the impact of assumption violations on the accuracy of the TC method. The results of synthetic samples experiment indicate that, in general, when there is an increase in the violation of orthogonality or zero cross-correlation assumptions, the error of the method's results increases linearly or quadratically. However, under certain specific conditions of assumption violation, there is a sudden and spike-like increase in the error of TC method results. This phenomenon is referred to as "outliers". To understand the origin of the outliers, we derived the complete mathematical relationship between the violation of assumptions and the errors of the results. This relationship exhibits a fractional structure rather than a linear one, contributing to the emergence of outliers. From the perspective of the difference notation, this fractional structure results from rescaling coefficients. Continuing to analyze this mathematical relationship, we can draw two conclusions. Firstly, merely ensuring the approximate independence of the three samples does not necessarily lead to improved method results. When the structural relationships among the three samples meet certain conditions, outliers emerge. Additionally, previous attempts at method improvement have aimed at overall reducing the sensitivity of this method to assumptions, neglecting the presence of outliers. Considering these factors, the key to suppressing outliers lies in better designing these rescaling coefficients. The paper presents two possible improvement methods:(1) Ignoring the additive bias, so that the rescaling coefficients are not affected by the orthogonality or zero cross-correlation assumptions. (2) Limiting the upper and lower bounds of the rescaling coefficients. We achieved favorable results in suppressing outliers by constraining the absolute values of the rescaling coefficients between 0.25 and 4. Both improvement methods can suppress the occurrence of outliers. However, when the additive bias is significant, the first improvement method generates substantial extreme errors due to its inherent structure, which is insufficient to eliminate outliers. The second method performs effectively even in complex scenarios. Lastly, we conducted a simple estimation of the probability of outliers occurring in practical usage, which was approximately 3.2%. In addition, we used SMOS, SMAP, and AMSR2 soil moisture data to validate the phenomenon of outliers and compared the two improved methods. According to real data, some outliers appear as negative values and are removed because the calculated results cannot be negative. Therefore, A portion of the outlier does not cause a significant deviation in the calculation result; instead, they simply prevent the calculation of meaningful results. Therefore, when employing the TC method with fewer repetitions for calculations (e.g., with fewer than 500 repetitions), the influence of outliers can be disregarded.
表1 两组不相关性假设违背程度及下文简称Tab. 1 Quantification of deviation from orthogonality and zero cross-correlation assumption, and subsequent abbreviation |
| 所属假设 | 量化违背程度的指标 | 下文简称 |
|---|---|---|
| 随机误差与真值不相关性假设 | ||
| 随机误差互不相关性假设 | ||
表2 虚拟样本实验方案Tab. 2 Synthetic samples experimental design |
| 实验组 | 实验名称 | 实验变量 | 值 | 值 | 其他参数 | ||
|---|---|---|---|---|---|---|---|
| A组 | 实验1 | 变化 | 每组实验中, 中的非实验变量设置为0.001,即假设满足不相关性假设。 为保证所设计的统计参数具有代表性,样本数量设计为200 000个 | ||||
| 实验2 | 变化 | ||||||
| 实验3 | 变化 | ||||||
| B组 | 实验4 | 变化 | |||||
| 实验5 | 变化 | ||||||
| 实验6 | 变化 | ||||||
| C组 | 实验7 | 变化 | |||||
| 实验8 | 变化 | ||||||
| 实验9 | 变化 | ||||||
| X组 | 实验10 | 变化 | |||||
| 实验11 | 变化 | ||||||
| 实验12 | 变化 | ||||||
| Y组 | 实验13 | 变化 | |||||
| 实验14 | 变化 | ||||||
| 实验15 | 变化 | ||||||
| Z组 | 实验16 | 变化 | |||||
| 实验17 | 变化 | ||||||
| 实验18 | 变化 | ||||||
注:经大量实验验证,改变 值不会改变实验结果,故 值变化的情况在此不做讨论。 |
表3 影响异常点出现的各项参数的假定分布Tab. 3 Assumed distributions of various parameters affecting the occurrence of outliers |
| 参数 | 假定的分布或值 | ||
|---|---|---|---|
| 情景1 | 情景2 | 情景3 | |
| 30 | |||
| 50 | |||
| 10 | |||
表4 各情景下误差概率分布Tab. 4 Probability distribution of errors for different scenarios (%) |
| 概率 | 情景1 | 情景2 | 情景3 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| TC | 改进1 | 改进2 | TC | 改进1 | 改进2 | TC | 改进1 | 改进2 | |||
| 29.56 | 28.70 | 29.13 | 29.20 | 30.30 | 29.00 | 29.24 | 36.49 | 28.78 | |||
| 6.76 | 5.00 | 5.53 | 6.50 | 7.60 | 5.40 | 6.88 | 10.38 | 5.41 | |||
| 3.27 | 1.35 | 1.77 | 3.20 | 3.90 | 1.80 | 3.06 | 5.21 | 1.65 | |||
| 1.25 | 0.18 | 0.12 | 1.70 | 1.70 | 0.50 | 1.19 | 2.21 | 0.20 | |||
| 0.76 | 0.05 | 0.01 | 1.20 | 0.70 | 0.10 | 0.70 | 1.43 | 0.01 | |||
| 0.56 | 0.03 | 0.01 | 1.00 | 0.70 | 0.00 | 0.49 | 1.22 | 0.00 | |||
感谢南京信息工程大学高性能计算中心为本研究提供的计算资源。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
梁顺林, 李新, 谢先红, 等. 陆面观测、模拟与数据同化[M]. 北京: 高等教育出版社, 2013.
[
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
范悦, 邱建秀, 董建志, 等. 基于Triple Collocation方法的微波土壤水分产品不确定性分析与时空变化规律研究[J]. 遥感技术与应用, 2020, 35(1):85-96.
[
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}