
应用多尺度融合策略和改进YOLOV5的道路病害无人机检测
|
程传祥(2001— ),男,河南信阳人,硕士,主要从事无人机摄影测量与遥感影像智能解译等研究。E-mail: chuanxiangcheng@163.com |
Copy editor: 黄光玉
收稿日期: 2024-03-19
修回日期: 2024-05-14
网络出版日期: 2024-07-24
Road Damage Detection in Large UAV Images Using a Multiscale Fusion Strategy and Improved YOLOV5
Received date: 2024-03-19
Revised date: 2024-05-14
Online published: 2024-07-24
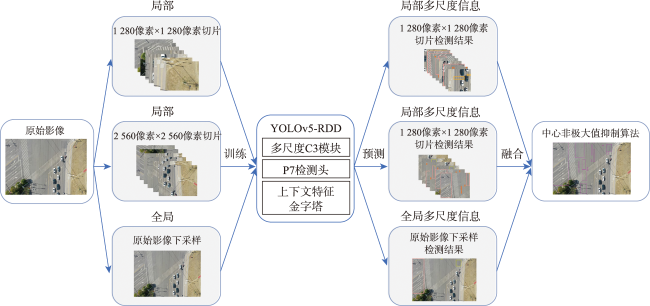
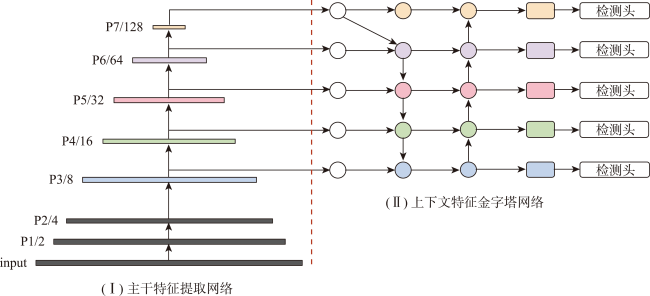
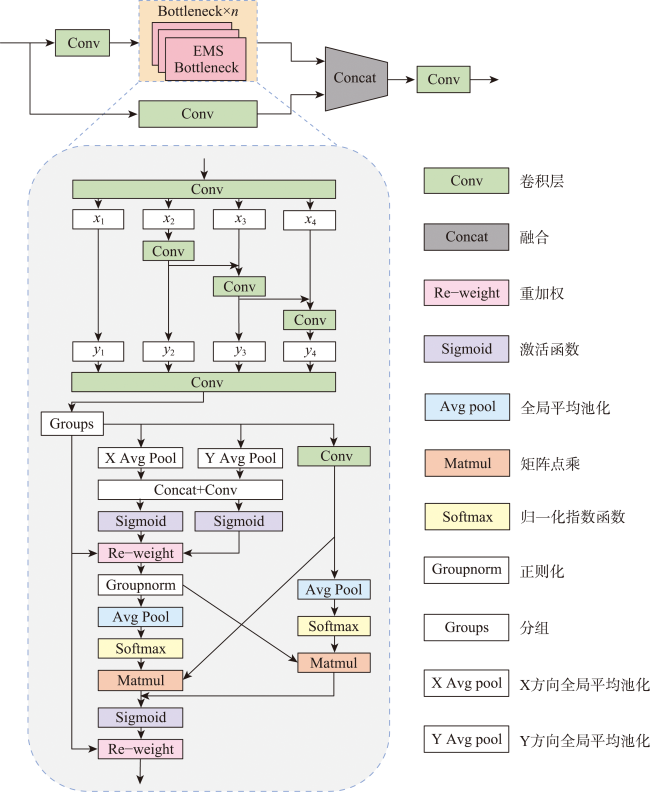
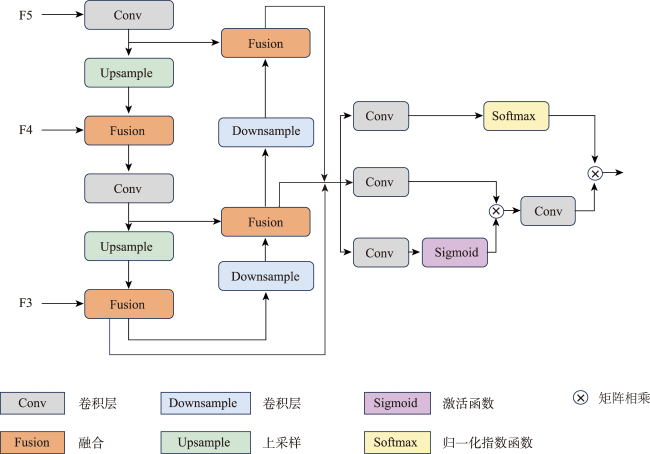
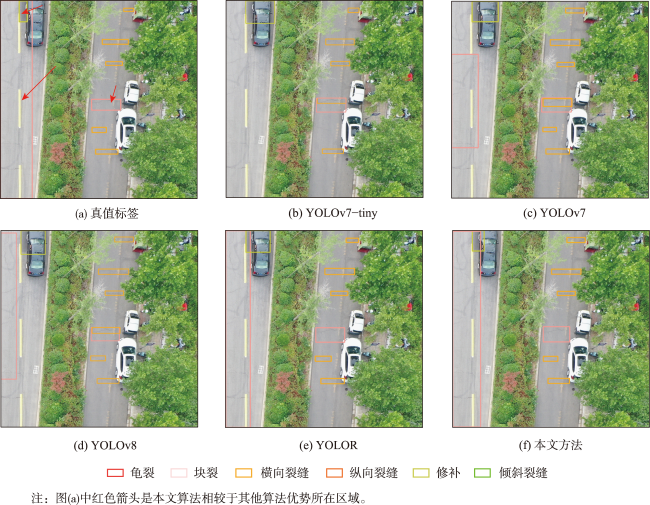
结合无人机和深度学习目标检测算法自动检测道路病害具有范围广、成本效益高等优势。然而,道路病害的形状和 大小变化剧烈,很难完整检测它们。此外,受限于计算资源,通用的目标检测算法只适用于小尺寸影像(512像素×512像素或640像素×640像素),很难直接应用于大尺寸的无人机影像(5 472像素×3 648像素或7 952像素×5 304像素)。使用传统方法检测大尺寸影像中的多尺度目标会出现大尺寸目标切分、小尺寸目标漏检等问题。针对上述问题,本文提出了一种结合全局-局部多尺度融合策略和YOLOv5-RDD的创新解决方案。① 构建了YOLOv5-RDD模型,在现有YOLOv5模型的基础上,设计多尺度C3(MSC3)模块和上下文特征金字塔网络(CFPN),增强了对多尺度目标的检测能力。② 提出了一种全局-局部多尺度融合策略,利用下采样和切分手段获取大尺寸无人机影像的全局和局部信息,然后叠加全局和局部多尺度信息以获取整个大尺寸影像的多尺度信息,并采用中心非极大值抑制算法优化检测结果。③ 为验证所提方法的有效性,创建了一个专门用于无人机道路病害检测的UAV-RDD数据集。实验结果显示,与原始的YOLOv5模型相比,新模型YOLOv5-RDD在mAP上提升了5.8%,而全局-局部多尺度融合策略相比传统方法在mAP上提升了9.73%,充分证明了本文方法的有效性和优越性。

程传祥 , 金飞 , 林雨准 , 王淑香 , 左溪冰 , 李军杰 , 苏凯阳 . 应用多尺度融合策略和改进YOLOV5的道路病害无人机检测[J]. 地球信息科学学报, 2024 , 26(8) : 1991 -2007 . DOI: 10.12082/dqxxkx.2024.240147
The use of Unmanned Aerial Vehicles (UAVs) for road image collection is advantageous owing to their large scope and cost-effectiveness. However, the size and shape of road damages vary significantly, making them challenging to predict. Furthermore, due to the limitations of computational resources, generalized target detection algorithms are only applicable to small-size images (512 pixels× 512 pixels or 640 pixels× 640 pixels). This makes them unsuitable for direct application to large-size UAV images (5 472 pixels× 3 648 pixels or 7 952 pixels × 5 304 pixels). The utilization of traditional methods for the detection of multi-scale targets in large-size images is associated with a number of issues, including the slicing of large-size targets and the failure to detect small-size targets. To address these challenges, this paper presents an innovative solution that combines the global-local multiscale fusion strategy with YOLOv5-RDD. First, a YOLOv5-RDD model is constructed, and based on the existing YOLOv5 model, a multiscale C3 (MSC3) module and a Contextual Feature Pyramid Network (CFPN) are designed to improve the detection capability of multiscale targets. Additionally, we introduce an extra detection head for larger-size targets. Then, a global-local multiscale fusion strategy is proposed, which uses resizing and slicing means to obtain global and local information of large UAV images, and then superimposes the global and local multiscale information to obtain the multi-scale information of the whole large image. The detection results are optimized using the center non-maximum value suppression algorithm. Specifically, the global-local multiscale fusion strategy first trains the YOLOv5-RDD using multiscale training strategy to learn complete multiscale features. Then, YOLOv5-RDD predicts multiscale road damages in large-size images using a multiscale prediction strategy to avoid directly applying it to these images. Finally, we use center non-maximum suppression to eliminate redundant object detection boxes. To verify the effectiveness of the proposed method and meet real-world requirements, a UAV-RDD dataset specialized for UAV road disease detection is created. The experimental results show that compared with the original YOLOv5 model, the new model YOLOv5-RDD improves the mAP by 5.8%, while the global-local multiscale fusion strategy improves the mAP by 9.73% compared with the traditional method. The MSC3 achieves the maximum enhancement of mAP@0.5, with an improvement of 2.6%, contributing only 0.8 M parameters. The CFPN yields an improvement of 0.2% in mAP@0.5 while reducing the number of parameters by 8 M. These results fully prove the effectiveness and superiority of the method in this paper.
| 算法 1 中心非极大值抑制算法 |
|---|
| 输入: B = {}, S = { ,…, SN}, IOUt, μ, λ, MS = {}, A = {area1,…,ar eaN} |
| B 是一个包含所有目标检测框的列表 |
| S是一个包含所有目标检测框的相应置信度分数的列表 |
| A是一个包含所有检测框面积的列表 |
| IOUt 是IOU的阈值 (0.5) |
| μ 是面积权重 |
| λ 是置信度权重 |
| MS 是一个空列表 |
| 输出: K |
| K 是经过中心非极大值抑制处理之后的列表 |
| K←{} |
| areamax← 计算列表B中的最大面积 |
| MS←μ×A/areamax+λ×S |
| while MS ≠ 空列表 |
| m←argmaxMS |
| M ←bm K ←bm |
| if IOU(M, bi) >IOUt |
| B←B-bi; S ←S-Si |
| end if |
| if IOU(M, bi) <=IOUt |
| if bi 的中心在 M的范围内 |
| B←B-bi |
| end if |
| end if |
| return K |
| end while |
表1 无人机获取道路表面影像的航摄参数Tab. 1 Aerial photography parameters for UAV acquisition of road surface images |
| 影像尺寸/(像素×像素) | 传感器尺寸/(mm×mm) | 焦距/mm | 曝光时间/s | 重叠率/% | 飞行高度/m | 飞行速度/(m/s) |
|---|---|---|---|---|---|---|
| 5 472 3 648 | 12.7 9.6 | 35 | 1/320 | 70 | 30~50 | 8 |
表2 UAV-RDD数据集道路病害类别与样本信息Tab. 2 Category of road damage objects and sample information of UAV-RDD data set (个) |
| 类别序号 | 类别名称 | 训练样本集 | 验证样本集 | 测试样本集 | 总计 |
|---|---|---|---|---|---|
| 1 | 龟裂 | 269 | 114 | 69 | 452 |
| 2 | 块裂 | 678 | 244 | 248 | 1 170 |
| 3 | 纵向裂缝 | 509 | 132 | 138 | 779 |
| 4 | 横向裂缝 | 835 | 228 | 220 | 1 283 |
| 5 | 修补 | 270 | 75 | 51 | 396 |
| 6 | 倾斜裂缝 | 59 | 19 | 25 | 103 |
表3 YOLOv5-RDD对比实验Tab. 3 YOLOv5-RDD comparison experiments |
| 方法 | 参数量/M | FLOPs/G | 精确率 | 召回率 | mAP@0.5 | mAP@0.5:0.95 | FPS |
|---|---|---|---|---|---|---|---|
| YOLOv7 | 71.5 | 103.2 | 0.490 | 0.565 | 0.480 | 0.272 | 25.7 |
| YOLOv8 | 83.7 | 164.8 | 0.564 | 0.484 | 0.509 | 0.263 | 27.5 |
| YOLOR | 71.0 | 80.2 | 0.532 | 0.539 | 0.516 | 0.316 | 30.8 |
| YOLOv7-tiny | 11.7 | 13.1 | 0.454 | 0.433 | 0.405 | 0.217 | 58.8 |
| 本文方法 | 32.9 | 24.9 | 0.592 | 0.593 | 0.585 | 0.355 | 49.7 |
注:加粗数值表示其在所有方法中效果最好。 |
表4 YOLOv5-RDD消融实验Tab. 4 YOLOv5-RDD ablation experiment |
| 方法 | 参数量 /M | FLOPs /G | mAP@0.5 | mAP@0.5:0.95 |
|---|---|---|---|---|
| YOLOv5s6 (基础网络) | 24.6 | 16.2 | 0.527 | 0.320 |
| + P7 检测头 | 46.5 | 16.9 | 0.538 | 0.319 |
| +CFPN | 16.6 | 14.6 | 0.529 | 0.320 |
| +MSC3 | 25.4 | 15.8 | 0.553 | 0.335 |
| YOLOv5-RDD | 32.9 | 24.9 | 0.585 | 0.355 |
注:加粗方法表示它在所有方法中效果最好。 |
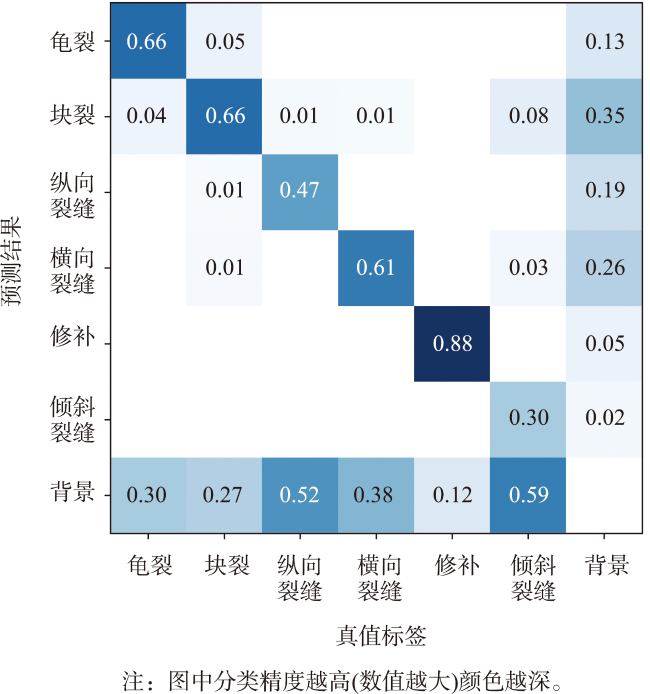
表5 YOLOv5-RDD在UAV-RDD测试集上的效果Tab. 5 YOLOv5-RDD performance on the UAV-RDD test set |
| 类别名称 | 精确率 | 召回率 | AP@0.5 | AP@0.5:0.95 |
|---|---|---|---|---|
| 所有 | 0.592 | 0.593 | 0.585 | 0.355 |
| 龟裂 | 0.486 | 0.671 | 0.614 | 0.368 |
| 块裂 | 0.702 | 0.670 | 0.746 | 0.519 |
| 纵向裂缝 | 0.468 | 0.458 | 0.412 | 0.153 |
| 横向裂缝 | 0.643 | 0.586 | 0.613 | 0.273 |
| 修补 | 0.698 | 0.848 | 0.828 | 0.661 |
| 倾斜裂缝 | 0.557 | 0.324 | 0.299 | 0.136 |
表6 YOLOv5-RDD在UAPD测试集上的对比实验Tab. 6 YOLOv5-RDD comparison experiments on the UAPD test set |
| 方法 | ||||||
|---|---|---|---|---|---|---|
| TOOD | YOLOv5 | Grid R-CNN | Cross-Pooling | YOLOv8 | 本文方法 | |
| mAP | 48.2 | 52.4 | 53.4 | 55.6 | 56.9 | 59.4 |
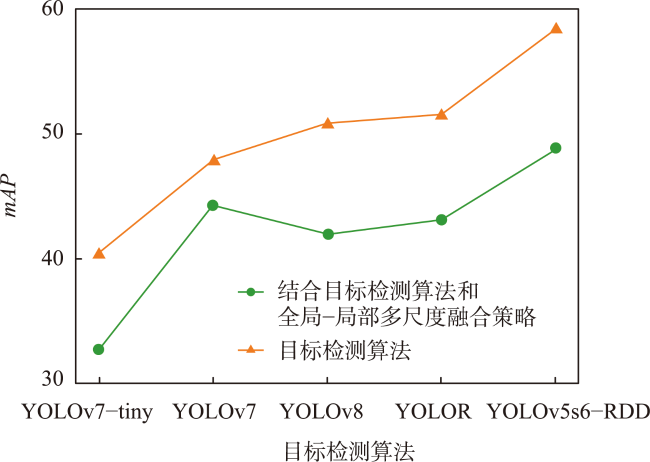
表7 全局-局部多尺度融合策略的对比实验Tab. 7 Comparative experiments on global-local multiscale fusion strategy (%) |
| 方法 | mAP@0.5 |
|---|---|
| 切分 | 26.89 |
| 多分辨率图像联合检测 | 39.09 |
| 下采样 | 25.25 |
| 本文方法 | 48.82 |
表8 全局-局部多尺度融合策略的消融实验Tab. 8 Ablation experiments with a global-local multiscale fusion strategy (%) |
| 案列 | 非极大值抑制算法 | 中心非极大值抑制算法 | 尺度1 | 尺度2 | 尺度3 | 多尺度训练策略 | mAP@0.5 |
|---|---|---|---|---|---|---|---|
| 案例1 | √ | √ | √ | 36.11 | |||
| 案例2 | √ | √ | √ | 30.41 | |||
| 案例3 | √ | √ | √ | 38.90 | |||
| 案例4 | √ | √ | √ | √ | 38.27 | ||
| 案例5 | √ | √ | √ | √ | 39.14 | ||
| 案例6 | √ | √ | √ | √ | 38.76 | ||
| 案例7 | √ | √ | √ | √ | 45.18 | ||
| 案例8 | √ | √ | √ | √ | √ | 43.49 | |
| 案例9 | √ | √ | √ | 39.44 | |||
| 案例10 | √ | √ | √ | 39.52 | |||
| 案例11 | √ | √ | √ | 39.55 | |||
| 案例12 | √ | √ | √ | √ | 43.11 | ||
| 案例13 | √ | √ | √ | √ | 43.80 | ||
| 案例14 | √ | √ | √ | √ | 47.54 | ||
| 案例15 | √ | √ | √ | √ | 47.78 | ||
| 案例16 | √ | √ | √ | √ | √ | 48.82 |
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
聂光涛, 黄华. 光学遥感图像目标检测算法综述[J]. 自动化学报, 2021, 47(8):1749-1768.
[
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
柳雨豪. 无人机连续道路图像病害智能识别研究[D]. 南京: 东南大学, 2022.
[
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
/
| 〈 |
|
〉 |




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}