
一种基于可达距离的模糊C均值聚类算法
|
崔俊超(1998— ),女,山西长治人,硕士生,主要研究方向为智能计算与智能信息处理。E-mail: jccui@mail.hnust.edu.cn |
Editor: 蒋树芳
收稿日期: 2024-01-23
修回日期: 2024-07-29
网络出版日期: 2024-09-10
基金资助
国家自然科学基金青年项目(62107013)
湖南省教育厅优秀青年项目(22B0511)
A Fuzzy C-Means Clustering Algorithm Based on Reachable Distance
Received date: 2024-01-23
Revised date: 2024-07-29
Online published: 2024-09-10
Supported by
National Natural Science Foundation of China Youth Project(62107013)
Hunan Provincial Education Department Scientific Research Project(22B0511)
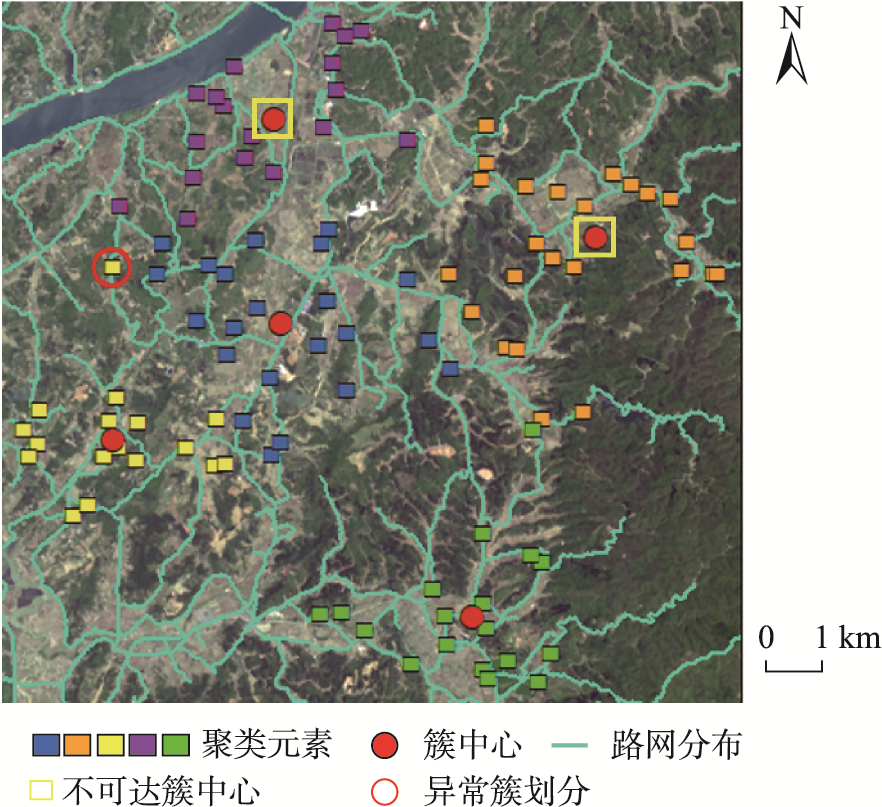
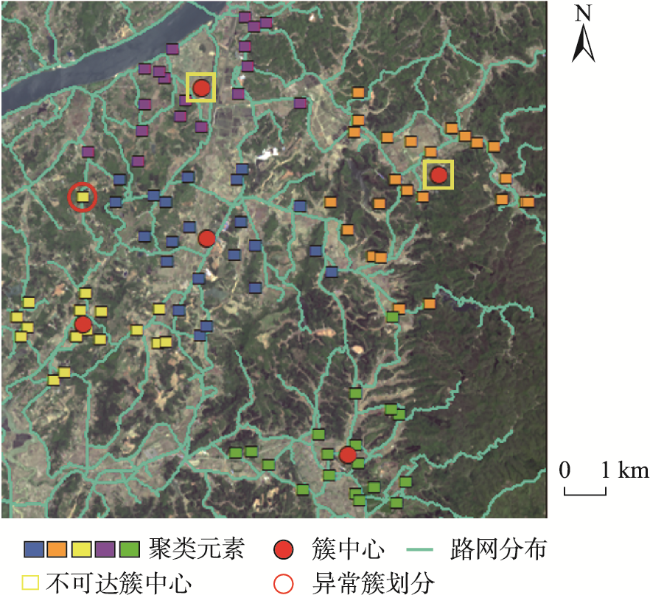
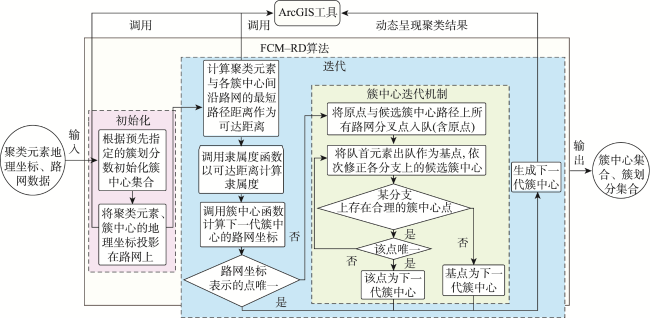
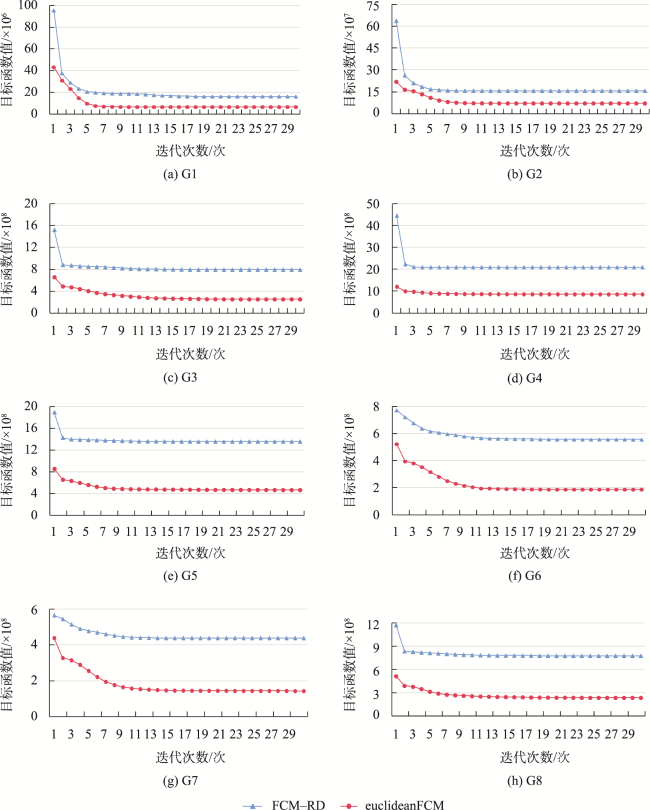
设施选址对提高居民生活质量至关重要,利用地理可达相似性聚类对空间元素进行分类是求解此类问题的重要方法。然而,现有的应用于地理可达性分析的聚类算法存在地理可达性测度不准确、不涉及簇中心选取或簇中心不可达等缺陷,不能有效求解真实场景下的设施选址问题。基于此,本文提出一种基于可达距离的模糊C均值聚类算法(Fuzzy C-Means based on Reachable Distance, FCM-RD)。FCM-RD算法改造了经典FCM算法的目标函数、隶属度函数和簇中心函数,使其适用基于可达距离的聚类分析。其次,以沿路网的最短路径距离作为可达距离衡量元素间的地理可达相似性,将聚类元素的二维地理坐标映射为路网坐标,并以此设计簇中心迭代机制,实现在聚类过程中以可达距离迭代不受约束的可达簇中心。同时,对所提簇中心迭代机制的有效性进行理论分析和实验验证,结果表明,FCM-RD算法在每次迭代中所选的各簇簇中心唯一且为当前簇类目标函数最小值点。最后,基于真实地理场景的仿真实验表明,相比基准算法,FCM-RD不仅能获得位置不受限的可达簇中心,而且能获得更好的聚类效果,为实际场景下的地理空间聚类方案提供了有效且精准的解决方案。
崔俊超 , 张琼冰 , 李小龙 . 一种基于可达距离的模糊C均值聚类算法[J]. 地球信息科学学报, 2024 , 26(9) : 2038 -2051 . DOI: 10.12082/dqxxkx.2024.240053
Facility location is of great significance for improving residents’ quality of life, and geographic accessibility indicators, such as the road network, are often used as the main decision-making factors. Clustering analysis based on geographic accessibility is an important tool for solving such problems. However, existing clustering algorithms often fail to guarantee the accuracy of clustering results, the accessibility of cluster centers, or the selectivity of cluster centers, making them less effective in solving the facility location problem in real scenarios. This paper proposes a Fuzzy C-Means clustering algorithm based on Reachable Distance (FCM-RD), which modifies the objective function, the membership function, and the cluster center function of the classical FCM. It employs reachable distance as a measure of geographic reachable similarity and iterates the cluster centers during the clustering process. Specifically, to capture the true relationships and connectivity between different elements, FCM-RD takes into account physical and spatial barriers, employs the shortest path distance along the road network as the reachable distance, and aligns geographic coordinates with the road network. It is possible for one position on the road network to correspond to multiple positions in geographic coordinates. Consequently, when multiple candidate positions for cluster centers are obtained, a cluster center correction mechanism is designed to iterate the accessible cluster center with reachable distance during the clustering process. Mathematical analysis and experiments in actual scenarios both show the validity of the cluster center iteration mechanism, showing the selected cluster centers in each iteration of FCM-RD are the unique and minimum value points of the intra-cluster objective function. The rationality of FCM-RD is further verified through experiments, and it is compared with baseline algorithms from three aspects: experimental results, convergence, and performance. The results indicate that, compared to the baseline algorithms, FCM- RD improves performance on both the mean and maximum indicators of the shortest reachable distance, with some indicators even improving by up to 38.9%. In a few experiments, there are slight improvements in the DB index and silhouette coefficient indicators, and 100% of the cluster centers selected by FCM- RD are located on the road network. FCM- RD overcomes the shortcomings of ignoring geographical obstacles and unreachable cluster centers. In conclusion, FCM-RD not only obtains accessible cluster centers without location restrictions but also achieves better clustering results. FCM-RD provides an effective and precise solution for geographical spatial clustering in practical scenarios.
表1 符号说明Tab. 1 Symbol description |
| 符号 | 说明 |
|---|---|
| X = { x1, x2, ⋯, xj, xj+1, ⋯, xn },n∈N* | 聚类元素集合,n表示聚类元素个数 |
| C = {c1, c2, ⋯, ci, ci+1, ⋯, cd},d∈N*且d≤n | 簇中心集合,d表示簇中心个数 |
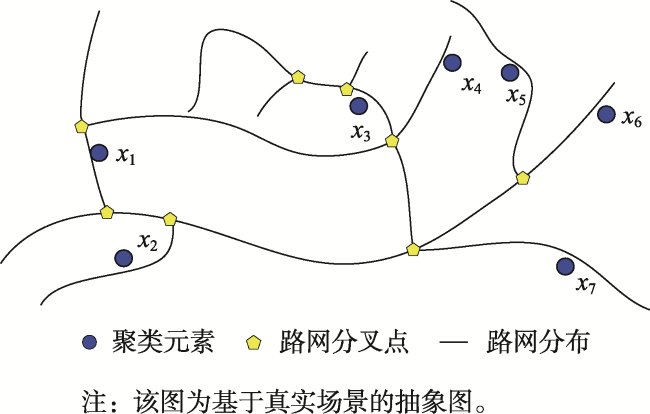
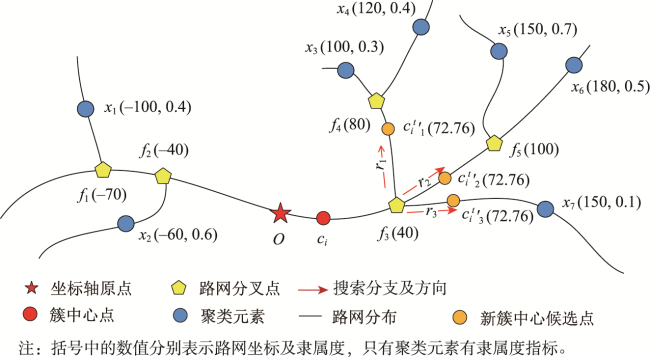
| F = {f1, f2, ⋯, fk, fk+1, ⋯, fv },v ∈ N* | 路网分叉点集合,v表示路网分叉点个数 |
| R(fk) = { r1, r2, ⋯, rq, rq+1, ⋯, rs },s∈N* | 分叉点搜索方向上的分支集合,s表示分支条数 |
| Y = {y | y ∈ X∪C∪F} | 聚类场景元素集合 |
| L(y) | 元素 y(包括聚类元素、分叉点、簇中心等)的路网坐标,以其与原点O之间的沿路网的最短距离和方向表示其路网坐标 |
| Point(L(y)) | 路网坐标为 L(y) 的点集 |
| FPoint(fk) | 位于分叉点 fk 搜索方向各分支上的聚类元素集合 |
| RPoint(fk, rq) = {xj | rq∈R(fk), xj∈FPoint(fk)} | 位于分叉点 fk 搜索方向 rq 分支上的聚类元素集合 |
| TopFork(y1, y2) | 元素 y1 到 y2 路径上的第一个分叉点 |
| 簇中心 ci 所在分支与聚类元素 xj 所在分支的公共分叉点 | |
| uij | 聚类元素 xj 隶属于簇中心 ci 的隶属度 |
| d(xj, ci) | 以聚类元素 xj 与簇中心点 ci 之间的路网坐标差值计算的有向可达距离 |
| P(y1, y2) | 元素y1与y2之间沿路网的最短路径 |
| cit | 第 t 代第 i 个簇中心 |
| cit' | 第 t 代第 i 个簇中心迭代修正过程中的簇中心 |
表2 簇中心位置结果Tab. 2 Cluster center location results |
| 实验 | 簇中心 总数/个 | 位于路网上的簇中心数/个 | 位于路网上的簇中心数占比/% | 路网周围簇中心数/个 | 路网周围簇中心数占比/% | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FCM-RD | 欧氏FCM | Mean Shift | FCM-RD | 欧氏FCM | Mean Shift | FCM-RD | 欧氏FCM | Mean Shift | FCM-RD | 欧氏FCM | Mean Shift | |||||
| G1 | 120 | 120 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.0 | |||
| G2 | 120 | 120 | 0 | 0 | 100 | 0 | 0 | 0 | 0 | 30 | 0 | 0 | 25.0 | |||
| G3 | 120 | 120 | 0 | 0 | 100 | 0 | 0 | 0 | 30 | 30 | 0 | 25 | 25.0 | |||
| G4 | 60 | 60 | 0 | 0 | 100 | 0 | 0 | 0 | 24 | 0 | 0 | 40 | 0.0 | |||
| G5 | 90 | 90 | 0 | 0 | 100 | 0 | 0 | 0 | 11 | 0 | 0 | 12 | 0.0 | |||
| G6 | 150 | 150 | 0 | 0 | 100 | 0 | 0 | 0 | 12 | 60 | 0 | 8 | 40.0 | |||
| G7 | 180 | 180 | 0 | 0 | 100 | 0 | 0 | 0 | 31 | 30 | 0 | 17 | 16.7 | |||
| G8 | 120 | 120 | 0 | 0 | 100 | 0 | 0 | 0 | 30 | 60 | 0 | 25 | 50.0 | |||
注:位于路网周围是指在1:60 000 m的比例尺下,簇中心与路网接近重合的场景;加粗数据表示对比项中的较优结果。 |
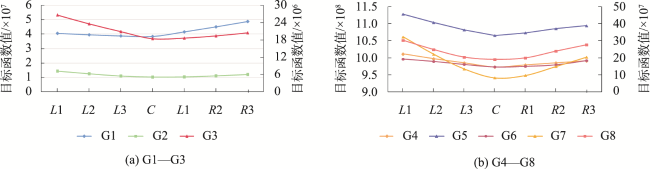
表3 实验结果性能指标分析Tab. 3 Performance analysis of experimental results |
| 实验 | 算法 | 均值/m | 最大值/m | 最小值/m | DB指数 | 轮廓系数 |
|---|---|---|---|---|---|---|
| G1 | FCM-RD | 974.67 | 2 230.55 | 473.48 | 0.44 | 0.76 |
| 欧氏FCM | 1 107.67 | 3 363.04 | 116.71 | 0.47 | 0.76 | |
| Mean Shift | 1 159.41 | 3 317.53 | 355.77 | 0.70 | 0.82 | |
| 层次聚类 | 未生成簇中心 | 0.76 | ||||
| G2 | FCM-RD | 1 805.31 | 3 849.25 | 289.43 | 0.66 | 0.70 |
| 欧氏FCM | 2 123.84 | 6 295.07 | 45.94 | 0.87 | 0.66 | |
| Mean Shift | 2 128.23 | 5 563.67 | 57.74 | 1.11 | 0.73 | |
| 层次聚类 | 未生成簇中心 | 0.70 | ||||
| G3 | FCM-RD | 3 220.10 | 7 273.50 | 131.72 | 1.60 | 0.59 |
| 欧氏FCM | 3 327.96 | 8 955.90 | 152.05 | 0.70 | 0.58 | |
| Mean Shift | 3 490.11 | 9 794.47 | 50.97 | 1.42 | 0.59 | |
| 层次聚类 | 未生成簇中心 | 0.58 | ||||
| G4 | FCM-RD | 4 892.31 | 9 808.73 | 534.47 | 2.32 | 0.39 |
| 欧氏FCM | 5 070.98 | 11 102.91 | 93.41 | 1.24 | 0.37 | |
| Mean Shift | 7 605.33 | 15 304.62 | 64.80 | 3.29 | 0.23 | |
| 层次聚类 | 未生成簇中心 | 0.37 | ||||
| G5 | FCM-RD | 3 984.76 | 9 808.73 | 92.30 | 1.12 | 0.52 |
| 欧氏FCM | 4 112.86 | 10 169.18 | 175.67 | 0.86 | 0.49 | |
| Mean Shift | 4 174.03 | 9 821.42 | 83.40 | 0.93 | 0.53 | |
| 层次聚类 | 未生成簇中心 | 0.53 | ||||
| G6 | FCM-RD | 2 744.64 | 6 319.25 | 269.05 | 1.31 | 0.64 |
| 欧氏FCM | 2 883.95 | 9 798.69 | 35.25 | 0.83 | 0.62 | |
| Mean Shift | 2 904.36 | 6 987.29 | 355.14 | 1.49 | 0.64 | |
| 层次聚类 | 未生成簇中心 | 0.63 | ||||
| G7 | FCM-RD | 974.67 | 2 230.55 | 473.48 | 0.44 | 0.76 |
| 欧氏FCM | 1 107.67 | 3 363.04 | 116.71 | 0.47 | 0.76 | |
| Mean Shift | 1 159.41 | 3 317.53 | 355.77 | 0.70 | 0.82 | |
| 层次聚类 | 未生成簇中心 | 0.76 | ||||
| G8 | FCM-RD | 2 472.79 | 5 453.20 | 365.17 | 1.47 | 0.67 |
| 欧氏FCM | 2 539.43 | 7 161.58 | 24.80 | 0.93 | 0.67 | |
| Mean Shift | 2 536.71 | 6 353.28 | 95.46 | 1.55 | 0.68 | |
| 层次聚类 | 未生成簇中心 | 0.68 | ||||
注:加粗数据表示对比项中的较优结果。 |
| [1] |
王鹏洲, 赵志远, 姚伟, 等. 基于地理流空间的巡游车与网约车人群出行模式研究[J]. 地球信息科学学报, 2023, 25(4):726-740.
[
|
| [2] |
王浩成, 向隆刚, 关雪峰, 等. 基于出租车上下客数据流与分布式多阶段网格聚类的城市热点区域实时探测方法[J]. 地球信息科学学报, 2023, 25(7):1514-1530..
[
|
| [3] |
张亚, 刘纪平, 周亮, 等. 基于DBSCAN算法的北京市顺丰快递服务设施集群识别与空间特征分析[J]. 地球信息科学学报, 2020, 22(8):1630-1641.
[
|
| [4] |
|
| [5] |
Pooja,
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}