
多分支双任务的多模态遥感影像道路提取方法
|
林雨准(1993— ),男,浙江衢州人,博士生,讲师,主要从事遥感图像智能解译研究。E-mail: lyz120218@163.com |
收稿日期: 2024-02-10
修回日期: 2024-04-03
网络出版日期: 2024-05-24
基金资助
国家自然科学基金项目(42301464)
Multi-branch and Dual-task Method for Road Extraction from Multimodal Remote Sensing Images
Received date: 2024-02-10
Revised date: 2024-04-03
Online published: 2024-05-24
Supported by
National Natural Science Foundation of China(42301464)
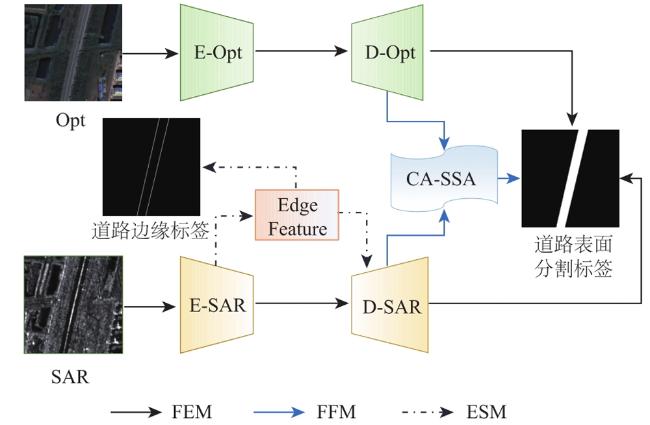
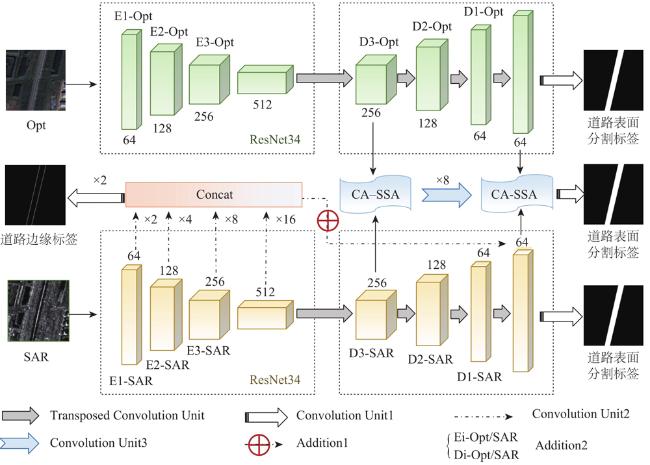
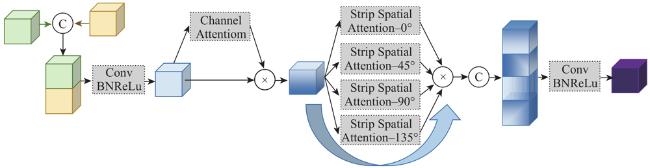
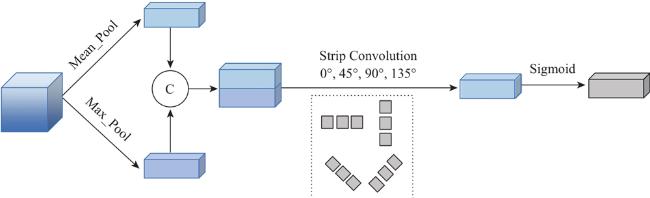
光学影像和SAR影像具有丰富的互补属性,有效的融合策略可为地物解译提供夯实的信息基础。道路作为条状地物,其拓扑结构、分布规律和应用场景往往会对解译效果带来挑战。基于此,本文提出一种多分支双任务的多模态遥感影像道路提取方法。首先,构建结构相同但参数独立的编码—解码网络分别对光学和SAR影像进行特征提取,并利用道路表面分割标签监督训练;其次,引入SAR影像的编码层特征进行道路边缘检测,并将其中间特征输入至SAR影像的解码层特征,从而优化道路与背景的切割效果;最后,利用设计的通道—条状空间注意力(Channel Attention-Strip Spatial Attention, CA-SSA)充分融合光学影像和SAR影像的浅层和深层特征,从而预测最终的道路提取结果。为验证本文方法的有效性,利用Dongying数据集进行实验,在定量精度评价指标中,本文方法的IoU相比单模态对比方法至少提升1.04%,相比多模态对比方法至少提升1.95%;在定性效果分析中,本文方法在道路交叉口以及低等级道路等重难点区域具有明显优势。此外,在光学影像受云雾影响时,本文方法的道路提取效果最佳。

林雨准 , 金飞 , 王淑香 , 左溪冰 , 戴林鑫杰 , 黄子恒 . 多分支双任务的多模态遥感影像道路提取方法[J]. 地球信息科学学报, 2024 , 26(6) : 1547 -1561 . DOI: 10.12082/dqxxkx.2024.240101
Optical images and SAR images have rich complementary attributes, and an effective data fusion strategy can provide a solid information base for objects interpretation. Roads, as strip features, their topology, distribution patterns, and application scenarios often pose challenges to the interpretation results. Based on this, this paper proposes a multi-branch and dual-task method for road extraction from multimodal remote sensing images. First, encoding-decoding networks with the same structure but independent parameters are constructed for feature extraction of optical and SAR images, respectively, and road surface segmentation labels are used for supervised training. Second, the coding layer features of the SAR images are introduced for road edge detection, and their intermediate features are input to the decoding layer features of the SAR image, so as to optimize the discrimination effect between the road and the background. Finally, the designed Channel Attention-Strip Spatial Attention (CA-SSA) is utilized to fully fuse the shallow and deep features of optical and SAR images to predict the final road extraction results. In the experiment, using the Dongying data set as the reference, it is proved that the method of this paper is superior to the comparative methods based on quantitative evaluation metrics, has obvious advantages in challenging areas such as road intersection and low-grade roads, and has best road extraction results when optical images is affected by clouds.
表1 网络基本单元结构组成Tab. 1 Network basic unit structure composition |
| 单元名称 | 单元组成 |
|---|---|
| Transposed Convolution Unit | 1)Conv(1×1, s=1, p=0); 2)BN; 3)Relu; 4)DeConv(3×3); 4)BN; 5)Relu; 6) Conv(1×1, s=2, p=1); 7)BN; 8)Relu |
| Convolution Unit1 | 1)Conv(3×3, s=1, p=1); 2)BN; 3) sigmoid |
| Convolution Unit2 | 1)Conv(1×1, s=1, p=0); 2) Relu |
| Convolution Unit3 | 1)Conv(1×1, s=1, p=0); 2)BN; 3) Relu |
注:s表示stride, p表示padding。 |
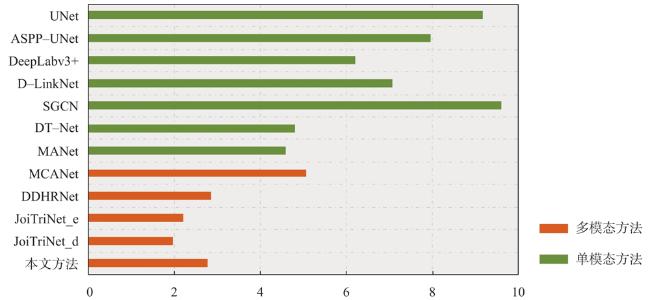
表2 不同方法道路提取结果精度对比Tab. 2 Comparison of the accuracy of road extraction results of different methods (%) |
| 单模态方法-Opt | 评价指标 | ||||||
|---|---|---|---|---|---|---|---|
| P | R | F1 | OA | IoU | Com | Eor | |
| UNet | 92.38 | 81.59 | 86.65 | 98.19 | 76.44 | 77.35 | 5.96 |
| ASPP-UNet | 91.29 | 84.25 | 87.63 | 98.29 | 77.98 | 82.54 | 8.82 |
| DeepLabv3+ | 94.42 | 85.05 | 89.49 | 98.57 | 80.98 | 84.65 | 4.27 |
| D-LinkNet | 94.78 | 86.14 | 90.25 | 98.66 | 82.23 | 85.09 | 4.01 |
| SGCN | 94.08 | 87.18 | 90.50 | 98.69 | 82.64 | 85.30 | 4.44 |
| DT-Net | 96.13 | 89.25 | 92.56 | 98.97 | 86.15 | 86.65 | 3.21 |
| MANet | 97.42 | 90.18 | 93.66 | 99.12 | 88.07 | 87.25 | 2.45 |
| 单模态方法-SAR | 评价指标 | ||||||
| P | R | F1 | OA | IoU | Com | Eor | |
| UNet | 81.62 | 73.84 | 77.54 | 96.93 | 63.31 | 71.63 | 15.19 |
| ASPP-UNet | 90.44 | 72.38 | 80.41 | 97.47 | 67.23 | 70.63 | 6.53 |
| DeepLabv3+ | 91.58 | 78.79 | 84.71 | 97.96 | 73.47 | 77.59 | 6.65 |
| D-LinkNet | 92.71 | 82.94 | 87.55 | 98.31 | 77.86 | 80.31 | 5.54 |
| SGCN | 91.51 | 79.76 | 85.23 | 98.02 | 74.26 | 76.22 | 8.04 |
| DT-Net | 95.30 | 83.52 | 89.02 | 98.52 | 80.21 | 79.86 | 3.02 |
| MANet | 96.39 | 86.81 | 91.35 | 98.82 | 84.08 | 84.12 | 2.96 |
| 多模态方法 | 评价指标 | ||||||
| P | R | F1 | OA | IoU | Com | Eor | |
| MCANet | 96.83 | 89.72 | 93.14 | 99.05 | 87.16 | 88.22 | 6.07 |
| DDHRNet | 96.22 | 86.83 | 91.29 | 98.81 | 83.97 | 82.79 | 2.01 |
| JoiTriNet_e | 96.02 | 90.31 | 93.08 | 99.04 | 87.05 | 88.43 | 3.56 |
| JoiTriNet_d | 96.27 | 89.60 | 92.81 | 99.00 | 86.59 | 87.19 | 2.97 |
| 本文方法 | 97.89 | 90.86 | 94.24 | 99.20 | 89.11 | 88.38 | 2.26 |
注:红色数值为最佳,蓝色数值为次佳,绿色数值为最差。 |
表3 单模态方法融合结果精度统计Tab. 3 Precision statistics of fusion results by single mode method (%) |
| 单模态方法 | 评价指标 | ||||||
|---|---|---|---|---|---|---|---|
| P | R | F1 | OA | IoU | Com | Eor | |
| UNet | 80.79 | 85.93 | 83.28 | 97.52 | 71.35 | 82.07 | 17.05 |
| ASPP-UNet | 86.38 | 86.98 | 86.68 | 98.08 | 76.49 | 84.25 | 12.80 |
| DeepLabv3+ | 89.37 | 88.61 | 88.99 | 98.43 | 80.16 | 87.12 | 9.36 |
| D-LinkNet | 90.58 | 89.73 | 90.15 | 98.59 | 82.07 | 88.32 | 8.03 |
| SGCN | 89.26 | 89.62 | 89.44 | 98.48 | 80.90 | 87.00 | 10.22 |
| DT-Net | 93.59 | 91.01 | 92.29 | 98.91 | 85.68 | 87.36 | 4.67 |
| MANet | 95.17 | 92.30 | 93.72 | 99.12 | 88.17 | 88.63 | 4.36 |
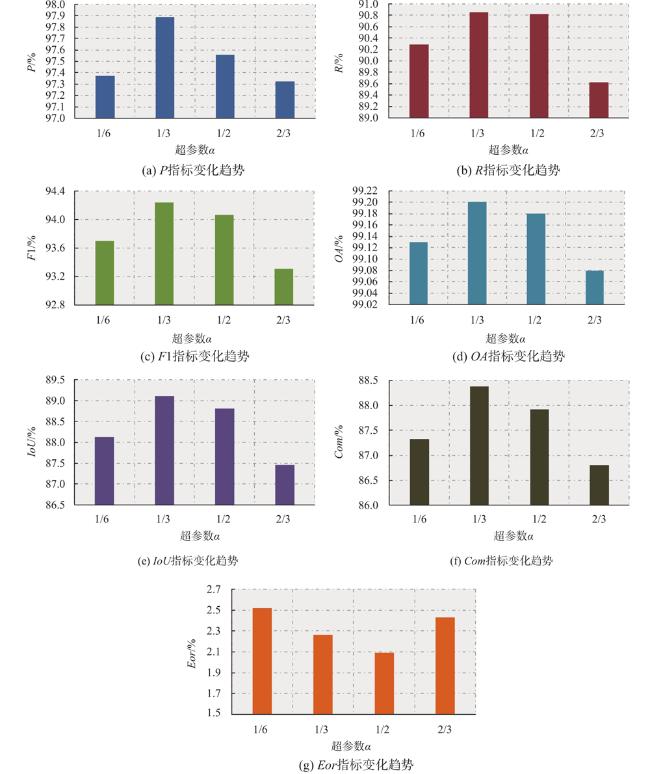
表4 消融实验精度统计Tab. 4 Accuracy statistics of ablation experiments (%) |
| 情形1 | 情形2 | 情形3 | 情形4 | |
|---|---|---|---|---|
| 多分支 | √ | √ | √ | |
| CA-SSA | √ | √ | ||
| 边缘检测任务 | √ | |||
| P | 93.26 | 97.81 | 97.69 | 97.89 |
| R | 86.19 | 89.58 | 90.46 | 90.86 |
| F1 | 89.59 | 93.51 | 93.94 | 94.24 |
| OA | 98.56 | 99.11 | 99.16 | 99.20 |
| IoU | 81.14 | 87.82 | 88.57 | 89.11 |
| Com | 85.26 | 87.24 | 87.70 | 88.38 |
| Eor | 5.45 | 2.41 | 2.39 | 2.26 |
表5 不同条件的分支精度统计Tab. 5 Branch accuracy statistics under different conditions (%) |
| 评价 指标 | 光学影像分 支(无模态 缺失) | SAR影像分 支(无模态 缺失) | 光学影像分支(SAR影像 缺失) | SAR影像 分支(光学 影像缺失) |
|---|---|---|---|---|
| P | 97.42 | 96.51 | 97.42 | 96.51 |
| R | 90.92 | 86.90 | 90.92 | 86.90 |
| F1 | 94.06 | 91.45 | 94.06 | 91.45 |
| OA | 99.18 | 98.83 | 99.18 | 98.83 |
| IoU | 88.78 | 84.25 | 88.78 | 84.25 |
| Com | 88.24 | 84.39 | 88.24 | 84.39 |
| Eor | 2.46 | 3.59 | 2.46 | 3.59 |
表6 云雾条件下道路提取结果精度对比Tab. 6 Comparison of accuracy of road extraction results under cloudy conditions (%) |
| 单模态方法-Opt | 评价指标 | ||||||
|---|---|---|---|---|---|---|---|
| P | R | F1 | OA | IoU | Com | Eor | |
| UNet | 91.99 | 71.44 | 80.43 | 97.50 | 67.26 | 67.81 | 6.06 |
| ASPP-UNet | 95.16 | 72.61 | 82.37 | 97.77 | 70.02 | 69.15 | 2.47 |
| DeepLabv3+ | 93.89 | 78.61 | 85.57 | 98.10 | 74.78 | 75.55 | 2.55 |
| D-LinkNet | 95.36 | 78.01 | 85.82 | 98.15 | 75.16 | 74.60 | 2.12 |
| SGCN | 95.01 | 75.96 | 84.42 | 97.99 | 73.04 | 74.13 | 4.05 |
| DT-Net | 95.75 | 84.42 | 89.73 | 98.61 | 81.37 | 82.59 | 2.56 |
| MANet | 96.28 | 86.26 | 90.99 | 98.77 | 83.48 | 82.61 | 1.79 |
| 多模态方法 | 评价指标 | ||||||
| P | R | F1 | OA | IoU | Com | Eor | |
| MCANet | 96.31 | 84.78 | 90.17 | 98.67 | 82.11 | 82.63 | 8.33 |
| DDHRNet | 97.34 | 82.95 | 89.57 | 98.61 | 81.11 | 79.31 | 1.27 |
| JoiTriNet_e | 95.77 | 88.15 | 91.80 | 98.87 | 84.85 | 86.49 | 3.04 |
| JoiTriNet_d | 96.00 | 87.71 | 91.67 | 98.86 | 84.62 | 85.28 | 2.60 |
| 本文方法 | 97.45 | 88.33 | 92.66 | 99.00 | 86.33 | 88.38 | 2.26 |
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
|
| [51] |
|
| [52] |
|
/
| 〈 |
|
〉 |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}