
融合颜色信息和多尺度几何特征的点云语义分割方法
|
张 华(1979— ),男,安徽合肥人,博士,教授,主要从事遥感数据智能解译及GIS理论与应用研究。E-mail: zhhua_79@163.com |
收稿日期: 2024-01-09
修回日期: 2024-02-18
网络出版日期: 2024-05-24
基金资助
国家自然科学基金项目(U22A20569)
Integrating Color Information and Multi-Scale Geometric Features for Point Cloud Semantic Segmentation
Received date: 2024-01-09
Revised date: 2024-02-18
Online published: 2024-05-24
Supported by
National Natural Science Foundation of China(U22A20569)
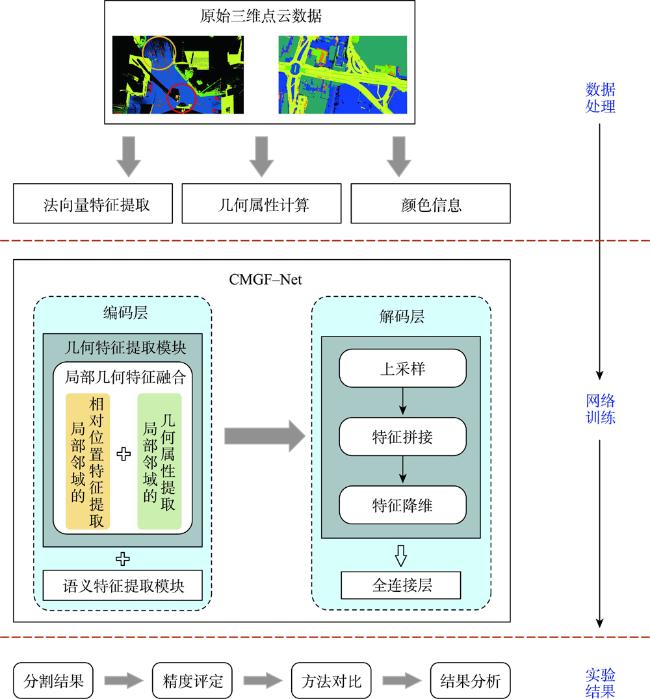
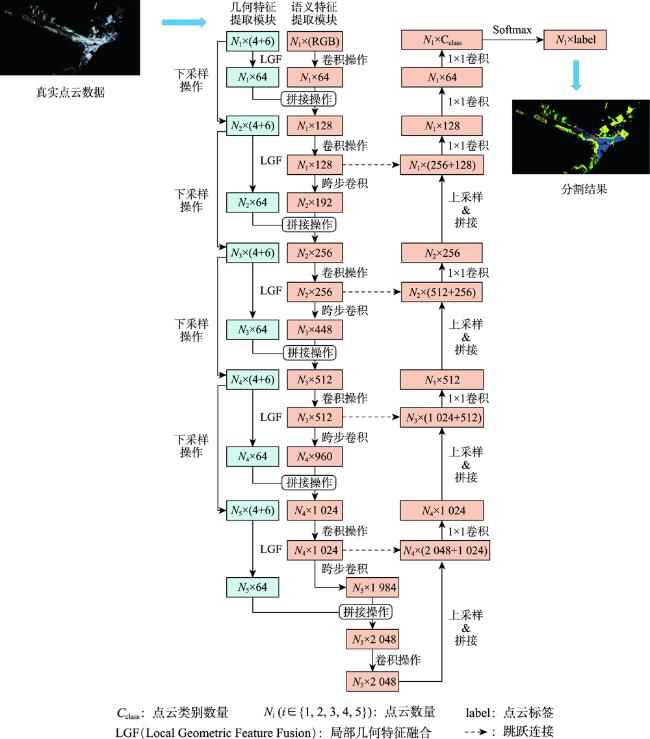
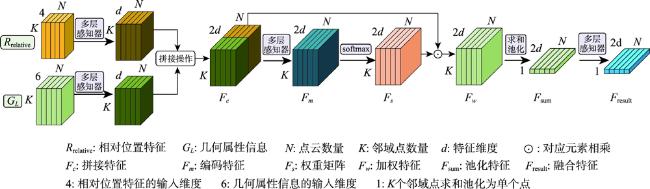
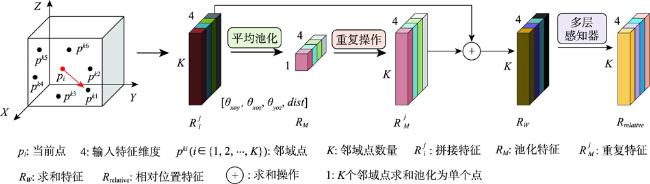
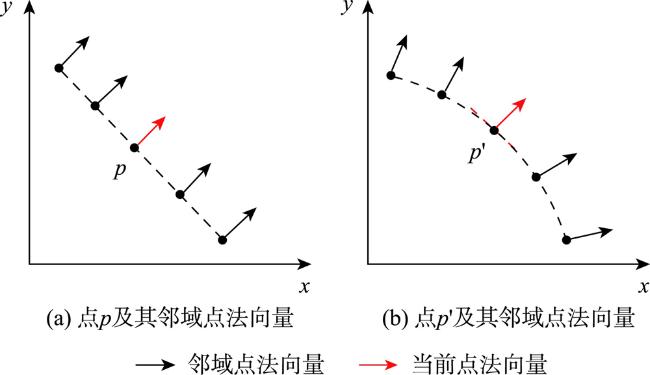
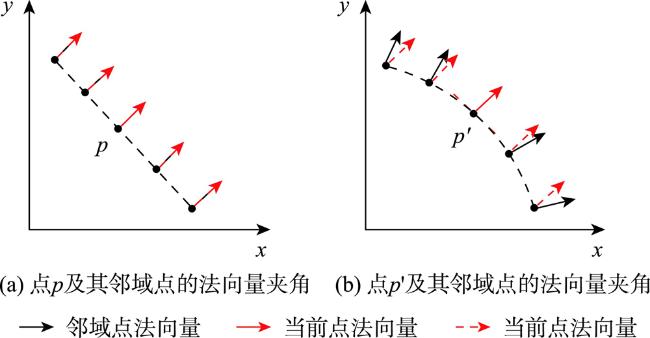
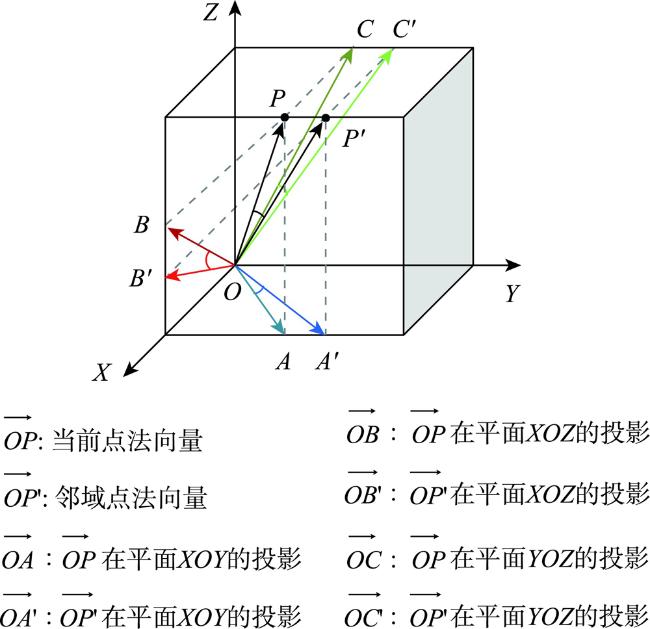
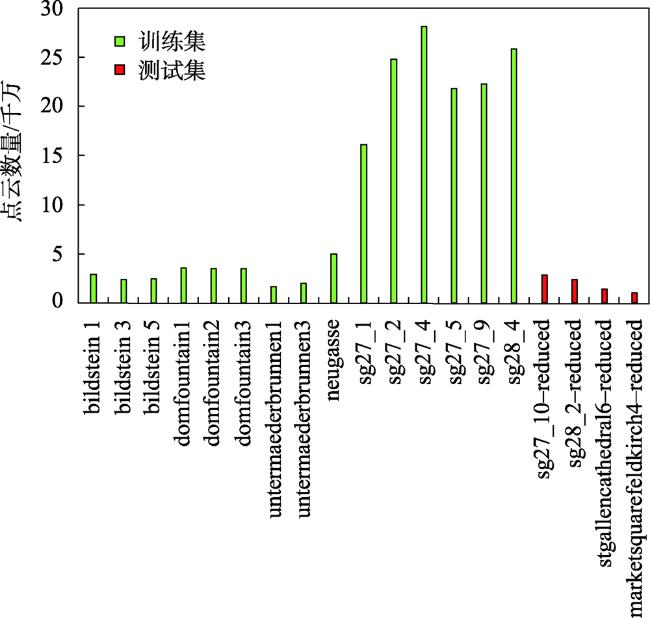
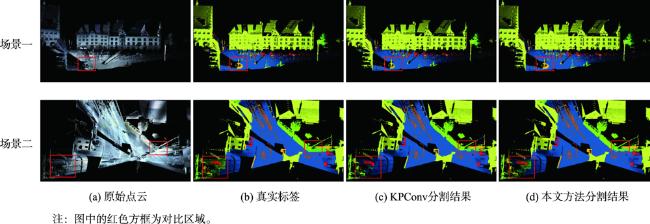
大规模室外点云具有丰富的空间结构,是地理信息获取重要手段之一,由于其本身具有不规则性、复杂几何结构特征及地物尺度变化大等特征,点云分割的准确性依然是一个巨大的挑战。特别是目前大规模点云几何信息及颜色等信息利用不充分等问题,为解决这些问题,本文提出了一种融合颜色信息和多尺度几何特征的点云语义分割方法(Integrating Color Information and Multi-Scale Geometric Features for Point Cloud Semantic Segmentation(CMGF-Net))。该方法中,分别设计了几何特征信息提取和语义特征信息提取模块。在几何特征信息提取模块中,为了充分利用点云数据的几何特征信息,设计了2个特征提取模块,分别是局部邻域的相对位置特征提取模块(RPF)和局部邻域的几何属性提取模块(LGP)。其中,RPF模块利用三维点云的空间法向信息以及相对空间距离,提取邻域点与当前点的相对位置关系; LGP模块利用点云几何属性在不同地物上有独特的表现特性,融合局部区域的几何属性特征;然后通过所设计的几何特征融合模块(LGF)将RPF模块和LGP模块所提取的特征信息进行融合得到融合后的几何特征信息。此外,为了从点云中学习到多尺度的几何特征, CMGF-Net在不同尺度的网络层中都进行了几何特征的提取,最终将所提取的几何特征与基于颜色特征提取的语义特征信息分层进行融合,以提高网络的学习能力。实验结果表明所提出的网络模型在Semantic3D数据集上的平均交并比(mIoU)和平均准确率(OA)达到了78.2%和95.0%,相较于KPConv提高了3.6%和2.1%;在SensatUrban数据集上达到了59.2%和93.7%,由此可见本文所提出的网络模型CMGF-Net在大规模室外场景点云分割具有较好的结果。

张华 , 徐瑞政 , 郑南山 , 郝明 , 刘东烈 , 史文中 . 融合颜色信息和多尺度几何特征的点云语义分割方法[J]. 地球信息科学学报, 2024 , 26(6) : 1562 -1575 . DOI: 10.12082/dqxxkx.2024.240014
Large outdoor point clouds have rich spatial structures and are one of the important means of obtaining geographic information. They have broad application prospects in fields such as autonomous driving, robot navigation, and 3D reconstruction. Due to its inherent irregularity, complex geometric structural features, and significant changes in land scale, the accuracy of point cloud segmentation remains a huge challenge. At present, most point cloud segmentation methods only extract features based on the original 3D coordinates and color information of point cloud data and have not fully explored the information contained in point cloud data with rich spatial information, especially the problem of insufficient utilization of geometric and color information in large-scale point clouds. In order to effectively address the aforementioned issues, this paper introduces the CMGF-Net, a method for semantic segmentation of point clouds that effectively integrates color information and multi-scale geometric features. In this network, dedicated modules are designed for extracting geometric feature information and semantic feature information. In the geometric feature information extraction path, to fully leverage the geometric characteristics of point cloud data, two feature extraction modules are designed: the Relative Position Feature (RPF) extraction module and the Local Geometry Properties (LGP)extraction module, both focusing on the characteristics of the local neighborhood. In the RPF module, spatial normal information of the 3D point cloud and relative spatial distances are utilized to extract the relative positional relationships between neighboring points and the central point. The LGP module exploits the unique performance characteristics of point cloud geometric properties across different terrains, integrating geometric attribute features from the local region. Subsequently, the designed Local Geometric Feature Fusion module (LGF) combines the extracted feature information from the RPF and LGP modules, yielding fused geometric feature information. Furthermore, to learn multi-scale geometric features from the point cloud, CMGF-Net conducts geometric feature extraction at different scales within the network layers. Eventually, the extracted geometric features are hierarchically fused with semantically extracted features based on color information. By extracting multi-scale geometric features and integrating semantic features, the learning ability of the network is enhanced. The experimental results show that our proposed network model achieves a mean Intersection Over Union (mIoU) of 78.2% and an Overall Accuracy (OA) of 95.0% on the Semantic3D dataset, outperforming KPConv by 3.6% and 2.1%, respectively. On the SensatUrban dataset, it achieves a mIOU of 59.2% and an OA of 93.7%. These findings demonstrate that the proposed network model, CMGF-Net, yields promising results in the segmentation of large-scale outdoor point clouds.
图1 融合颜色信息和多尺度几何特征的点云语义分割方法总技术路线Fig. 1 The overall technical roadmap of integrating color information and multi-scale geometric features for point cloud semantic segmentation |
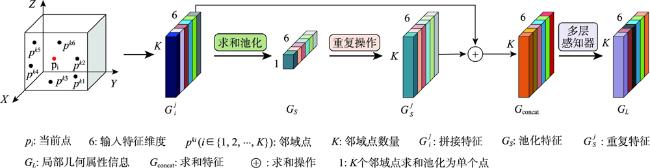
图2 融合颜色信息和多尺度几何特征的点云语义分割网络(CMGF-Net)Fig. 2 Point cloud semantic segmentation network integrating color information and multi-scale geometric features |
表1 Semantic3D数据集上各种方法的对比Tab. 1 Quantitative comparison of IoU, mIoU and OA of the Semantic3D dataSet (%) |
| 类别 | ShellNet[21] | GACNet[22] | KPConv[9] | RandLA-Net[11] | SCF-Net[23] | LFEAM-DCB[24] | 本文方法 |
|---|---|---|---|---|---|---|---|
| 人工地面 | 96.3 | 86.4 | 90.9 | 95.6 | 97.1 | 97.2 | 97.9 |
| 自然地面 | 90.4 | 77.7 | 82.2 | 91.4 | 91.8 | 92.3 | 93.1 |
| 高植被 | 83.9 | 88.5 | 84.2 | 86.6 | 86.3 | 88.2 | 86.5 |
| 低植被 | 41.0 | 60.6 | 47.9 | 51.5 | 51.2 | 51.3 | 53.5 |
| 建筑物 | 94.2 | 94.2 | 94.9 | 95.7 | 95.3 | 96.4 | 95.2 |
| 人造景观 | 34.7 | 37.3 | 40.0 | 51.5 | 50.5 | 43.6 | 45.0 |
| 扫描虚影 | 43.9 | 43.5 | 77.3 | 69.8 | 67.9 | 71.9 | 72.0 |
| 汽车 | 70.2 | 77.8 | 79.7 | 76.8 | 80.7 | 81.3 | 81.9 |
| mIoU | 69.3 | 70.8 | 74.6 | 77.4 | 77.6 | 77.8 | 78.2 |
| OA | 93.2 | 91.9 | 92.9 | 94.8 | 94.7 | 94.9 | 95.0 |
注:加粗数值为所有对比方法中的最优结果。 |
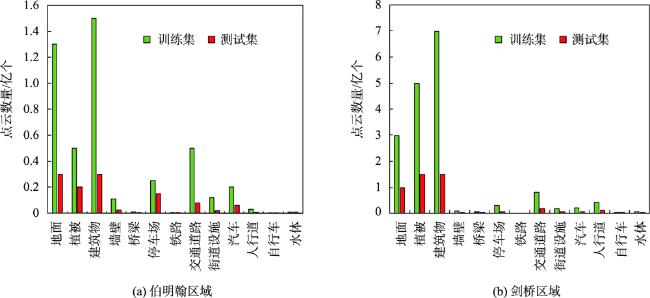
表2 SensatUrban数据集上各种方法的对比Tab. 2 Quantitative comparison of IoU, mIoU and OA of the SensatUrban dataSet |
| 方法 | mIoU | OA | 地面 | 植被 | 建筑 | 墙壁 | 桥梁 | 停车场 | 轨道 | 道路 | 街道设施 | 汽车 | 人行道 | 自行车 | 水 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TangentConv[25] | 33.3 | 76.9 | 71.5 | 91.4 | 75.9 | 35.2 | 0.0 | 45.3 | 0.0 | 26.7 | 19.2 | 67.6 | 0.0 | 0.0 | 0.0 |
| SPGraph[26] | 37.3 | 85.3 | 69.9 | 94.6 | 88.9 | 32.8 | 12.6 | 15.8 | 15.5 | 30.6 | 23.0 | 56.4 | 0.5 | 0.0 | 44.2 |
| SparseConv[27] | 42.7 | 88.7 | 74.1 | 97.9 | 94.2 | 63.3 | 7.5 | 24.2 | 0.0 | 30.1 | 34.0 | 74.4 | 0.0 | 0.0 | 54.8 |
| KPConv[9] | 57.6 | 93.2 | 87.1 | 98.9 | 95.3 | 74.4 | 28.7 | 41.4 | 0.0 | 56.0 | 54.4 | 85.7 | 40.4 | 0.0 | 86.3 |
| RandLA-Net[11] | 58.6 | 91.6 | 83.0 | 98.4 | 93.4 | 57.4 | 49.5 | 55.1 | 27.3 | 60.7 | 39.4 | 84.6 | 39.5 | 0.0 | 74.0 |
| LGS-Net[28] | 60.2 | 92.1 | 84.7 | 98.5 | 94.6 | 59.7 | 69.6 | 49.8 | 27.4 | 57.5 | 43.8 | 81.8 | 42.5 | 0.0 | 72.7 |
| 本文方法 | 59.2 | 93.7 | 86.7 | 99.0 | 96.8 | 78.7 | 46.7 | 50.6 | 0.0 | 60.4 | 53.7 | 84.8 | 42.4 | 0.0 | 69.4 |
注:加粗数值为所有对比方法中的最优结果。 |
表3 Semantic3D数据集上的消融实验结果Tab. 3 Ablation comparison of mIoU and OA of the Semantic3D dataSet |
| 模块 | mIoU% | OA/% | 参数量/百万 | 收敛轮次/次(epoch) |
|---|---|---|---|---|
| KPConv | 74.6 | 92.9 | 14.9 | 400 |
| KPConv + RPF | 77.3 | 94.8 | 15.2 | 330 |
| KPConv + LGP | 77.5 | 94.8 | 15.2 | 310 |
| KPConv(直接拼接几何特征方法) | 76.2 | 93.9 | 14.9 | 400 |
| KPConv + RPF + LGP(本文方法) | 78.2 | 95.0 | 15.3 | 280 |
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
陈科, 管海燕, 雷相达, 等. 基于特征增强核点卷积网络的多光谱LiDAR点云分类方法[J]. 地球信息科学学报, 2023, 25(5):1075-1087.
[
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
李健, 姚亮. 融合多特征深度学习的地面激光点云语义分割[J]. 测绘科学, 2021, 46(3):133-139,162.
[
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
马天恩, 刘涛, 杜萍, 等. 一种聚合全局上下文信息的三维点云语义分割方法[J]. 武汉大学学报(信息科学版),2023:1-16.
[
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
/
| 〈 |
|
〉 |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}