
融合自注意力机制的双向LSTM时空插值模型
|
周啸宇(2000— ),男,山东德州人,硕士生,主要研究方向为空间和时空数据分析。E-mail: zxy17860709661@163.com |
Copy editor: 蒋树芳 , 黄光玉
收稿日期: 2023-09-23
修回日期: 2024-05-12
网络出版日期: 2024-07-24
基金资助
山东省自然科学基金面上项目(ZR2021MD068)
A Bidirectional LSTM Spatiotemporal Interpolation Model with Self-attention Mechanism
Received date: 2023-09-23
Revised date: 2024-05-12
Online published: 2024-07-24
Supported by
Natural Science Foundation of Shandong Province(ZR2021MD068)
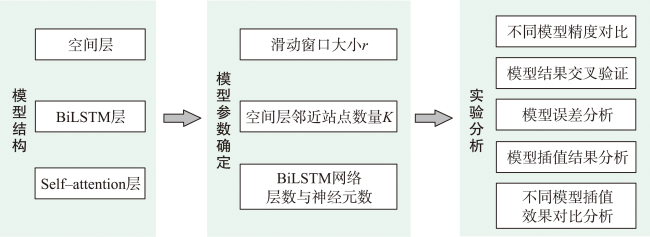
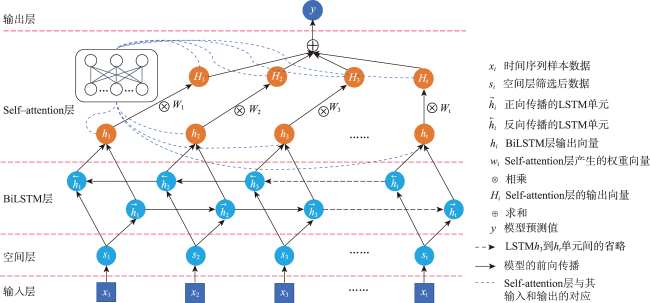
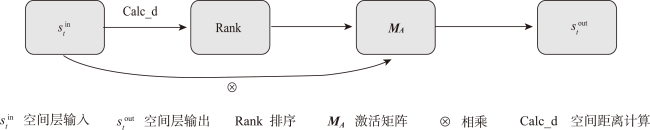
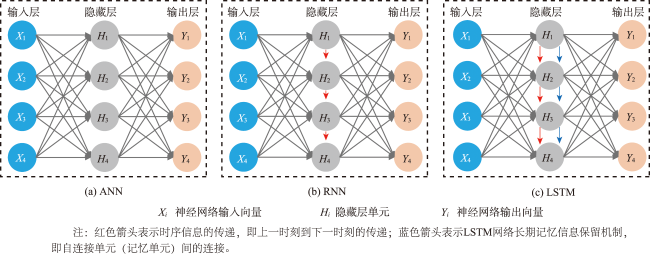
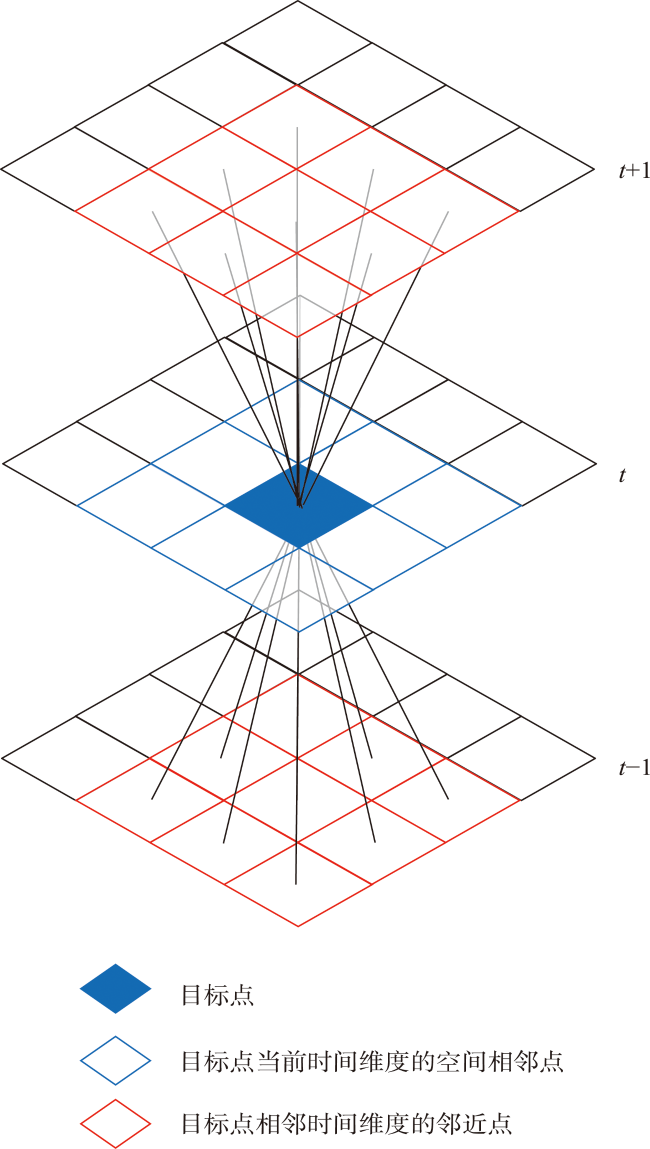
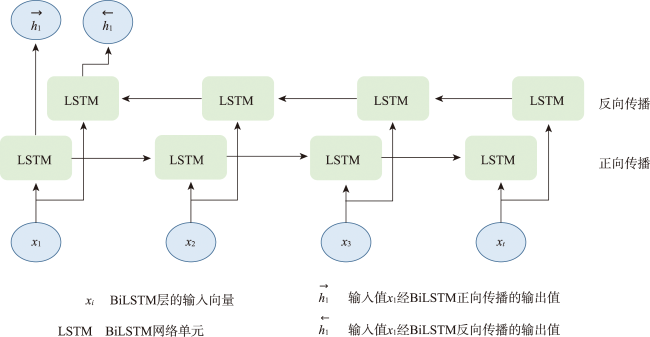
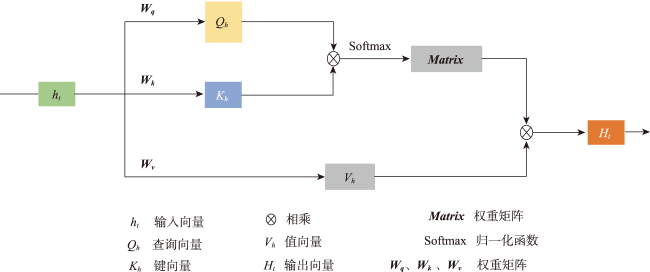
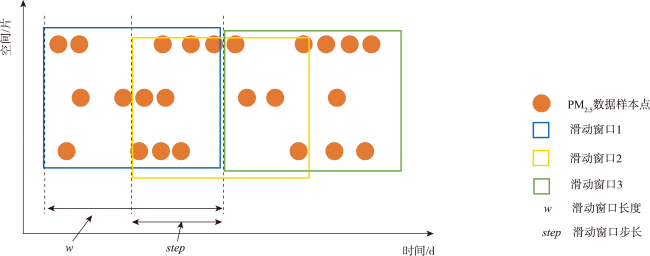
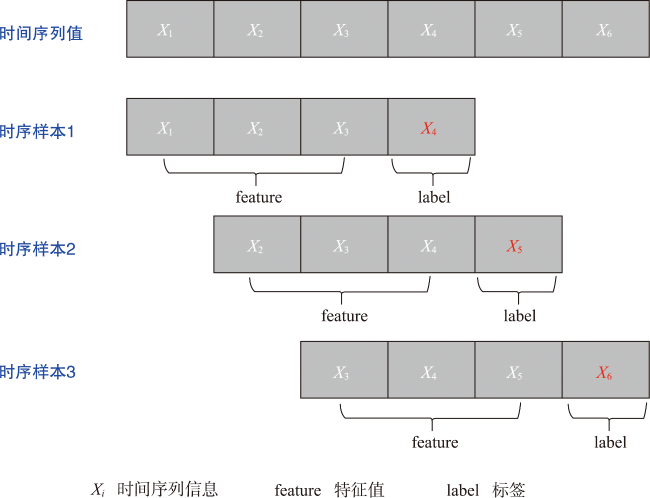
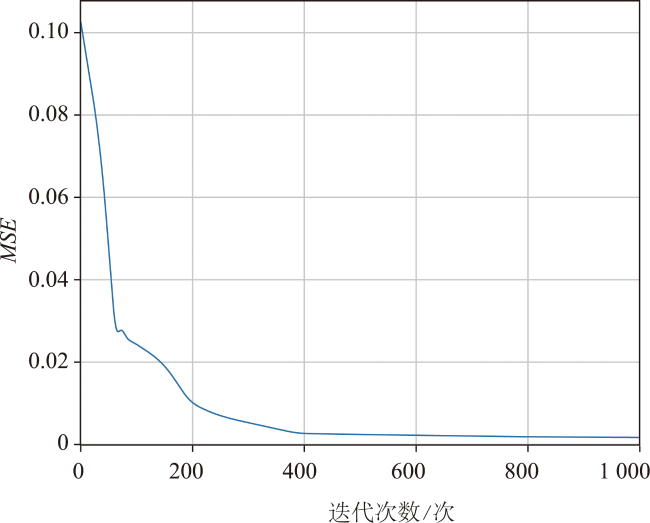
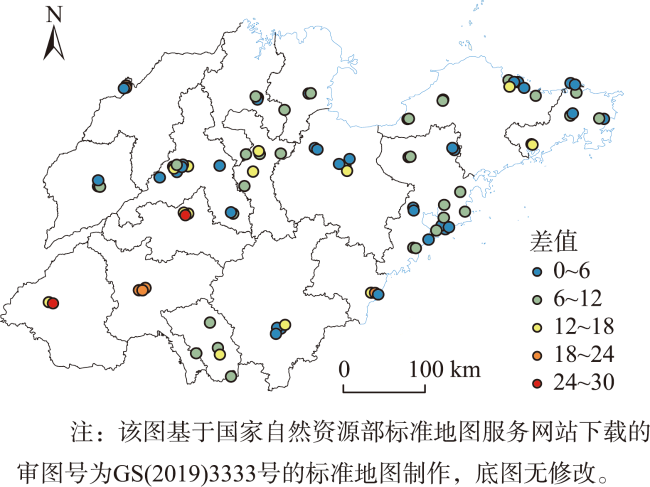
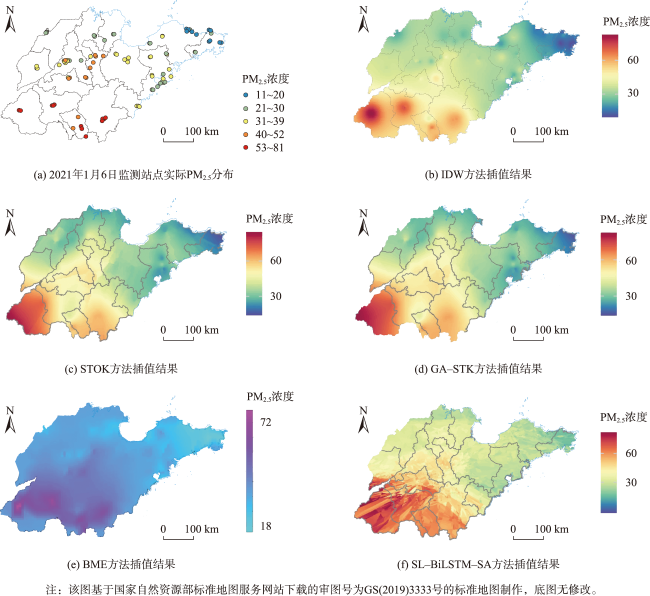
时空插值可以捕获时空数据中的依赖关系,估计地理现象随时间的几何和属性数据变化。现有的时空插值方法大多未同时考虑数据的长期时间相关性以及全局空间信息,本文结合长短时记忆网络LSTM (Long Short Term Memory)与数据的空间特性构建了时空插值模型:①模型利用空间层剔除弱相关性的信息,提取相关性更强的空间信息输入LSTM网络;②由于传统人工神经网络ANN (Artificial Neural Network)模型无法考虑时间对插值的影响以及单向LSTM模型仅能考虑过去时刻对当前时刻的影响而不能利用未来时刻的信息,本文使用双向LSTM模型BiLSTM(Bi-directional LSTM)体现时间相关性;③为了有效提取全局空间特征并保留BiLSTM双向建模的优势,本文将自注意力机制引入BiLSTM中,构建了融合自注意力的双向LSTM插值模型SL-BiLSTM-SA (BiLSTM Model Fused with Spatial Layer-Self attention)。在实验设计阶段,模型被应用于山东省PM2.5浓度数据集进行插值效果研究,并与其它模型进行性能比较。实验表明,SL-BiLSTM-SA模型有着更低的误差度量,相较时空普通克里金STOK (Spatio-Temporal Ordinary Kriging)和遗传算法优化的时空克里金GA-STK (Genetic Algorithm-optimized Spatio-Temporal Kriging)精度分别提高了39.83%、36.63%,且能较准确地预测高值和低值。本文融合空间信息,结合BiLSTM和Self-attention构建了时空插值模型,扩展了时空数据的插值手段,为时空数据分析提供了一定的理论和方法支撑。
周啸宇 , 王海起 , 王琼 , 单宇飞 , 闫峰 , 李发东 , 刘峰 , 曹元昊 , 欧雅玟 , 李雪莹 . 融合自注意力机制的双向LSTM时空插值模型[J]. 地球信息科学学报, 2024 , 26(8) : 1827 -1842 . DOI: 10.12082/dqxxkx.2024.230574
Spatial-temporal data missingness and sparsity are prevalent phenomena, for which spatial-temporal interpolation serves as a critical methodology to address these issues. Spatial-temporal interpolation constitutes a significant research domain within the field of Geographical Information Science. This technique enables the capture of dependencies in spatial-temporal data and the estimation of the geometric and attribute variations of geographical phenomena over time. With the advancement of geospatial technologies, particularly Geographic Information Systems, contemporary spatial-temporal interpolation methods predominantly rely on statistical, machine learning, and deep learning approaches that account for both temporal and spatial dimensions. These methods aim to reveal the evolutionary processes and spatial-temporal distribution patterns inherent in the data. However, a majority of such techniques often overlook long-term dependencies and contextual spatial information when interpolating. This study proposes an innovative model that intertwines Long Short-Term Memory (LSTM) networks with spatial attributes to address these limitations effectively. The proposed model operates through several key stages: (1) It employs a dedicated spatial layer to systematically eliminate weakly correlated information, focusing on extracting and feeding more significantly correlated spatial data into the LSTM network. (2) Given that conventional Artificial Neural Network (ANN) models are unable to consider the impact of the temporal dimension on interpolation, and unidirectional LSTM models can only factor in past moments' influence without utilizing future moment information, this research adopts a Bidirectional LSTM (BiLSTM) architecture. The BiLSTM inherently captures both spatial and temporal dependencies, thereby overcoming previous limitations. (3) To further enhance its performance by efficiently extracting comprehensive global spatial features while maintaining the advantages of bidirectional modeling offered by BiLSTM, we integrate a self-attention mechanism into the BiLSTM framework. This results in a novel, fused Bidirectional LSTM Interpolation Model with Spatial Layer-Self Attention (SL-BiLSTM-SA). In the experimental phase, the SL-BiLSTM-SA model is rigorously applied to a PM2.5 concentration dataset from Shandong Province to conduct a meticulous investigation into its interpolation capabilities. Upon comparative analysis against other models, it is evident that the SL-BiLSTM-SA model outperforms with notably lower error metrics, demonstrating substantial improvements in accuracy—by 39.83% and 36.63% when compared to Spatio-Temporal Ordinary Kriging (STOK) and Genetic Algorithm-optimized Spatio-Temporal Kriging (GA-STK) methods, respectively. Moreover, our model exhibits commendable precision in forecasting high and low concentration levels. By seamlessly integrating spatial information and coupling the strengths of BiLSTM with self-attention mechanisms, this research not only extends the suite of interpolation methods for spatiotemporal data analysis but also furnishes robust theoretical underpinnings and methodological support to facilitate sophisticated spatiotemporal data analyses.
表1 空气污染物浓度指标含义Tab. 1 Meaning of air pollution concentration index |
| 字段 | 字段说明 |
|---|---|
| so2_24h | 二氧化硫24 h滑动平均 |
| no2_24h | 二氧化氮24 h滑动平均 |
| co_24h | 一氧化碳24 h滑动平均 |
| o3_8h_24h | 臭氧日最大8 h滑动平均 |
| o3_24h | 臭氧日最大1 h平均 |
| pm10_24h | 颗粒物(粒径小于等于10 μm) 24 h滑动平均 |
| pm2.5_24h | 颗粒物(粒径小于等于2.5 μm) 24 h滑动平均 |
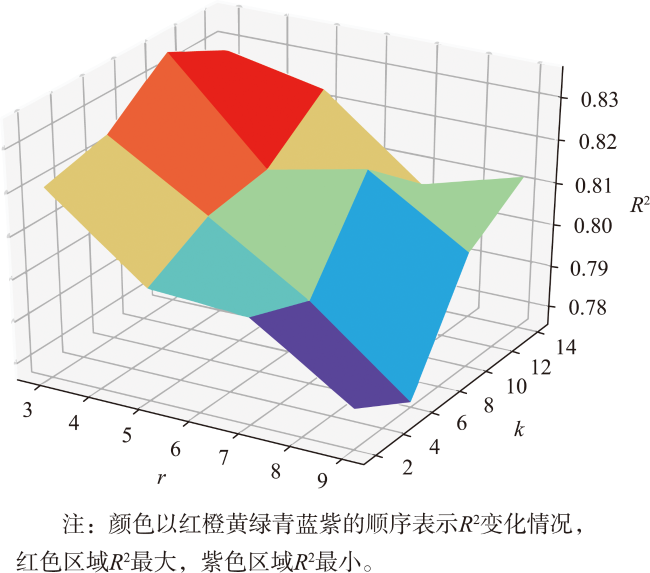
表2 站点数量与滑动窗口长度不同组合的R2Tab. 2 R2 with different combinations of station count and sliding window length |
| 站点数量K | R2 | |||
|---|---|---|---|---|
| r=3 | r=5 | r=7 | r=9 | |
| 2 | 0.820 7 | 0.802 5 | 0.801 2 | 0.785 5 |
| 6 | 0.824 3 | 0.810 3 | 0.795 7 | 0.777 0 |
| 10 | 0.835 3 | 0.812 6 | 0.817 6 | 0.803 2 |
| 14 | 0.828 2 | 0.823 4 | 0.805 6 | 0.812 2 |
注:加粗字体表示R2最大值。 |
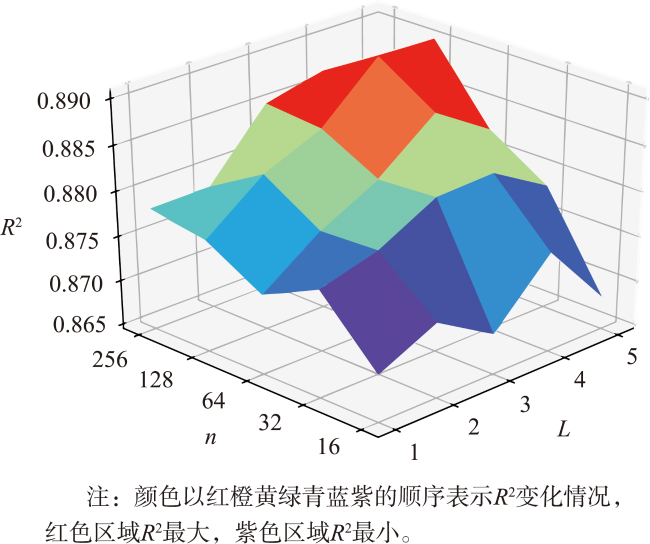
表3 BiLSTM层数和每层神经元数量不同组合的R2Tab. 3 R2 with different combinations of BiLSTM layer depths and neurons counts per layer |
| 神经元数量/个 | R2 | ||||
|---|---|---|---|---|---|
| L=1 | L=2 | L=3 | L=4 | L=5 | |
| 16 | 0.869 8 | 0.872 9 | 0.869 0 | 0.875 6 | 0.868 1 |
| 32 | 0.876 5 | 0.878 3 | 0.881 7 | 0.882 0 | 0.878 3 |
| 64 | 0.873 4 | 0.878 0 | 0.881 3 | 0.886 3 | 0.882 3 |
| 128 | 0.877 0 | 0.881 9 | 0.884 6 | 0.890 4 | 0.890 2 |
| 256 | 0.878 1 | 0.878 2 | 0.885 2 | 0.886 7 | 0.882 8 |
注:加粗数值表示R2最大值。 |
表4 不同模型的精度比较Tab. 4 Accuracy comparison of different models |
| 插值模型 | R2 | RMSE | MAE | MAPE |
|---|---|---|---|---|
| STOK | 0.741 2 | 13.905 6 | 11.165 5 | 19.324 2 |
| GA-STK | 0.781 6 | 13.202 0 | 10.906 0 | 18.652 6 |
| SL-LSTM | 0.890 4 | 8.639 0 | 7.855 0 | 10.566 3 |
| SL-BiLSTM-SA | 0.902 8 | 8.366 5 | 7.783 3 | 10.342 4 |
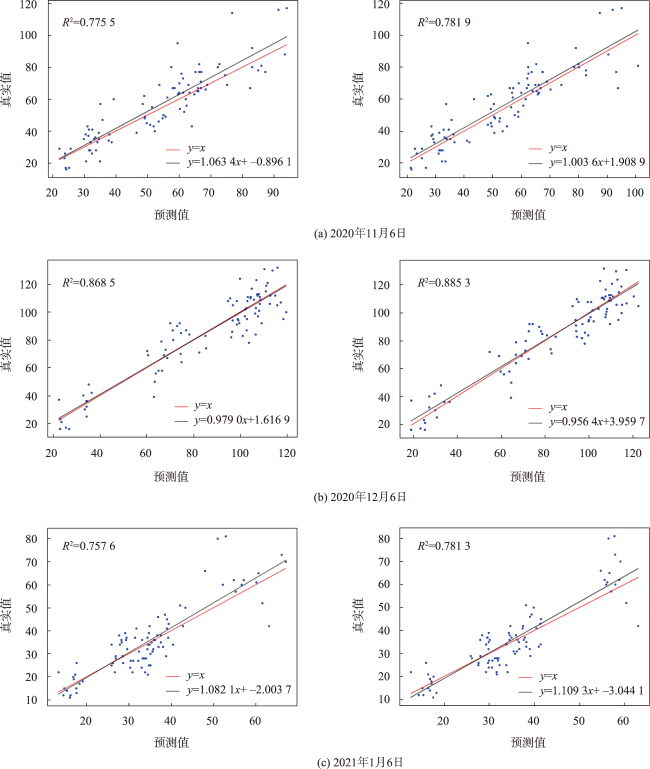
表5 SL-BiLSTM-SA模型精度评价Tab. 5 SL-BiLSTM-SA model accuracy evaluation |
| 日期 | R2 | RMSE | MAE | MAPE |
|---|---|---|---|---|
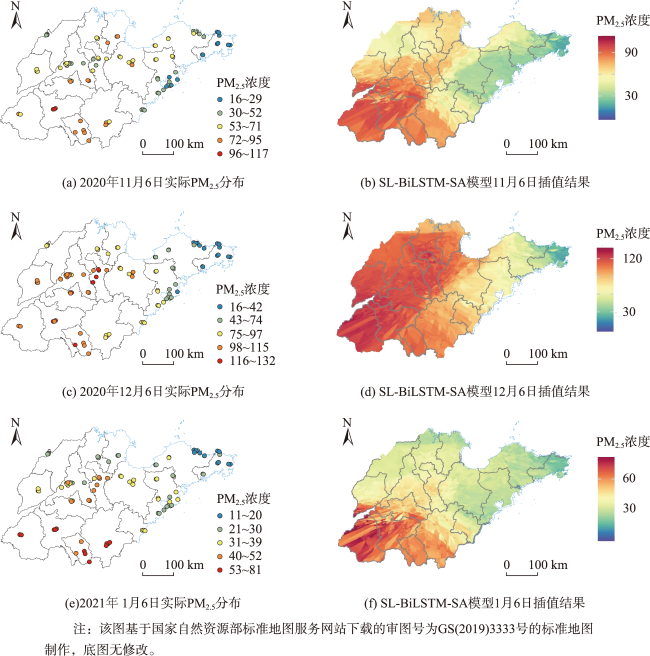
| 2020年11月6日 | 0.781 9 | 8.443 9 | 6.106 3 | 13.776 6 |
| 2020年12月6日 | 0.885 3 | 9.366 5 | 7.392 8 | 10.194 2 |
| 2021年1月6日 | 0.781 3 | 6.189 7 | 5.554 7 | 14.928 7 |
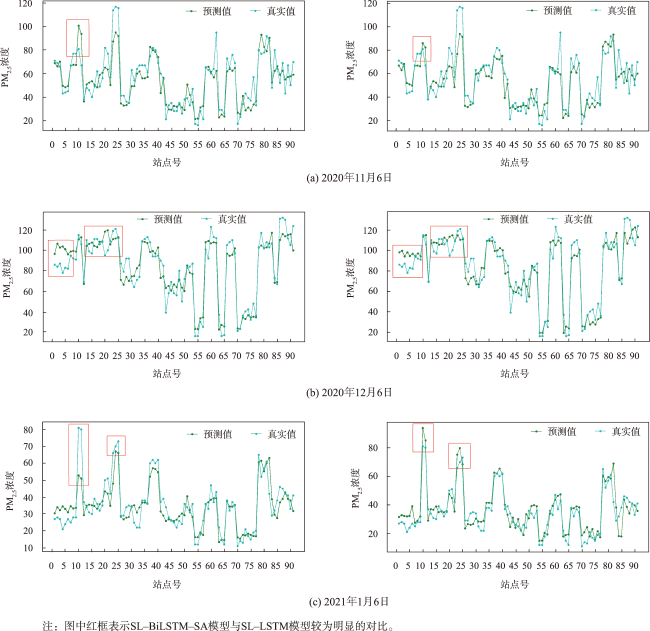
图14 SL-LSTM(左)和SL-BiLSTM-SA(右)模型预测值与真实值对比折线图Fig. 14 Line graph comparing predicted values and actual values for SL-LSTM (left) and SL-BiLSTM-SA (right) models. |
| [1] |
|
| [2] |
徐文, 黄泽纯, 张倩宁. 基于时空模型的PM2.5预测与插值[J]. 江苏师范大学学报(自然科学版), 2016, 34(3):70-75.
[
|
| [3] |
|
| [4] |
|
| [5] |
梅杨. 时空克里格方法关键技术及其应用研究[D]. 武汉: 华中农业大学, 2016.
[
|
| [6] |
徐明轩, 缪燕子, 杜盈昌, 等. 基于时空扩展模型的瓦斯浓度场重构[J]. 中国矿业大学学报, 2021, 50(4):658-666.
[
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
黎嵘繁, 钟婷, 吴劲, 等. 基于时空注意力克里金的边坡形变数据插值方法[J]. 计算机科学, 2022, 49(8):33-39.
[
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
张文朝, 李超朋, 郑梅, 等. 近50年山东省降水特征分析[J]. 可持续发展, 2020, 10(3):473-479.
[
|
| [19] |
魏文静, 谢炳庚, 周楷淳, 等. 2013—2018年山东省大气PM2.5和PM10污染时空变化及其影响因素[J]. 环境工程, 2020, 38(12):103-111.
[
|
| [20] |
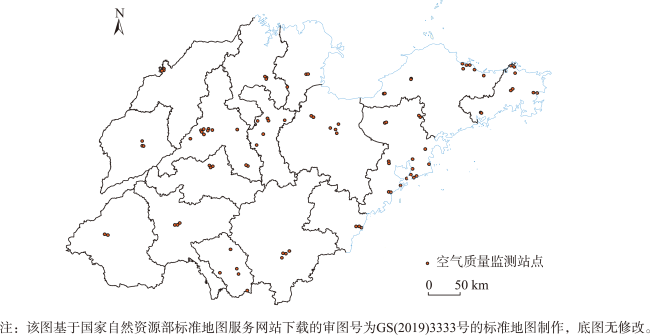
上海青悦环保信息技术服务中心. 2020年11月1日—2021年1月31日山东省国控空气质量监测站点数据[EB/OL]. https://www.epmap.org
[ Shanghai qingyue environmental information technology service center. Data from national air quality monitoring sites in Shandong Province, November 1, 2020—January 31, 2021[EB/OL]. https://www.epmap.org
|
| [21] |
国家基础地理信息中心. 山东省矢量地图数据[EB/OL]. https://www.ngcc.cn
[ National geomatics center of China. Shandong Province vector map data[EB/OL]. https://www.ngcc.cn.]
|
| [22] |
黄伟建, 李丹阳, 黄远. 基于深度学习的PM2.5浓度长期预测[J]. 计算机应用研究, 2021, 38(6):1809-1814.
[
|
| [23] |
|
| [24] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}