
基于改进邻域聚合的路网图嵌入匹配方法
|
杨 铭(1996— ),男,黑龙江五常人,硕士生,主要从事地理信息工程、计算机视觉研究。E-mail: 218527004@fzu.edu.cn |
Copy editor: 蒋树芳 , 黄光玉
收稿日期: 2024-01-04
修回日期: 2024-02-13
网络出版日期: 2024-10-09
基金资助
国家自然科学基金项目(42130112)
国家自然科学基金项目(42371479)
国家自然科学基金项目(41901335)
智慧地球重点实验室基金资助项目(KF2023ZD04-02)
A Method of Road Network Matching Using Graph Embedding via Improved Neighbor Aggregations
Received date: 2024-01-04
Revised date: 2024-02-13
Online published: 2024-10-09
Supported by
National Natural Science Foundation of China(42130112)
National Natural Science Foundation of China(42371479)
National Natural Science Foundation of China(41901335)
Key Laboratory of Smart Earth(KF2023ZD04-02)
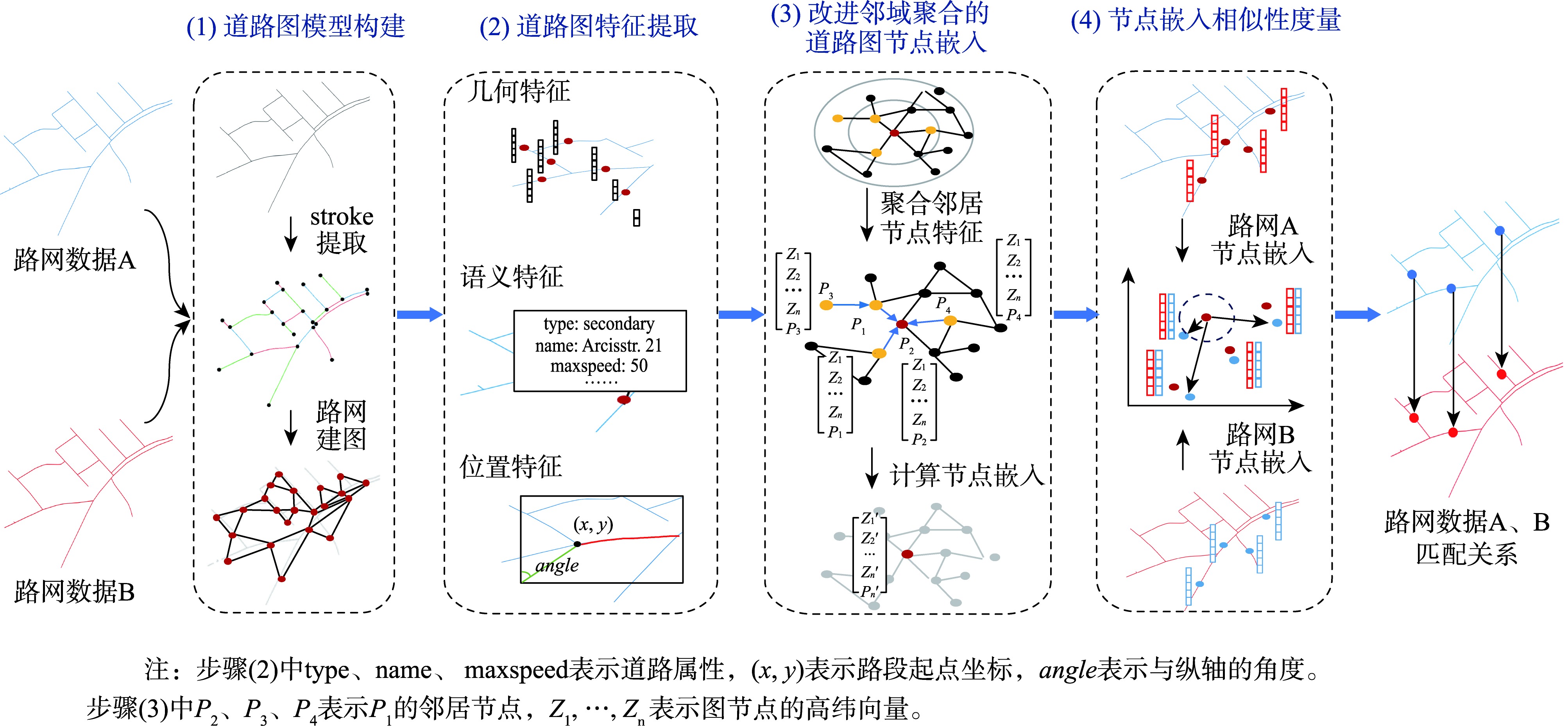
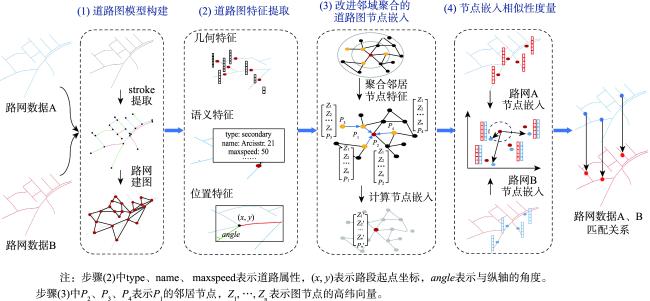
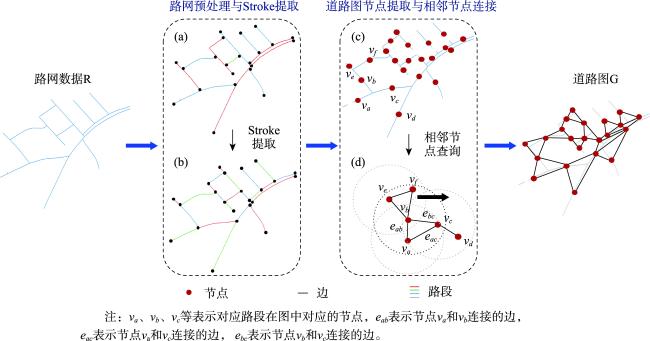
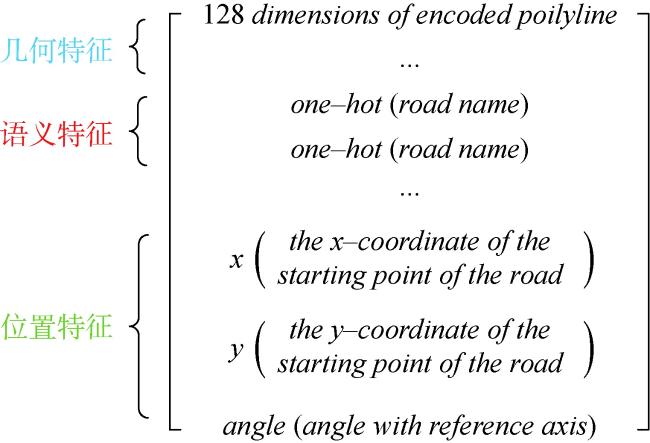
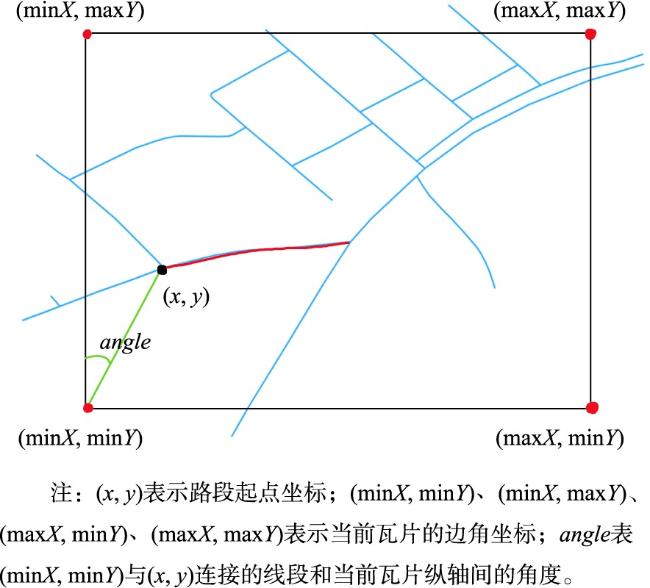
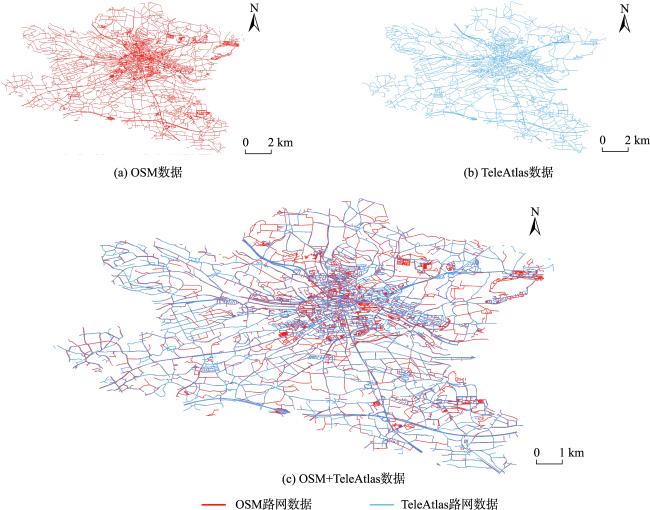
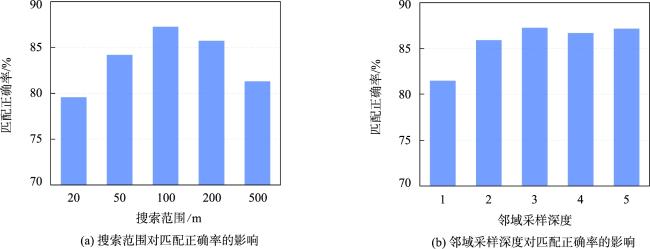
道路网作为一种重要的交通基础设施,路网数据的及时更新对交通管理、应急救援和城市规划等领域有重要应用意义。通过路网匹配来确定不同来源的路网数据中要素间的对应关系,既是实现路网更新的重要技术途径,也为众源路网数据质量评估等任务提供技术支撑,因而备受地理信息领域学者的关注。传统的路网匹配方法主要通过路网数据的几何和拓扑属性来度量路网结构的相似性,以此确定路网要素的匹配关系。但人工设计的特征和阈值易受专家经验局限,使其在复杂路网结构下性能下降。近年来,基于图神经网络的路网数据建模成为研究热点,已在多个路网建模任务中取得优异性能。但现有方法多采用在图拓扑结构上直接进行邻域聚合的方式,学习路网结构的嵌入表示,未在这一关键步骤中考虑路网要素的空间关系,没能充分利用图神经网络的表示学习能力。为此,本研究面向路网匹配任务,采用空间显式建模的思想,提出一种基于改进的邻域聚合图嵌入学习方法。首先,构建路网数据的道路图模型并提取几何、语义和位置特征。然后,基于GraphSAGE框架,提出空间、分类和混合3种邻域聚合算子,在邻域聚合操作中引入路网要素空间关系、属性类型的计算。最后,利用图节点嵌入的相似度确定路网要素的匹配关系。为验证本文方法的有效性,利用真实路网数据开展了充分实验,本文方法在实验区数据上的各项指标取得最优表现,比基线图神经网络方法的匹配正确率提升11%以上、召回率提升6.8%以上。并对路网图嵌入特征进行分析,从图嵌入结构和嵌入路网结构两方面,探讨了改进邻域聚合对图嵌入表示能力的作用,为进一步提升图神经网络路网建模提供了新视角。
杨铭 , 杨剑 , 侯洋 , 方立 , 张猛 , 张变英 , 张静茹 . 基于改进邻域聚合的路网图嵌入匹配方法[J]. 地球信息科学学报, 2024 , 26(10) : 2335 -2351 . DOI: 10.12082/dqxxkx.2024.240005
As an important transportation infrastructure, the timely updating of road network data is of great significance in the fields of traffic management, emergency response, and urban planning. Road network matching that determines the correspondence between the features of road network data from different sources serves this purpose. It also provides technical support for tasks such as the quality assessment of crowdsourced road network data, which has attracted a lot of attention in the field of geographic information. However, traditional road network matching methods mainly measure the similarity of road network structure through the geometric and topological attributes of road network data to determine the matching relationship of road network elements. Such methods with manually designed features and thresholds are easily limited by experts' experience, which degrades their performance under complex road network structures. In recent years, road network data modeling based on graph neural networks has become a research hotspot and has achieved excellent performance in several road network modeling tasks. However, most of the existing methods use direct neighborhood aggregation on the graph topology to learn the embedded representation of the road network structure, without considering the spatial relationship of road network features in this key step, and failing to make full use of the representation learning capability of graph neural networks. For this reason, this study proposes an improved neighborhood aggregation that performs a spatially explicit graph-based embedding learning method for road network matching. First, a road graph model of the road network data is constructed, and geometric, semantic, and location features are extracted. Then, based on the GraphSAGE framework, three kinds of neighborhood aggregation operators (i.e., spatial, classified, and hybrid) are proposed, and the computation of spatial relationships and attribute types of road network features is introduced in the neighborhood aggregation operations. Finally, the similarity of graph node embedding is utilized to determine the matching relationship of road network features. To verify the effectiveness of the proposed method, extensive experiments are carried out using real-world road network data. The proposed method achieves the optimal performance in all metrics on the test data of the study region, which improves the matching correctness rate by more than 11% and the recall rate by more than 6.8% compared to the baseline graph neural network method. Furthermore, the road network graph embedding features are analyzed from the aspects of graph embedding structure and embedded road network structure, which helps explore the role of improved neighborhood aggregation on the graph embedding representation capability and provides a new perspective for further improving the graph neural network road network modeling.
表1 基于混合聚合方法(GS+SP)的路网匹配混淆矩阵Tab. 1 Confusion matrix for road network matching based on the hybrid aggregation method (GS+SP) |
| 实际匹配道路 | 实际未匹配道路 | |
|---|---|---|
| 预测匹配道路 | 2 928(58.28) | 426(8.48) |
| 预测未匹配道路 | 542(10.78) | 1 128(22.46) |
注: 括号外数字是符合行标题和列标题的结果数目/个,括号内是这个数字在全部结果中对应的占比/%。 |
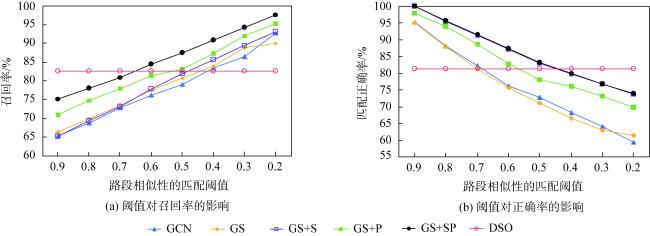
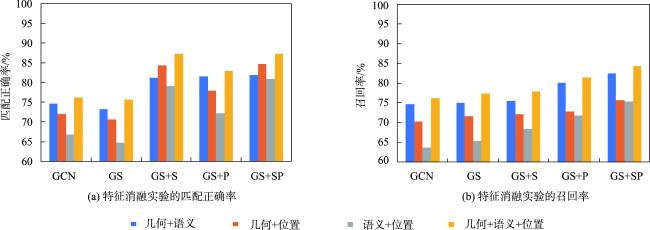
表2 本文路网嵌入匹配算法与基线算法的性能比较Tab. 2 Performance comparison between the proposed methods and the baseline methods (%) |
| 指标 | DSO | GCN | GS | GS+S | GS+P | GS+SP |
|---|---|---|---|---|---|---|
| 匹配正确率 | 81.25 | 76.21 | 75.66 | 87.21 | 82.87 | 87.27 |
| 召回率 | 82.60 | 76.24 | 77.51 | 77.87 | 81.46 | 84.37 |
| 匹配成功率 | 73.87 | 68.21 | 69.31 | 69.67 | 72.89 | 75.26 |
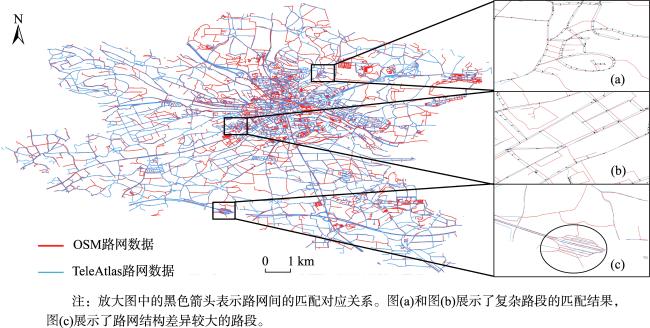
表3 本文路网嵌入匹配算法与基线算法在典型路段下的路网匹配结果比较Tab. 3 Comparison of the road network matching results between the proposed embedding-based road network matching algorithms and the baseline algorithms on the typical road segments |
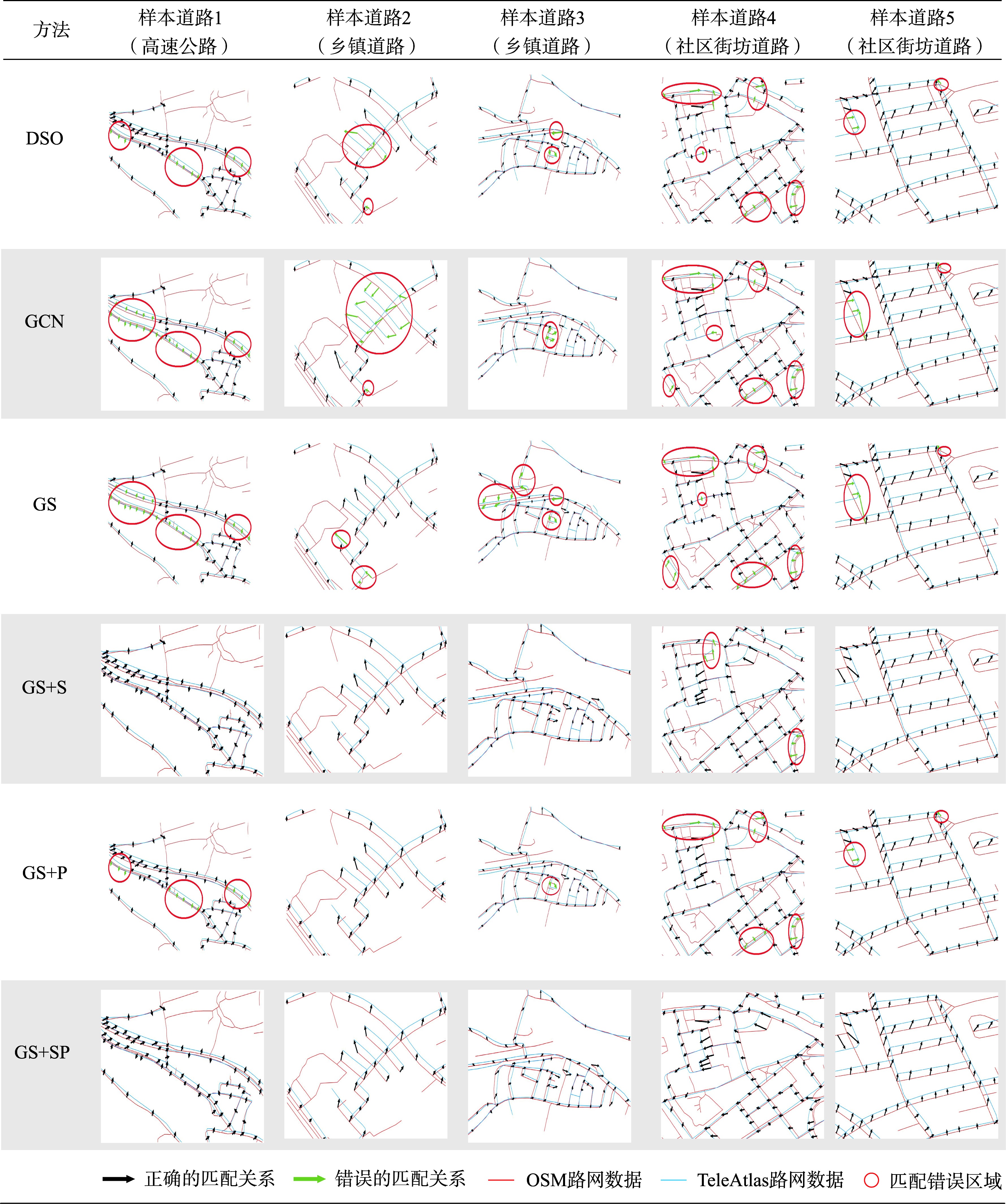 |
表4 本文方法及图神经网络基线方法的典型路网结构嵌入比较Tab. 4 Comparison of the typical road network structure embeddings between the proposed methods and the baseline methods using graph neural network |
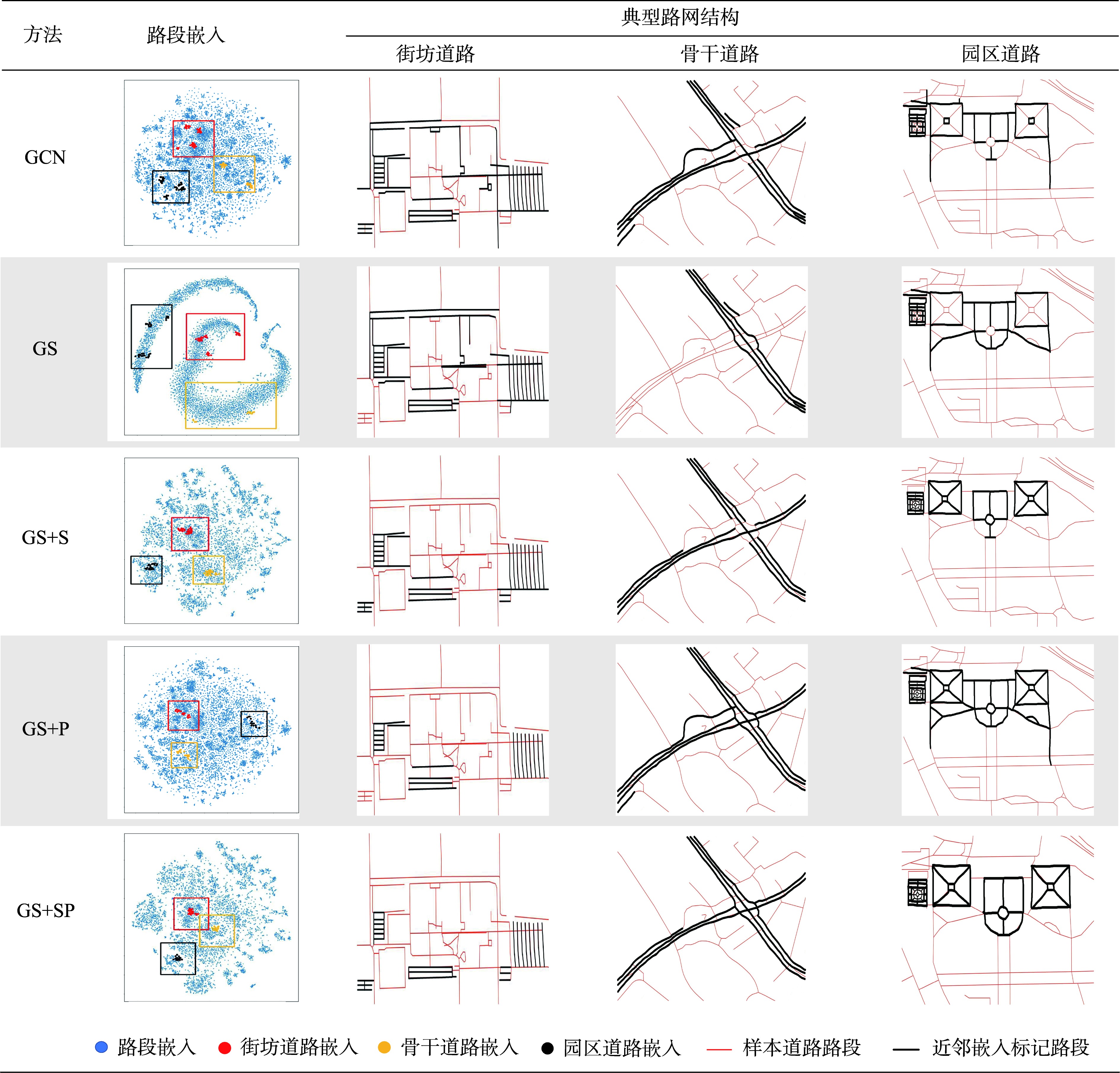 |
注:在嵌入可视化中,通过K近邻方法检索典型路网结构的路段嵌入点(街坊道路、骨干道路、园区道路分别用红、黄、黑色高亮显示,并用相应颜色的线框表示该类路段嵌入分布范围)。在路网地图中,检索结果在原始路网数据(红色线段)上进行高亮标记(黑色线段)。 |
表5 不同方法计算的路网嵌入的路网结构表示能力比较Tab. 5 Comparison of the structural expressive power of road network embeddings computed using different methods |
| 路网嵌入 | 路段嵌入降维 分布结构 | 模式道路结构表示能力 | ||
|---|---|---|---|---|
| 街坊道路 | 骨干道路 | 园区道路 | ||
| GCN | 多中心聚集,局部聚集性强,簇集间隔小 | 聚簇分散 表示不完整、混杂 | 聚簇分散 表示不完整、混杂 | 聚簇分散 表示不完整、混杂 |
| GS | 条带均匀分布 | 聚簇分散 表示不完整、混杂 | 聚簇分散 表示不完整、混杂 | 聚簇分散 表示不完整、混杂 |
| GS+S | 多中心聚集,簇集间隔大 | 聚簇集中 表示较完整、局部混杂 | 聚簇集中 表示局部不完整 | 聚簇集中 表示局部不完整 |
| GS+P | 多中心聚集,局部聚集性强,簇集间隔小 | 聚簇较集中 表示局部不完整、局部混杂 | 聚簇较集中 表示完整、局部混杂 | 聚簇较集中 表示完整、局部混杂 |
| GS+SP | 多中心聚集,簇集间隔大 | 聚簇集中 表示完整 | 聚簇集中 表示局部不完整 | 聚簇集中 表示完整 |
注:颜色越深意味着路网嵌入的结构表示能力越强。 |
| [1] |
王玉竹, 闫浩文, 禄小敏. 面向路网匹配的层次化语义相似性度量模型[J]. 地球信息科学学报, 2023, 25(4):714-725.
[
|
| [2] |
陈万鹏, 崔虎平. 基于相似性度量的城市路网实体匹配算法[J]. 测绘与空间地理信息, 2018, 41(12):39-42,46.
[
|
| [3] |
刘闯, 钱海忠, 王骁, 等. 顾及上下级空间关系相似性的道路网联动匹配方法[J]. 测绘学报, 2016, 45(11):1371-1383.
[
|
| [4] |
吴冰娇, 王中辉, 杨飞. 用于多尺度道路网匹配的语义相似性计算模型[J]. 测绘科学, 2022, 47(3):166-173.
[
|
| [5] |
赵云鹏, 孙群, 刘新贵, 等. 面向地理实体的语义相似性度量方法及其在道路匹配中的应用[J]. 武汉大学学报(信息科学版), 2020, 45(5):728-735.
[
|
| [6] |
|
| [7] |
王昊, 翟仁健, 周明辉, 等. 一种基于复杂网络的道路匹配方法[J]. 测绘科学技术学报, 2016, 33(1):88-93.
[
|
| [8] |
张猛, 吴巧丽, 钱海忠. 一种适用于多源道路网自动匹配的通用算法[J]. 测绘科学技术学报, 2018, 35(1):82-86.
[
|
| [9] |
|
| [10] |
秦育罗, 宋伟东, 张在岩, 等. 顾及几何特征和拓扑连续性的道路网匹配方法[J]. 测绘通报, 2021(8):55-60.
[
|
| [11] |
|
| [12] |
黄智深, 钱海忠, 王骁, 等. 基于降维技术的面状居民地匹配方法[J]. 测绘科学技术学报, 2012, 29(1):75-78.
[
|
| [13] |
杨东凯, 寇艳红, 吴今培, 等. 智能交通系统中的地图匹配定位方法[J]. 交通运输系统工程与信息, 2003, 3(3):38-43.
[
|
| [14] |
|
| [15] |
齐杰, 王中辉, 李驿言. 基于图卷积神经网络的道路网匹配[J]. 测绘通报, 2023(12):19-24,44.
[
|
| [16] |
艾廷华. 深度学习赋能地图制图的若干思考[J]. 测绘学报, 2021, 50(9):1170-1182.
[
|
| [17] |
王米琪, 艾廷华, 晏雄锋, 等. 图卷积网络模型识别道路正交网格模式[J]. 武汉大学学报(信息科学版), 2020, 45(12):1960-1969.
[
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
黄博华, 钟巍, 翟仁健, 等. 城市道路网匹配的层次化面域剖分模型[J]. 测绘学报, 2018, 47(11):1526-1536.
[
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
/
| 〈 |
|
〉 |
 弱
弱  中
中  强
强{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}