
地球表层系统开放科学数据目录关联网络构建研究进展
|
邱芹军(1988— ),男,湖北武汉人,博士,副研究员,研究方向为地学大数据挖掘与知识图谱构建。E-mail: qiuqinjun@cug.edu.cn |
收稿日期: 2023-09-13
修回日期: 2024-03-08
网络出版日期: 2024-05-11
基金资助
国家重点研发计划项目(2022YFF0711601)
国家重点研发计划项目(2022YFB3904200)
国家自然科学基金项目(42301492)
湖北省自然科学基金项目(2022CFB640)
地质探测与评估教育部重点实验室主任基金项目(GLAB2023ZR01)
Research Progress of Construction of an Association Network of Open Scientific Data Catalogues for the Earth Surface System
Received date: 2023-09-13
Revised date: 2024-03-08
Online published: 2024-05-11
Supported by
National Key Research and Development Program of China(2022YFF0711601)
National Key Research and Development Program of China(2022YFB3904200)
National Natural Science Foundation of China(42301492)
Natural Science Foundation of Hubei Province(2022CFB640)
Opening Fund of Key Laboratory of Geological Survey and Evaluation of Ministry of Education(GLAB2023ZR01)
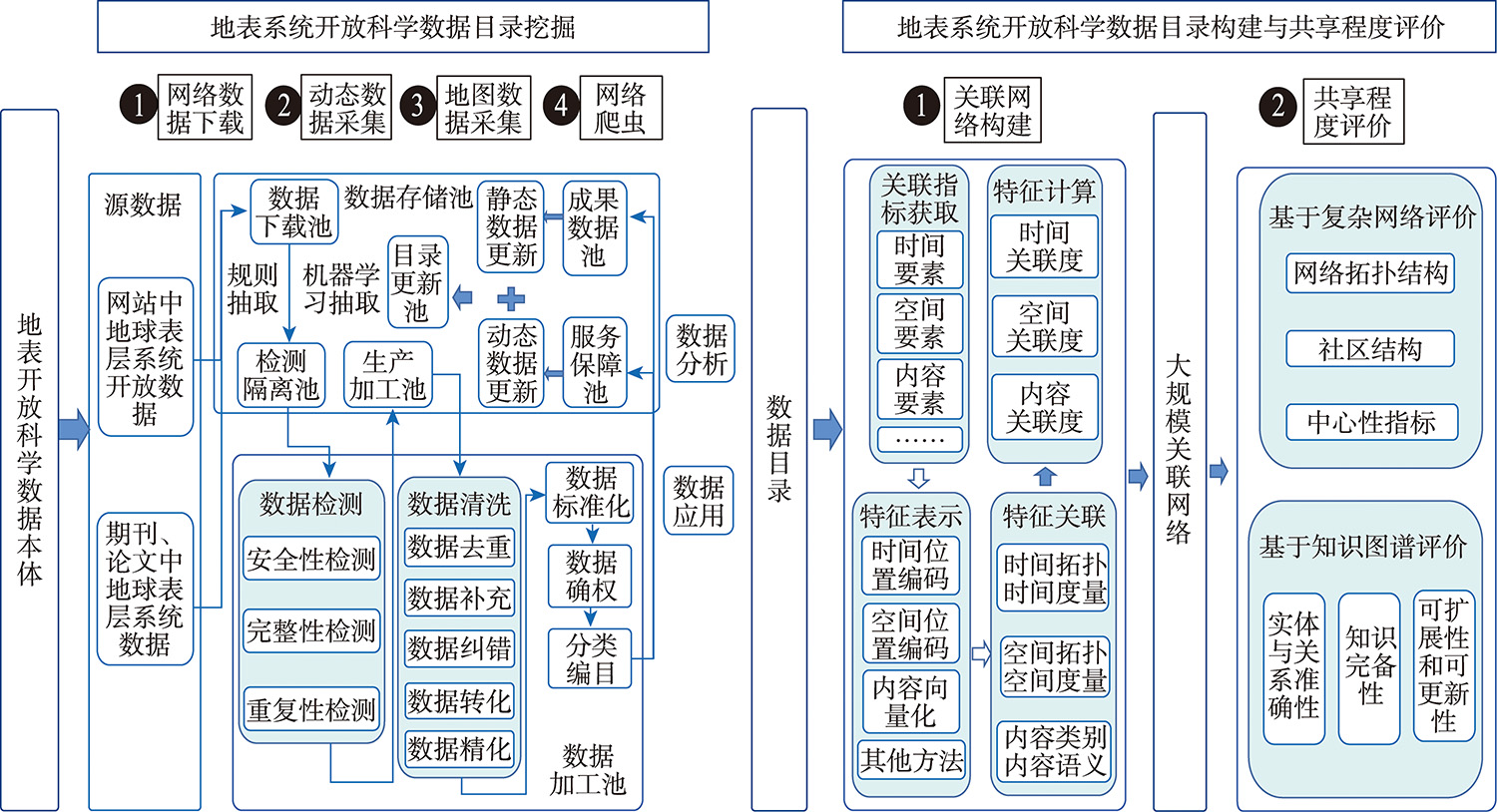
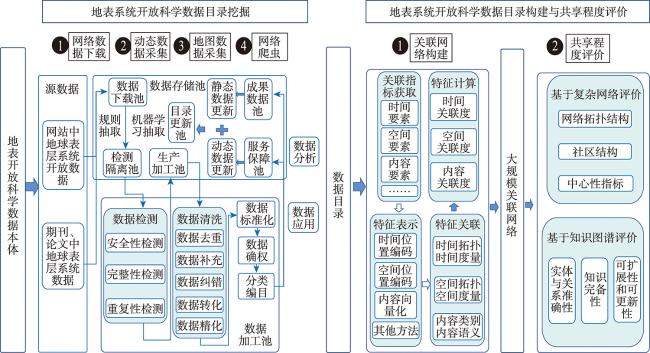
快速发现、挖掘并利用海量地球表层系统(以下简称“地表系统”)开放科学数据,是大数据时代下地表系统开放科学数据共享新的发展趋势和前沿研究方向。地表系统开放科学数据具有组织分散、多源异构、多模态、多类型等特性,通常以专题共享网站、数据服务、元数据、期刊论文(特别是数据论文)等形式存在,研究发展适应不同模态的地表系统开放数据挖掘方法、分析其共享质量是充分利用这些数据的关键科学问题。关联网络为地表系统开放科学数据的语义互联和知识发现提供了有力的支撑,其以元数据URI(Uniform Resource Identifier)为节点,元数据间的语义关系为边,节点间关联性的强弱作为边的值。本文从地表系统开放科学数据关联网络构建角度出发,对其发展现状、基本特征和构建技术进行了调研与分析。首先选取国内外典型关联网络和相关文献作为研究对象,根据所选取的9个主流关联网络和200余篇相关文献,从关联网络的基本特征和构建技术2个方面进行比较分析。在基本特征方面,分析了关联网络的数据来源、自动化程度和更新方式;在构建技术方面,介绍了关联指标的选择,讨论了地表系统开放科学数据特征的提取、表示和计算方法。最后提出了未来地表系统关联网络构建的建议,包括构建高质量、全覆盖的地表系统开放科学数据本体、考虑顾及“时间-空间-内容”地学知识复杂关系及推理、建立面向多语言的地表系统开放科学数据关联网络方法以及提升地表系统开放科学数据关联网络应用成效等。
邱芹军 , 郝孟璂 , 谢忠 , 陶留锋 , 李伟杰 , 王洋 , 刘建东 . 地球表层系统开放科学数据目录关联网络构建研究进展[J]. 地球信息科学学报, 2024 , 26(4) : 866 -880 . DOI: 10.12082/dqxxkx.2024.230557
With the new generation of information technologies, such as earth observation, IoT monitoring, the Internet, 5G, and the deepening of the concept of open data sharing, there has been an explosive growth of openly shared earth surface system data on the web, and open big data on the earth surface system has taken shape. Rapid discovery, mining, and utilization of massive open scientific data of the earth surface system (hereinafter referred to as "surface system" ) is a new development trend and frontier research direction of scientific data sharing of surface system in the era of big data. The open scientific data of surface system has the characteristics of decentralized organization, multi-source heterogeneity, multi-modality, and multi-type, and usually exists in the form of thematic sharing websites, data services, metadata, journal papers (especially data papers), etc. The research on the development of open data mining methods for surface system adapted to different modalities and the analysis of its sharing quality are key scientific issues to make full use of these data. The association network provides a powerful support for semantic interconnection and knowledge discovery of open scientific data of surface system, which takes metadata Uniform Resource Identifier (URI) as nodes, semantic relationship between metadata as edges, and the strength of association between nodes as the value of edges. This paper investigates and analyzes the current development status, basic features, and construction technology from the perspective of construction of open scientific data association network of surface system. We select typical association networks and related literatures at home and abroad as the research objects. Based on the selected nine mainstream association networks and more than 200 related literatures, we make a comparative analysis from the aspects of basic features of the association networks and the construction technology. In terms of basic features, the data source, automation degree, and updating method of the association networks are analyzed; in terms of construction technology, the selection of association indexes is introduced, and the methods of extracting, representing, and calculating the features of open scientific data of the surface system are discussed. Finally, recommendations for future construction of the surface system association network are put forward, including construction of a high-quality and full-coverage surface system open scientific data ontology, consideration of "time-space-content" geoscientific knowledge complex relationship and reasoning, establishment of a multi-language surface system open data association network method, and enhancement of the effectiveness of the surface system open scientific data association network application.
表1 筛选的关联网络基本情况Tab. 1 General situation of the selected association network |
| 关联网络 | 发布网址 | 定位目标 | 创建年份 | 创建者 | 数据规模 | 是否开源 |
|---|---|---|---|---|---|---|
| LinkedGeoData | http://linkedgeodata.org/ | 以OSM为数据源,创建大型知识库 | 2009 | 莱比锡大学 | 超过30亿个节点和3亿条边,约200亿个三元组 | 是 |
| Geonames | http://www.geonames.org/ | 覆盖全球的地名词典数据库 | 2002 | Marc Wick | 包含超过1 100万个地名,每个地名都包括坐标 | 是 |
| Geo-Net-PT | https://hdl.handle.net/21.11129/0000-000B-D306-0 | 提供关于葡萄牙命名地点的权威地理知识数据 | 2011 | 葡萄牙地理 学会 | 定义了701 209个实例,其中大多数命名为地名 | 是 |
| DBpedia | https://www.dbpedia.org/ | 以Wikipedia为信息源,从中提取结构化的数据并构建关联网络 | 2007 | 莱比锡大学、 曼海姆大学。 | 包含了超过6亿个节点,数十亿个RDF三元组,涵盖了全球各个领域的知识 | 是 |
| VIVO | https://vivo.lyrasis.org/ | 建立一个开放的、可重用的学术研究信息管理系统 | 2003 | 康奈尔大学 | 数百万个实体和事实 | 是 |
| SIMILE | http://simile.mit.edu/ | 为数字资源管理和展示提供开源的、工具和技术支持,促进元数据和信息的语义互操作性 | 2003 | 麻省理工学院计算机科学和人工智能实验室 | 几百到数千条元素不等 | 是 |
| OpenStreetMap | https://www.openstreetmap.org | 提供了一个由全球志愿者共同编辑和维护的地图数据库 | 2004 | Steve Coast | 覆盖全球200多个国家和地区,包括道路、地形、水系等各种地理信息,数据量达到了数十亿个要素 | 是 |
| WorldKG | http://www.worldkg.org/ | 提供了全球地理信息及其上下文的全面语义表示 | 2021 | Alishiba Dsouza团队 | 包含来自188个国家/地区的超过 1亿个地理实体和超过8亿个三元组 | 是 |
| Wikidata | https://www.wikidata.org/ wiki/Wikidata:Main_Page | 创建一个可自由协作编辑的结构化知识库,为Wikimedia项目提供支撑 | 2012 | 维基媒体基金会,美国 | 超过12亿个三元组,超过9 500万个实体 | 是 |
表2 关联网络增量更新方式Tab. 2 Association network incremental update method |
| 增量更新方式 | 算法描述 | 优点 | 缺点 |
|---|---|---|---|
| 直接添加法 | 直接将新的RDF三元组添加到原有的关联网络中,作为新的事实 | 简单直接,适用于小规模的关联网络和新增数据量较少的情况 | 可能导致数据冗余和不一致,需要进行后续的数据清理和消除冲突 |
| 基于规则的更新 | 定义一些规则或约束条件,根据新的RDF三元组和已有的关联网络进行更新 | 能够根据事先定义的规则和约束条件进行数据过滤和验证,保证数据的一致性 | 规则的定义和维护可能较为复杂,需要根据具体情况进行调整和更新 |
| 基于图匹配 | 通过比较新的RDF三元组与原有关联网络中的实体和关系,找到匹配的实体和关系,并将新的三元组插入到合适的位置 | 能够利用已有关联网络结构进行匹配,确保插入的三元组与已有数据的一致性 | 图匹配算法的准确性和效率取决于图结构的复杂度和匹配方法的选择 |
| 基于实体链接 | 通过实体链接算法,将新的实体与已有关联网络中的相应实体进行关联,并插入新的关系 | 能够保持实体关系的一致性,将新的实体和关系有机地融入已有的关联网络中 | 实体链接的准确性可能受到数据质量和语义理解的限制 |
表3 地表系统开放科学数据目录关联指标构建Tab. 3 Construction of indicators for linking open scientific data catalogues of the earth surface systems |
| 数据特征 | 一级指标 | 二级指标 |
|---|---|---|
| 数据本质特征 | 空间特征 | 空间度量 |
| 空间拓扑 | ||
| 时间特征 | 时间度量 | |
| 时间拓扑 | ||
| 内容特征 | 内容语义 | |
| 内容类别 | ||
| 数据来源特征 | 数据来源 | 数据源 |
| 采集平台 | ||
| 采集者 | ||
| 所属组织 | ||
| 处理者 | ||
| 数据形态特征 | 外部形态 | 数据类型 |
| 格式 | ||
| 存储方式 | ||
| 语言 | ||
| 内部形态 | 基准 | |
| 数据精度 | ||
| 尺度(粒度) | ||
| 数据主题特征 | 主题所属类别 | 圈层 |
| 数据主题分类 | ||
| 分类编码 | ||
| 学科类别 |
感谢中国科学院地理科学与资源研究所王卷乐研究员、诸云强研究员的指导。
| [1] |
刘昌明, 刘璇, 杨亚锋, 等. 水文地理研究发展若干问题商榷[J]. 地理学报, 2022, 77(1):3-15.
[
|
| [2] |
张猛刚, 雷祥义. 地球表层系统浅论[J]. 西北地质, 2005, 38(2):99-101.
[
|
| [3] |
吴绍洪, 高江波, 戴尔阜, 等. 中国陆地表层自然地域系统动态研究:思路与方案[J]. 地球科学进展, 2017, 32(6):569-576.
[
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
王卷乐, 孙九林. 地球系统科学数据共享标准规范体系研究与应用[J]. 地理科学进展, 2009, 28(6):839-847.
[
|
| [8] |
马胜男, 魏宏, 刘碧松. 地理信息标准研制的国内外进展及思考[J]. 武汉大学学报(信息科学版), 2008, 33(9):886-891.
[
|
| [9] |
|
| [10] |
诸云强, 孙九林, 廖顺宝, 等. 地球系统科学数据共享研究与实践[J]. 地球信息科学学报, 2010, 12(1):1-8.
[
|
| [11] |
邢文明, 郭安琪, 秦顺, 等. 科学数据管理与共享的FAIR原则——背景、内容与实施[J]. 信息资源管理学报, 2021, 11(2):60-68,84.
[
|
| [12] |
|
| [13] |
|
| [14] |
曹玉平, 龚主杰, 陈德容, 等. 关联数据技术及其研究现状[J]. 图书馆理论与实践, 2014(11):42-45.
[
|
| [15] |
|
| [16] |
沈志宏, 张晓林, 黎建辉. OpenCSDB:关联数据在科学数据库中的应用研究[J]. 中国图书馆学报, 2012, 38(5):17-26.
[
|
| [17] |
罗侃, 诸云强, 程文芳, 等. 极地科学数据关联方法及应用研究[J]. 极地研究, 2016, 28(3):361-369.
[
|
| [18] |
赵红伟, 诸云强, 侯志伟, 等. 地理空间元数据关联网络的构建[J]. 地理科学, 2016, 36(8):1180-1189.
[
|
| [19] |
赵红伟, 诸云强, 杨宏伟, 等. 地理空间数据本质特征语义相关度计算模型[J]. 地理研究, 2016, 35(1):58-70.
[
|
| [20] |
朱文武, 王鑫. 三元空间大数据网络关联表征[J]. 中国科学:信息科学, 2021, 51(11):1802-1839.
[
|
| [21] |
于梦月. 基于本体的开放政府数据的元数据方案及其应用研究[D]. 大连: 大连海事大学, 2018.
[
|
| [22] |
|
| [23] |
梁顺林, 陈晓娜, 陈琰, 等. 陆表卫星遥感GLASS产品集的研发新进展[J]. 遥感学报, 2023, 27(4):831-856.
[
|
| [24] |
邱春艳, 陈可睿. 科学元数据标准的现状、特点与改进建议[J]. 数字图书馆论坛, 2022(12):10-18.
[
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
沈志宏, 张晓林. 关联数据及其应用现状综述[J]. 现代图书情报技术, 2010(11):1-9.
[
|
| [33] |
尚渡新, 袁润, 夏翠娟, 等. 关联数据在知识库中应用的研究综述[J]. 数字图书馆论坛, 2022(3):22-31.
[
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
诸云强, 孙凯, 李威蓉, 等. 地球科学知识图谱比较分析与启示:构建方法与内容视角[J]. 高校地质学报, 2023, 29(3):382-394.
[
|
| [38] |
|
| [39] |
|
| [40] |
刘朋飞, 崔铁军. 地理数据关联研究进展[J]. 天津师范大学学报(自然科学版), 2019, 39(3):10-15.
[
|
| [41] |
刘志辉, 魏娟霞, 张均胜. 基于知识图谱的科技创新指标自适应计算方法研究[J]. 情报学报, 2019, 38(8):826-837.
[
|
| [42] |
|
| [43] |
董少春, 尹宏伟, 许刚. 地质时间本体在异构数据检索中的应用[J]. 地球信息科学学报, 2010, 12(2):2194-2199.
[
|
| [44] |
胡少虎, 张颖怡, 章成志. 关键词提取研究综述[J]. 数据分析与知识发现, 2021, 5(3):45-59.
[
|
| [45] |
|
| [46] |
|
| [47] |
刘宏哲, 须德. 基于本体的语义相似度和相关度计算研究综述[J]. 计算机科学, 2012, 39(2):8-13.
[
|
| [48] |
|
| [49] |
|
| [50] |
|
| [51] |
|
| [52] |
张杰. 文献结构化的细粒度检索技术研究[D]. 南京: 东南大学, 2019.
[
|
| [53] |
|
| [54] |
|
| [55] |
|
| [56] |
|
| [57] |
|
| [58] |
|
| [59] |
白海燕, 朱礼军. 关联数据的自动关联构建研究[J]. 现代图书情报技术, 2010(2):44-49.
[
|
| [60] |
|
| [61] |
|
| [62] |
|
| [63] |
|
| [64] |
葛斌, 李芳芳, 郭丝路, 等. 基于知网的词汇语义相似度计算方法研究[J]. 计算机应用研究, 2010, 27(9):3329-3333.
[
|
| [65] |
王小林, 王东, 杨思春, 等. 基于《知网》的词语语义相似度算法[J]. 计算机工程, 2014, 40(12):177-181.
[
|
| [66] |
|
| [67] |
|
| [68] |
陈军, 赵仁亮. GIS空间关系的基本问题与研究进展[J]. 测绘学报, 1999, 28(2):95-102.
[
|
| [69] |
|
| [70] |
|
| [71] |
|
| [72] |
|
| [73] |
|
| [74] |
|
| [75] |
|
| [76] |
高云亮. 地理信息资源关联关系的可视化方法研究与实践[D]. 郑州: 解放军信息工程大学, 2017.
[
|
| [77] |
刘峰, 韩芳, 魏天珂, 等. 科学数据语义关联技术研究与应用[J]. 数据与计算发展前沿, 2023, 5(1):28-40.
[
|
| [78] |
吕天阳, 谢文艳, 郑纬民, 等. 加权复杂网络社团的评价指标及其发现算法分析[J]. 物理学报, 2012, 61(21):145-154.
[
|
| [79] |
于会, 刘尊, 李勇军. 基于多属性决策的复杂网络节点重要性综合评价方法[J]. 物理学报, 2013, 62(2):46-54.
[
|
| [80] |
张琨, 沈海波, 张宏, 等. 基于灰色关联分析的复杂网络节点重要性综合评价方法[J]. 南京理工大学学报, 2012, 36(4):579-586.
[
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}