
结合谱聚类和粒子群改进K-means聚类的机载LiDAR点云单木分割方法
|
钱禹航(1997— ),男,江苏泰州人,硕士,主要研究LiDAR点云数据处理、单木提取。E-mail: 1207627706@qq.com |
Editor: 蒋树芳
收稿日期: 2024-04-29
修回日期: 2024-06-12
网络出版日期: 2024-09-10
基金资助
国家自然科学基金面上项目(41871379)
辽宁省兴辽英才计划项目(XLYC2007026)
辽宁省应用基础研究计划项目(2022JH2/101300273)
Improved K-means Clustering Method Based on Spectral Clustering and Particle Swarm Optimization for Individual Tree Segmentation of Airborne LiDAR Point Clouds
Received date: 2024-04-29
Revised date: 2024-06-12
Online published: 2024-09-10
Supported by
National Natural Science Foundation of China(41871379)
Liaoning Revitalization Talents Program(XLYC2007026)
Fundamental Applied Research Foundation of Liaoning Province(2022JH2/101300273)
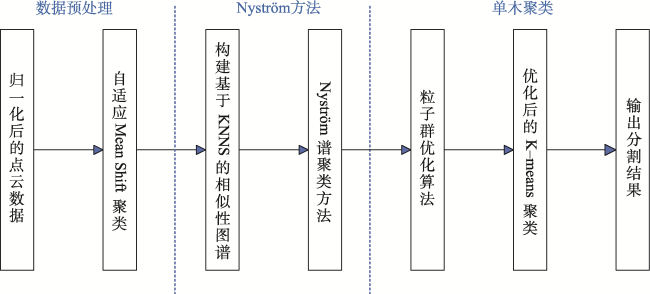
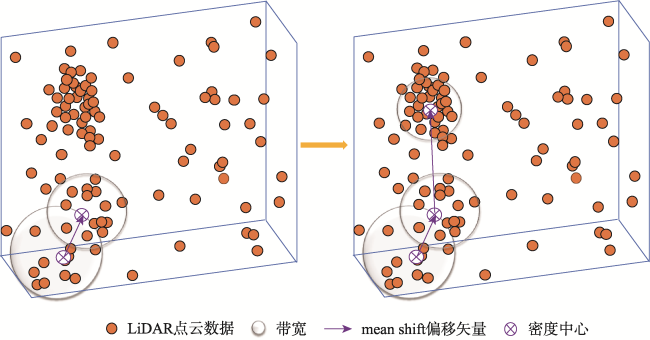
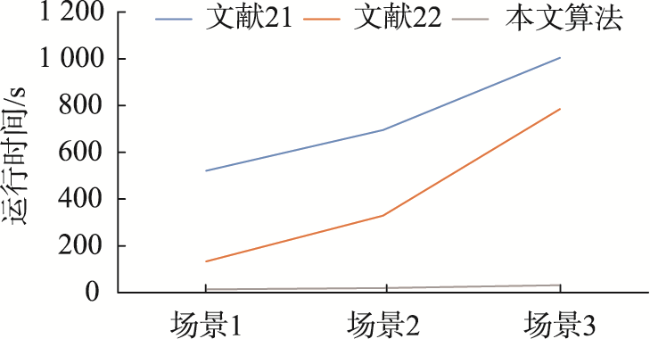
单木分割的精准度对林木资源的调查有重要意义。但是,传统的单木分割算法在处理大规模点云数据时存在临近树木易混淆、算法运算效率低等问题,针对上述问题,本文提出改进谱聚类和粒子群改进K-means聚类的单木分割算法。首先,通过Mean Shift算法对点云数据进行体素化,在该过程中采用自适应带宽和高斯核函数来计算体素间的相似度,以构建出反映体素特性的高斯相似图。然后应用Nyström方法处理高斯相似图,采用K最近邻搜索采样,以选取代表性样本,降低谱聚类在处理大规模数据时的计算负担,同时保持数据的核心特性。通过Nyström近似,得到相似图的近似特征向量,实现从高维空间到低维特征空间的有效映射。最后引入粒子群算法对K-means聚类进行优化。该优化先随机初始化一群粒子,每个粒子代表一组潜在的聚类中心,在每一次迭代中,粒子根据个体历史最佳位置和群体历史最佳位置更新其速度和位置,并调整聚类中心以最小化内部聚类距离。这种策略能够平衡全局搜索与局部搜索,避免陷入局部最优。本文选取NEWFOR公开的点云数据进行实验。实验结果表明,本文算法获得的分割结果相较对比算法准确率提高5.3%,处理效率提升23倍。

关键词: 机载LiDAR点云; 单木分割; 体素化; Mean Shift算法; Nyström谱聚类算法; 粒子群算法
钱禹航 , 王竞雪 , 郑雪涛 . 结合谱聚类和粒子群改进K-means聚类的机载LiDAR点云单木分割方法[J]. 地球信息科学学报, 2024 , 26(9) : 2177 -2191 . DOI: 10.12082/dqxxkx.2024.240243
The precision of individual tree segmentation is important for survey of forest resources. However, traditional individual tree segmentation algorithms suffer from issues such as near tree confusion and low computational efficiency when processing large-scale point cloud data. To address these issues, this paper introduces an improved K-means clustering method that combines spectral clustering and particle swarm optimization for individual tree segmentation of airborne LiDAR point clouds. The proposed method is designed to overcome the limitations of conventional methods by increasing the accuracy of tree segmentation and optimizing the processing of large and complex point cloud data. By combining advanced techniques in spectral clustering and particle swarm optimization, the proposed method significantly improves the precision and efficiency of individual tree segmentation. Firstly, the voxelization of the point cloud data is performed using the Mean Shift algorithm, where the adaptive bandwidth and Gaussian kernel function compute the similarity between voxels, resulting a Gaussian similarity graph reflecting the properties of voxels. This graph not only encapsulates the space structure of the forest but also improves the accuracy of the subsequent data analysis and processing. After voxelization, the Nyström method is applied to efficiently manage the Gaussian similarity graph. This method uses K-nearest neighbor search to select representative samples, effectively reducing the computational burden associated with spectral clustering when dealing with large-scale datasets. By selecting representative samples, the algorithm ensures that the main features of the data are retained, facilitating a more manageable and accurate clustering process. This method optimizes the processing of large amounts of point cloud data by balancing computational efficiency with the requirement to maintain data integrity and accuracy, thus providing a robust foundation for accurate tree segmentation. Using the Nyström approximation, approximate eigenvectors of the similarity graph are obtained, facilitating an effective mapping from the high-dimensional space to a low-dimensional feature space. Finally, the particle swarm optimization algorithm is introduced to enhance the K-means clustering process. This optimization algorithm first randomly initializes a set of particles, each representing a set of potential cluster centers. In each iteration, the particles update their clustering speed and position based on the best historical position of the individual and the best historical position of the group, adjusting the clustering centers to minimize the internal cluster distance. In this paper, publicly available point cloud data from NEWFOR is selected for experiments. The experimental results show that the segmentation results obtained by the proposed algorithm are 5.3% higher in accuracy and 23 times more efficient than the comparison algorithm.
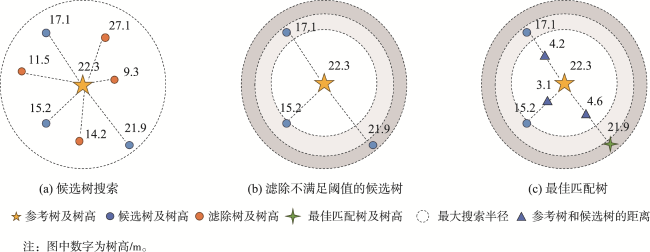
表2 不同树高对应的邻域标准Tab. 2 Neighborhood criteria corresponding to different tree heights (m) |
| 标准 | 分割出的树高Hseg | 树高差 | 树间距 |
|---|---|---|---|
| 1 | Hseg> 25 | < 4 | < 5 |
| 2 | 15 <Hseg≤ 25 | < 4 | < 5 |
| 3 | 10 <Hseg≤ 15 | < 3 | < 4 |
| 4 | Hseg≤ 10 | < 3 | < 3 |
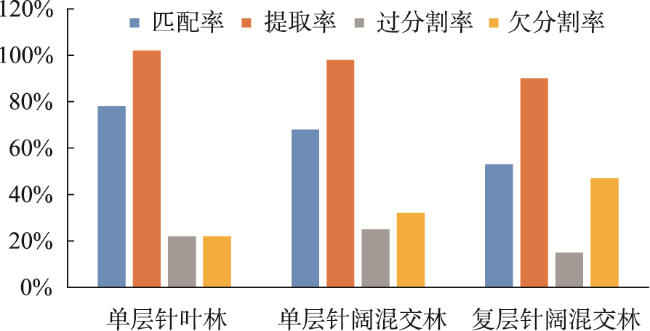
图6 3种方法在低密度林区的分割结果Fig. 6 Segmentation results of three methods in low density forest area |
图7 3种方法在中密度林区的分割结果Fig. 7 Segmentation results of three methods in medium density forest area |
图8 3种方法在高密度林区的分割结果Fig. 8 Segmentation results of three methods in high density forest area |
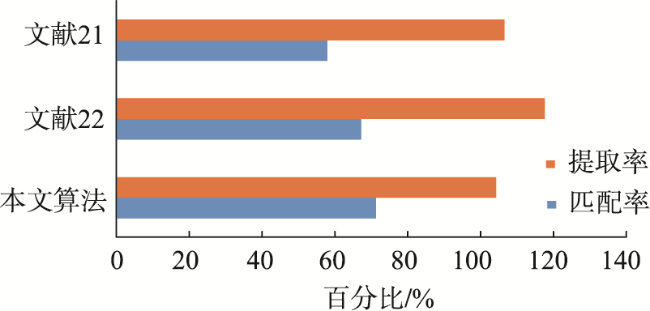
表3 样地精度对比Tab. 3 Accuracy comparison of different areas (%) |
| 样地 | 方法 | 匹配率 | 提取率 | 过分割率 | 欠分割率 |
|---|---|---|---|---|---|
| 低密度样地 | 文献[21] | 78 | 104 | 34 | 22 |
| 文献[22] | 80 | 105 | 34 | 20 | |
| 本文算法 | 79 | 102 | 33 | 21 | |
| 中密度样地 | 文献[21] | 66 | 99 | 24 | 34 |
| 文献[22] | 69 | 108 | 34 | 31 | |
| 本文算法 | 72 | 103 | 31 | 28 | |
| 高密度样地 | 文献[21] | 41 | 107 | 31 | 59 |
| 文献[22] | 52 | 118 | 37 | 48 | |
| 本文算法 | 63 | 104 | 37 | 37 |
| [1] |
|
| [2] |
林怡, 曹宇杰, 程效军. 基于树冠体素特征的森林机载-地基激光点云无控配准[J]. 同济大学学报(自然科学版), 2023, 51(7):994-1001,970.
[
|
| [3] |
王濮, 邢艳秋, 王成, 等. 一种基于图割的机载LiDAR单木识别方法[J]. 中国科学院大学学报, 2019, 36(3):385-391.
[
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
甄贞, 李响, 修思玉. 基于标记控制区域生长法的单木树冠提取[J]. 东北林业大学学报, 2016, 44(10):22-29.
[
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
张海清, 李向新, 王成, 等. 结合DSM的机载LiDAR单木树高提取研究[J]. 地球信息科学学报, 2021, 23(10):1873-1881.
[
|
| [26] |
|
| [27] |
|
| [28] |
|
/
| 〈 |
|
〉 |





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}