
基于轨迹活动语义挖掘的个体社会经济水平评估
|
桂志鹏(1982— ),男,宁夏吴忠人,博士,教授,主要从事高性能时空数据挖掘与社会地理计算相关研究。E-mail: zhipeng.gui@whu.edu.cn |
收稿日期: 2024-02-03
修回日期: 2024-03-20
网络出版日期: 2024-05-11
基金资助
国家自然科学基金项目(41971349)
Individual Socio-Economic Level Assessment Based on Trajectory Activity Semantics
Received date: 2024-02-03
Revised date: 2024-03-20
Online published: 2024-05-11
Supported by
National Natural Science Foundation of China(41971349)
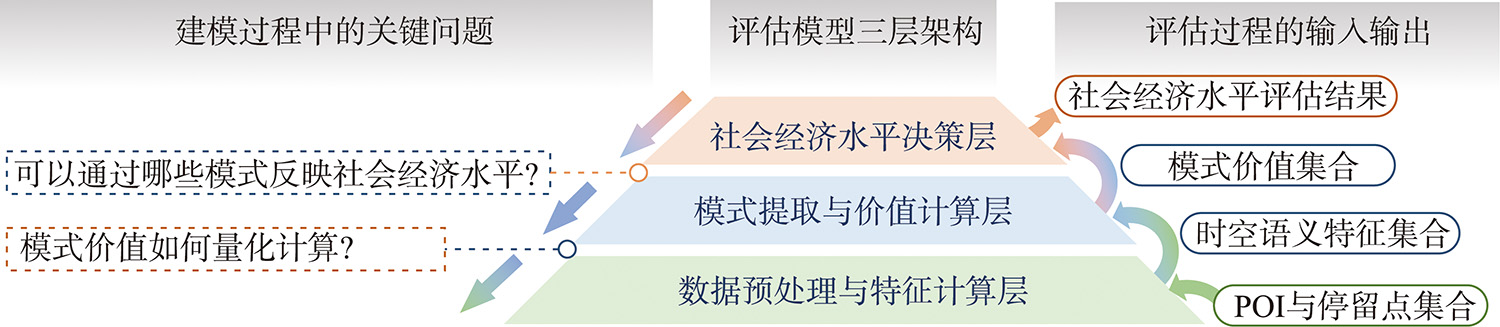
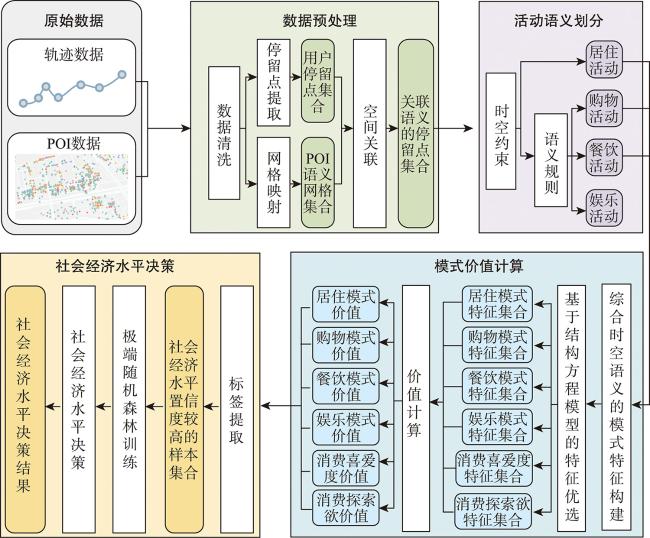
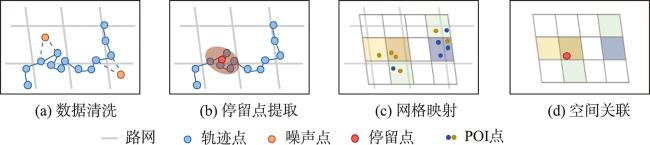
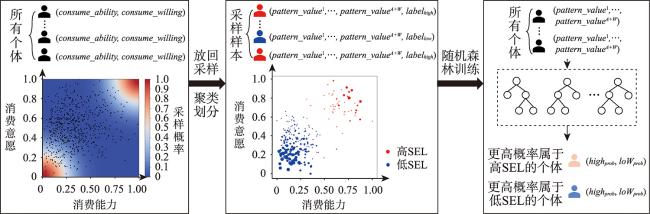
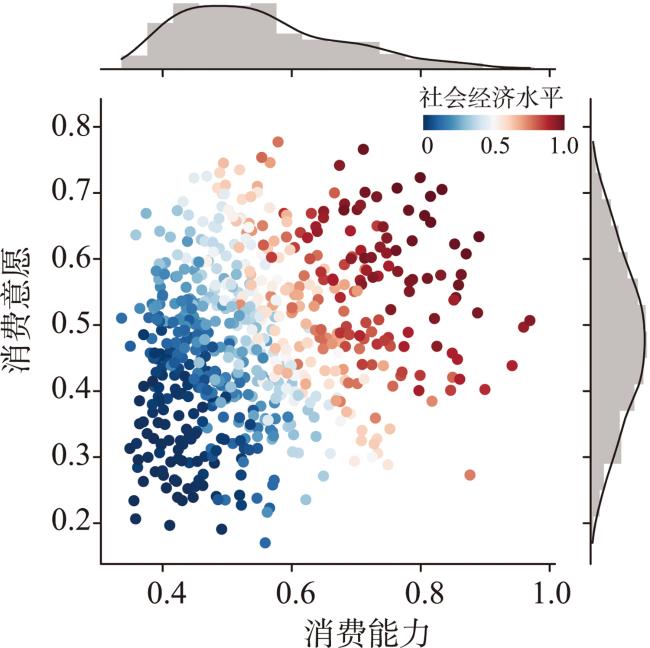
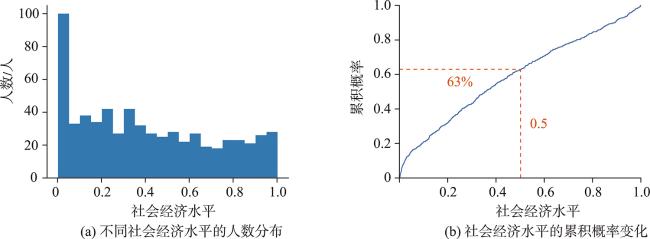
个体社会经济水平评估对于商业决策、城市规划和公共卫生具有重要的应用价值。但现有方法多依赖定位数据和呼叫详单记录构建出行位置和手机业务特征集合,未充分考虑个体出行的语义上下文,难以从动机与需求层面理解出行行为,导致建模过程可解释性不足。为此,本文提出一种基于轨迹活动语义挖掘的个体社会经济水平评估方法,通过显式提取居住、购物、餐饮、娱乐、消费喜爱度与探索欲6类消费模式,从消费能力与意愿角度刻画个体社会经济水平,提高评估方法的可解释性。① 通过网格化的语义地图为停留点赋予出行语义上下文,并划分居住、购物、餐饮、娱乐4类活动的停留点集合; ② 计算4类活动的时间熵、旋转半径和活动区域经济水平等时空语义特征,并通过结构方程模型筛选特征计算各类消费模式价值; ③ 使用极端随机森林决策个体社会经济水平。本文基于深圳市635名个体2019年4—11月的私家车轨迹数据开展实验,通过核心商圈、劳动密集型工厂、高档住宅与城中村等典型场景筛选高低社会经济水平人群,验证了方法有效性;此外,对高低社会经济水平群体的出行时空分布和工作强度开展可视化分析,探讨了群体间的出行模式差异。本文方法可为人地交互视角下的人口统计属性建模提供参考。
桂志鹏 , 丁劲宸 , 刘宇航 , 陈欢 , 吴华意 . 基于轨迹活动语义挖掘的个体社会经济水平评估[J]. 地球信息科学学报, 2024 , 26(4) : 1075 -1092 . DOI: 10.12082/dqxxkx.2024.240078
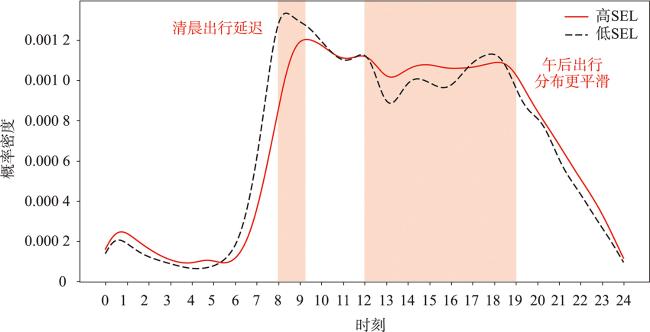
Assessment of individual Socio-Economic Levels (SEL) is crucial for business decisions, urban planning, and public health. However, current methods highly rely on location data and call detail records to construct travel locations and mobile business features, which is inadequate to represent the semantic context of individual travel, and fail to understand the motivations and demands of travel activities. Consequently, it makes the modeling process lack interpretability. To address aforementioned issue, this paper proposes a novel assessment method of individual socio-economic levels based on the analysis of trajectory activity semantics. It models individual socio-economic levels from the perspectives of consumption ability and willingness by explicitly extracting six consumption patterns including residence, shopping, dining, entertainment, consumption preferences and exploration, thereby enhancing the interpretability of the assessment method. Specifically, ① Stay points extracted from trajectories are categorized into four types of activities, including residence, shopping, dining, and entertainment, by tagging semantic context through a grid-based semantic map; ② Spatiotemporal and semantic features such as temporal entropy, gyration radius, and economic level of activity areas, are calculated for the four activities respectively. We then employ the structural equation model to select appropriate features for measuring the values of consumption patterns; ③ Extreme random forest is utilized to assess individual socio-economic levels using the values of six consumption patterns, which is calculated based on the economic levels of regions where an individual stays in the travel activities, as well as the preferences for visiting these regions. We use GPS trajectories of 635 anonymous private car drivers in Shenzhen city of China from April to November in 2019 as experimental data, and assess individual socio-economic levels for each driver. The effectiveness of the proposed method is validated by selecting representative individuals with high and low socio-economic levels from five typical scenarios i.e., central business districts, labor-intensive factories, premium residences, and urban villages, which demonstrates alignment between the calculated socio-economic levels of individuals and the depicted value of the scenarios. Besides, we analyze the spatiotemporal distribution and work intensity of different socio-economic level groups, and explore their differences in travel patterns. The findings indicate that individuals with a higher socio-economic level tend to have more flexible morning commutes, and exhibit a smoother travel distribution in the afternoon. It also presents a more concentrated spatial distribution in terms of their activity areas, which is consistent with the urban structures of Shenzhen. In summary, the proposed method can provide a reference for modeling demographic characteristics of individuals from the perspective of human-environment interaction.
表2 出行活动的识别条件Tab. 2 Conditions for travel activity recognition |
| 活动类型 | 空间约束 | 时间约束 | 语义规则 |
|---|---|---|---|
| 居住活动 | 研究区域内 | 睡眠时间段 | - |
| 餐饮活动 | 研究区域内 | 餐饮时间段 | 餐饮类POI语义重要性大于阈值 |
| 购物活动 | 研究区域内 | - | 购物类POI语义重要性大于阈值 |
| 娱乐活动 | 研究区域内 | - | 娱乐类POI语义重要性大于阈值 |
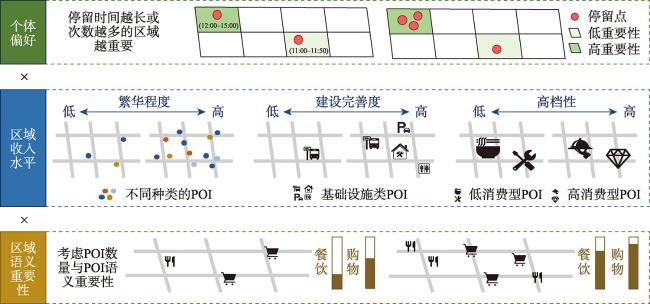
表3 消费模式与特征的对应关系Tab. 3 Associations between consumption patterns and features |
| 消费模式 | 空间特征 | 时间特征 | 语义特征 |
|---|---|---|---|
| 居住模式 | - | 时间占比、次数占比 | 繁华程度、建设完善度、高档性 |
| 餐饮模式 | - | 时间占比、次数占比 | 繁华程度、建设完善度、高档性 |
| 购物模式 | - | 时间占比、次数占比 | 繁华程度、建设完善度、高档性 |
| 娱乐模式 | - | 时间占比、次数占比 | 繁华程度、建设完善度、高档性 |
| 消费喜爱度 | - | 时间占比、次数占比 | - |
| 消费探索欲 | 随机熵、旋转半径 | 时间占比熵、次数占比熵 | - |
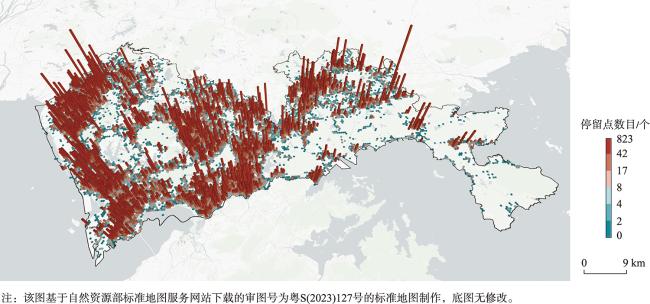
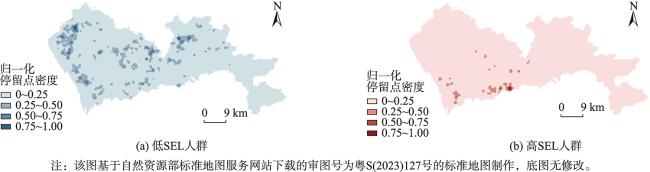
图6 635名个体的停留点空间分布情况Fig. 6 The spatial distribution of stay points for the selected 635 individuals |
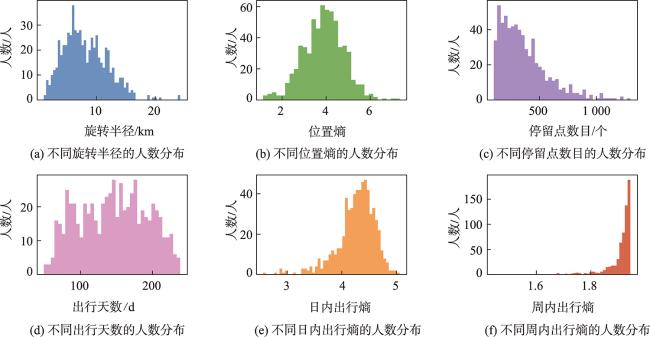
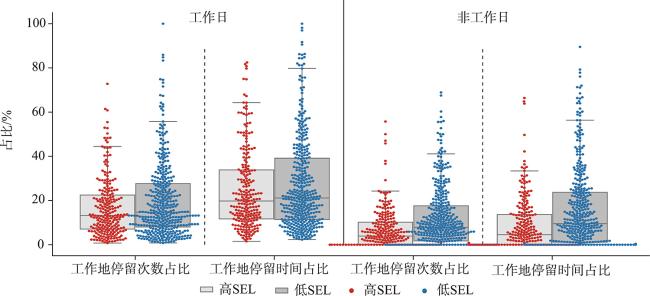
图7 635名个体出行活动的时空特征统计Fig. 7 The distribution of spatiotemporal features of travel activities for 635 individuals |
表4 选择的POI类别及数目Tab. 4 Selected POI types and numbers |
| 类别 | 数目/个 |
|---|---|
| 购物服务 | 143 211 |
| 餐饮服务 | 77 429 |
| 交通设施服务 | 71 723 |
| 生活服务 | 71 313 |
| 公司企业 | 64 627 |
| 商务住宅 | 44 447 |
| 科教文化服务 | 42 413 |
| 政府机构及社会团体 | 30 747 |
| 休闲娱乐服务 | 28 530 |
| 金融保险服务 | 26 013 |
| 住宿服务 | 25 673 |
| 医疗保健服务 | 23 341 |
| 机动车服务 | 23 104 |
| 公共设施 | 11 531 |
| 总计 | 684 102 |
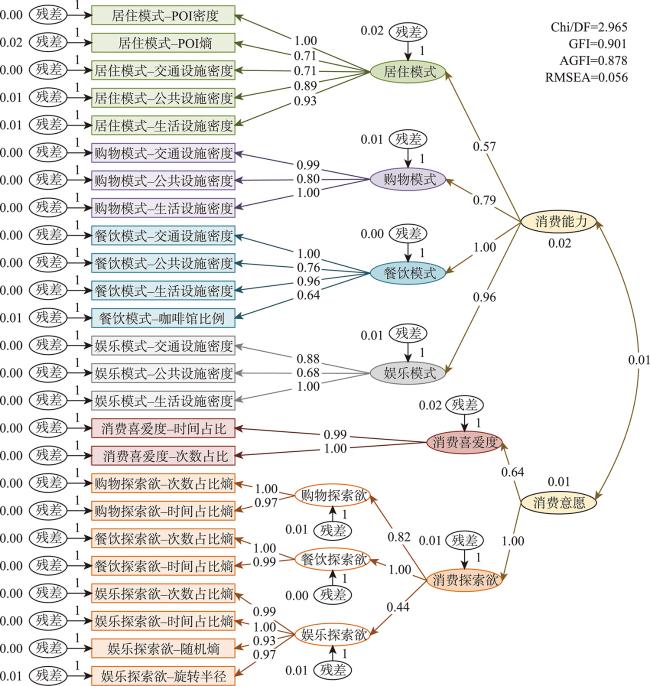
图8 结构方程建模的模型结构与影响关系强度Fig. 8 Model structure of structural equation modeling and impact intensity of relationships |
表6 同质性信度检验结果Tab. 6 Homogeneity reliability test results |
| 消费模式 | Cronbach's α | 95% 置信区间 | |
|---|---|---|---|
| 下界 | 上界 | ||
| 居住模式 | 0.899 | 0.887 | 0.912 |
| 购物模式 | 0.939 | 0.931 | 0.947 |
| 餐饮模式 | 0.909 | 0.898 | 0.921 |
| 娱乐模式 | 0.909 | 0.896 | 0.921 |
| 消费喜爱度 | 0.935 | 0.925 | 0.945 |
| 购物探索欲 | 0.966 | 0.961 | 0.971 |
| 餐饮探索欲 | 0.969 | 0.964 | 0.974 |
| 娱乐探索欲 | 0.958 | 0.953 | 0.964 |
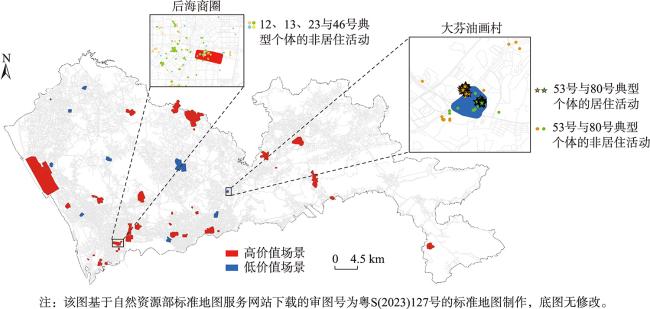
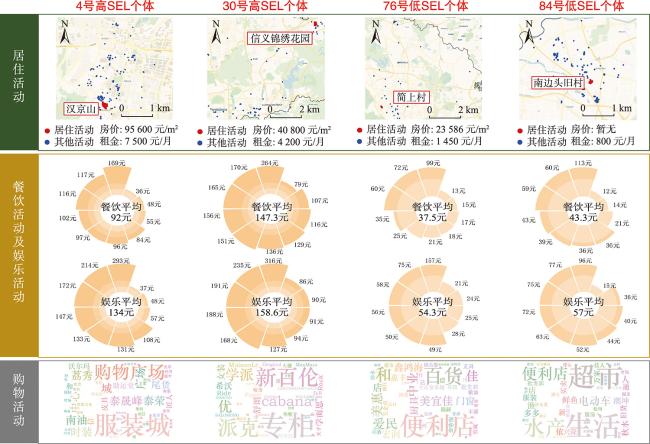
图12 典型场景与部分典型个体停留点的空间分布Fig. 12 The distribution of typical scenarios and stay points of selected six typical individuals |
表7 选取的5类典型场景及对应个体的社会经济水平评估结果Tab. 7 Individual assessment results corresponding to the 5 kinds of selected typical scenarios |
| 场景价值 | 场景类别 | 个体数目/个 | 评估结果均值 | 评估结果方差 |
|---|---|---|---|---|
| 高价值 | 高档住宅(鲸山别墅、红树湾豪宅等) | 15 | 0.857 | 0.095 9 |
| 核心商圈(金光华、蔡屋围商圈等) | 23 | 0.819 | 0.182 7 | |
| 高收入职业(金融大厦、律师事务所等) | 12 | 0.902 | 0.077 2 | |
| 低价值 | 劳动密集型工厂(盛丰、下十围工业区等) | 15 | 0.087 | 0.097 0 |
| 城中村(郎下村、上沙村、笋岗村等) | 30 | 0.119 | 0.109 4 |
| [1] |
|
| [2] |
吴梦, 洪途. 居民消费水平与通货膨胀[J]. 产业与科技论坛, 2020, 19(12): 77-78.
[
|
| [3] |
刘一明, 胡卓玮, 赵文吉, 等. 基于BP神经网络的区域贫困空间特征研究——以武陵山连片特困区为例[J]. 地球信息科学学报, 2015, 17(1):69-77.
[
|
| [4] |
|
| [5] |
桂志鹏, 梅宇翱, 吴华意, 等. 顾及POI人口吸引力异质性的城市人口空间化方法[J]. 地球信息科学学报, 2022, 24(10):1883-1897.
[
|
| [6] |
|
| [7] |
何柳, 施小明, 胡永华. 地区社会经济水平与心血管疾病研究进展[J]. 中国公共卫生, 2014, 30(7):936-939.
[
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
么晓明, 丁世昌, 赵涛, 等. 大数据驱动的社会经济地位分析研究综述[J]. 计算机科学, 2022, 49(4):80-87.
[
|
| [14] |
|
| [15] |
关庆锋, 任书良, 姚尧, 等. 耦合手机信令数据和房价数据的城市不同经济水平人群行为活动模式研究[J]. 地球信息科学学报, 2020, 22(1):100-112.
[
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
初晨, 张恒才, 陆锋. 大型商场顾客消费行为轨迹推断[J]. 地球信息科学学报, 2022, 24(6):1034-1046.
[
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
曹劲舟, 涂伟, 李清泉, 等. 基于大规模手机定位数据的群体活动时空特征分析[J]. 地球信息科学学报, 2017, 19(4):467-474.
[
|
| [36] |
|
| [37] |
齐凌艳, 陈荣国, 温馨. 基于语义轨迹停留点的位置服务匹配与应用研究[J]. 地球信息科学学报, 2014, 16(5):720-726.
[
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
姚可桢, 岳书平. 网络大数据下的中国现代食甜习惯空间分布特征及其影响因素研究[J]. 地球信息科学学报, 2020, 22(6):1202-1215.
[
|
| [44] |
|
| [45] |
|
/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}