
融合风险特征和空间特征的城市暴雨级联事件风险评估模型构建
|
刘昭阁(1992— ),男,山东烟台人,博士,硕士生导师,助理教授,研究方向为应急管理大数据分析与社会治理智能化方法。E-mail: zhaogeliu@xmu.edu.cn |
Copy editor: 蒋树芳 , 黄光玉
收稿日期: 2024-05-14
修回日期: 2024-07-17
网络出版日期: 2024-10-09
基金资助
国家自然科学基金青年项目(72404232)
国家自然科学基金重大研究计划项目(91746207)
国家自然科学基金面上项目(71774043)
福建省自然科学基金项目(2023J05011)
Construction of a Risk Assessment Model for Urban Rainstorm Cascading Events Integrating Risk and Spatial Features
Received date: 2024-05-14
Revised date: 2024-07-17
Online published: 2024-10-09
Supported by
Young Scientists Fund of the National Natural Science Foundation of China(72404232)
Major Research Plan of the National Natural Science Foundation of China named Big data Driven Management and Decision-making Research(91746207)
General Program of the National Natural Science Foundation of China(71774043)
Natural Science Foundation of Fujian Province(2023J05011)
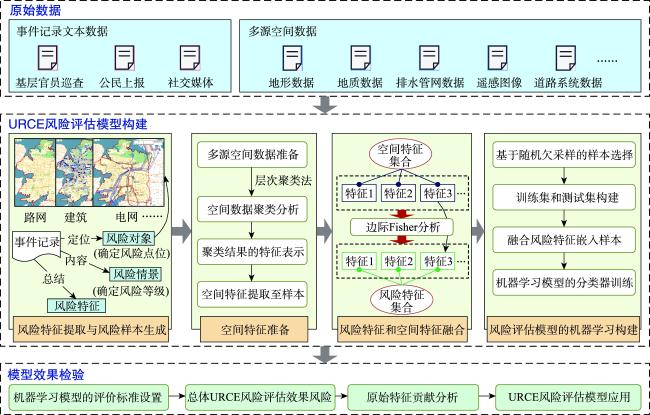
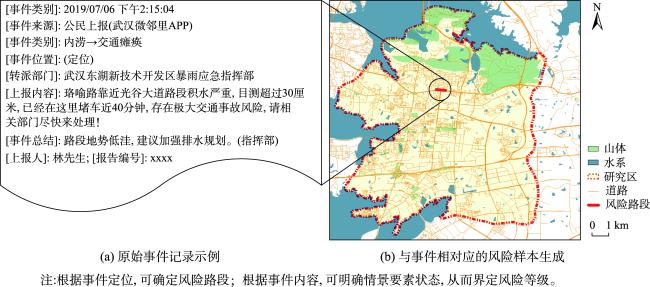
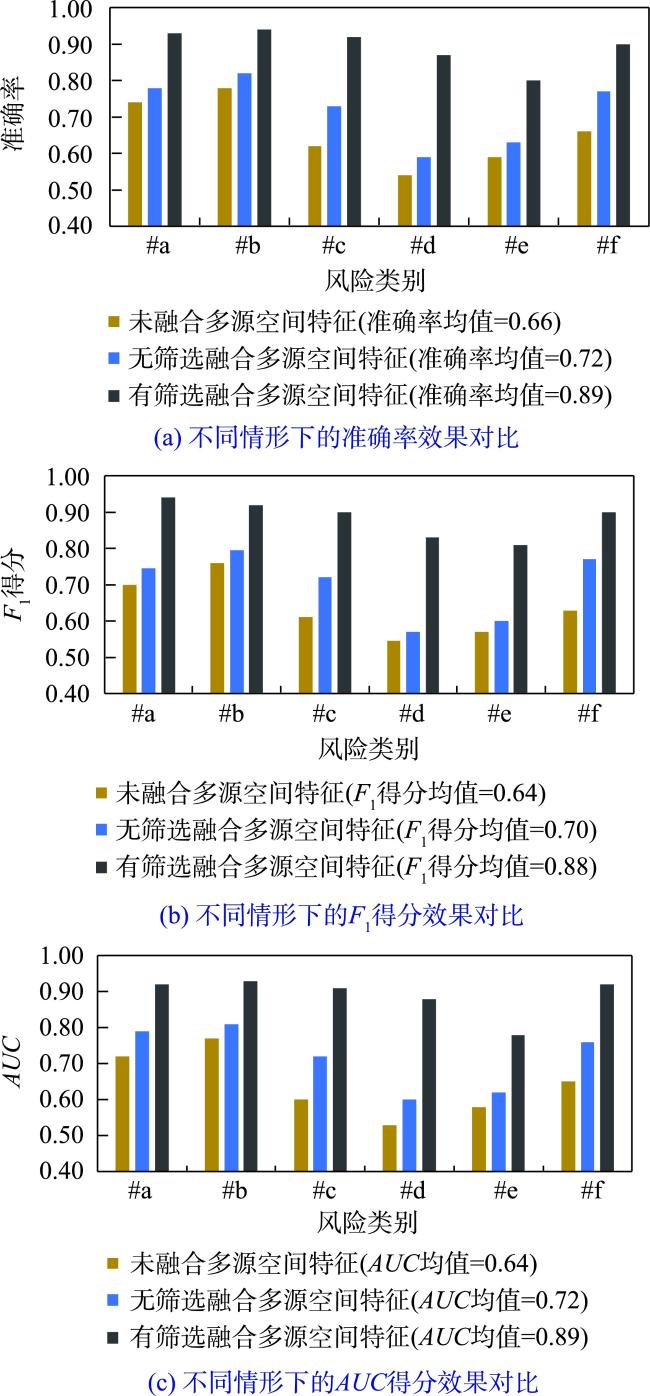
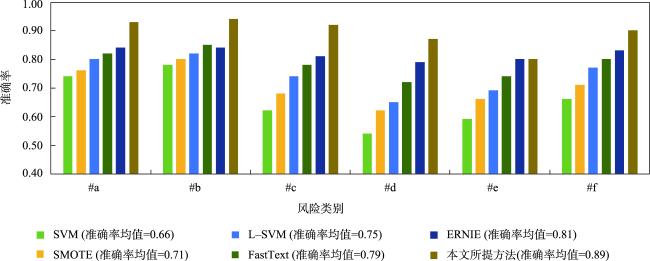
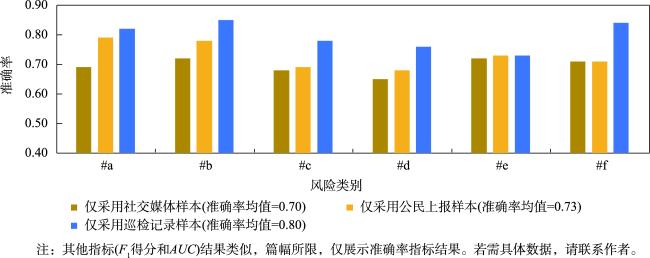
相较于城市暴雨致灾事件(如内涝、洪水、泥石流等),现有研究对小粒度、多样化暴雨级联事件(如房屋损毁、地铁淹没等)风险的特征构成及其客观评估关注较少,难以适应城市精准化管理目标;同时,暴雨级联事件的风险评估模型构建面临样本数据风险特征不完备带来的模型效果约束。针对上述问题,考虑空间特征和风险特征的空间关联性,提出了融合风险特征和空间特征的城市暴雨级联事件风险评估模型构建方法。首先,面向不同暴雨级联事件的风险情景,从暴雨基层官员巡检、公民上报和社交媒体发帖数据中提炼级联事件风险特征;其次,以原始风险样本的空间定位为衔接,利用改进的边际Fisher方法从多源空间数据中挖掘空间特征,补充风险特征的缺失;最后,基于机器学习方法建立风险特征与风险类别的关联关系,构建多类别暴雨级联事件的风险评估模型。中国湖北省武汉市的实验结果表明:所提方法能够通过多源空间特征挖掘解决风险评估模型构建的特征不完备问题,实现多样化暴雨级联事件风险评估模型的有效构建,总体准确率、 F1得分以及AUC分别提升了23%、24%以及25%;同时,针对小粒度承灾体开展多样化级联事件风险评估,有助于更加精准的城市暴雨风险管理。

刘昭阁 , 李向阳 , 朱晓寒 . 融合风险特征和空间特征的城市暴雨级联事件风险评估模型构建[J]. 地球信息科学学报, 2024 , 26(10) : 2394 -2406 . DOI: 10.12082/dqxxkx.2024.240270
Compared with urban rainstorm hazardous events (such as waterlogging, flood, debris flow, etc.), existing studies pay less attention to the feature composition and objective assessment of risks associated with small-scale and diversified rainstorm cascading events (such as house damage, subway inundation, etc.), making is difficult to meet the goals of refined city management. At the same time, constructing risk assessment models for rainstorm cascading events faces constraints due to incomplete risk features in sample data. To address these issues, this paper proposes a risk assessment model for urban rainstorm cascading events that integrates risk features and spatial features, considering the spatial correlation between them. Firstly, for the risk scenarios of different rainstorm cascading events, the risk features are extracted from data sources such as grassroots officials' inspection, citizen reporting, and social media posts. Secondly, using the spatial localization of the original risk samples as a connection, an improved marginal Fisher method is employed to mine spatial features from multi-source spatial data to supplement the missing risk features. Finally, using a machine learning approach, the relationship between risk features and risk categories is established, leading to the construction of a risk assessment model for multi-category rainstorm cascading events. Experimental results from Wuhan, Hubei Province, China, show that the proposed method effectively addresses the problem of incomplete features in the construction of risk feature models through multi-source spatial feature mining, enabling the construction of diversified rainstorm cascading event risk assessment models. The overall accuracy, F1-score and AUC increased by 23%, 24%, and 25%, respectively. Additionally, the complexity and diversity of spatial features highlighted the risks of subjective and arbitrary feature fusion, which can negatively affect the performance of machine learning model construction by adding irrelevant features. The proposed method mitigates this issue with an adaptive feature selection approach. Furthermore, grassroots officials’ inspection records contributed the most to the construction of urban rainstorm cascading event risk assessment models, followed by citizen-reported texts, and finally, social media data. Compared to traditional disaster event risk assessment methods, urban rainstorm cascading event risks have smaller risk granularity and involve more complex and diverse risk types and features. Traditional comprehensive evaluation models face challenges of subjectivity in manual evaluation, while traditional disaster loss curve methods encounter high experimental costs and data scarcity. The method proposed in this paper utilizes objective data to generate multidimensional risk features and establishes relationships between diverse risk levels, resulting in a machine learning-based risk prediction model that is more suitable for small-scale risk assessment scenarios.
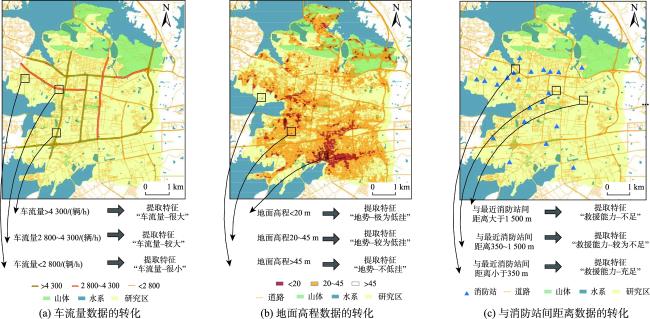
表1 空间特征示例Tab. 1 Examples of the spatial features |
| 空间特征类别 | 空间特征 | 主要数据来源 | 主要聚类结果 |
|---|---|---|---|
| 地形特征 | 地面高程/m | 谷歌地图等开放数据 | “高程低”、“高程中”、“高程高” |
| 地质特征 | 是否存在临近山体 | 城市规划部门 | “是”、“否” |
| 排水能力特征 | 排水管排水能力/(mm/s) | 城市水务部门 | “排水能力-强”、“排水能力-较差”、“排水能力-差” |
| 水系特征 | 是否存在临近水库 | 城市水务部门 | “是”、“否” |
| 道路特征 | 车流量/(辆/h) | 城市交通部门 | “车流量-很大”、“车流量-较大”、“车流量-很小” |
| 与最近消防站间距离 | 城市交通部门 | “救援能力-不足”、“救援能力-较为不足”、“救援能力-充足” | |
| 电网特征 | 电力设施类型 | 城市电力公司 | “变电站”、”输电线”、”发电站”等 |
| 建筑特征 | 建筑年龄/年 | 国土资源部门 | “建筑年龄-老旧”、“建筑年龄-较旧”、“建筑年龄-较新” |
| 人口热力特征 | 区域人口热力/(人/km2) | 城市电信部门 | “人口热力-很高”、“人口热力-较高”、“人口热力-较低” |
表2 风险样本分布Tab. 2 URCE risk sample distribution |
| URCE风险 | 符号 | 风险等级 | 样本数/个 |
|---|---|---|---|
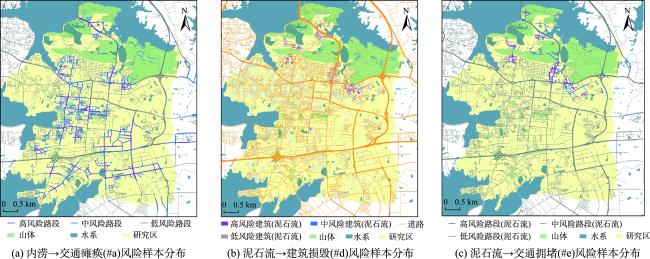
| 内涝→交通瘫痪 | #a | 高风险 | 965 |
| 中风险 | 1 953 | ||
| 低风险 | 999 | ||
| 内涝→电网损毁 | #b | 高风险 | 614 |
| 中风险 | 1 627 | ||
| 低风险 | 1 049 | ||
| 内涝→居民受困 | #c | 高风险 | 556 |
| 中风险 | 1 304 | ||
| 低风险 | 746 | ||
| 泥石流→建筑损毁 | #d | 高风险 | 162 |
| 中风险 | 350 | ||
| 低风险 | 161 | ||
| 泥石流→交通拥堵 | #e | 高风险 | 177 |
| 中风险 | 465 | ||
| 低风险 | 204 | ||
| 洪水→建筑损毁 | #f | 高风险 | 438 |
| 中风险 | 1 006 | ||
| 低风险 | 572 |
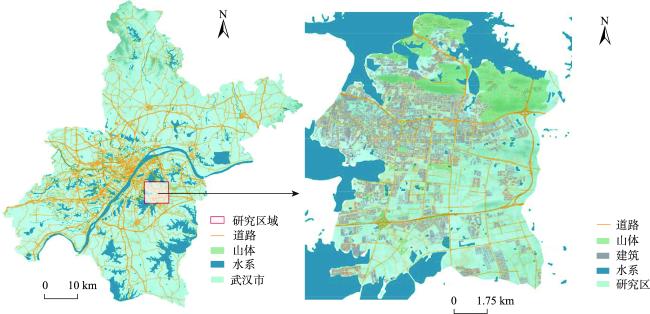
表3 多源空间数据集Tab. 3 Muti-surce spatial datasets |
| 数据名称 | 数据描述 | 数据类型 | 数据量 | 数据来源 |
|---|---|---|---|---|
| 地形数据 | 30 m数字高程模型(DEM) | 数值 | 904条 | 谷歌地图 |
| 地质数据 | 山体边界 | 矢量 | 297条 | 武汉市规划设计研究院 |
| 山体面积、土质等地质属性 | 矢量 | 297条 | 武汉市规划设计研究院 | |
| 排水管网数据 | 排水管网分布与管径 | 栅格 | 518 km2 | LocaSpaceViewer (LSV) |
| 遥感数据 | 湖泊分布与深度 | 栅格 | 518 km2 | 武汉东湖水务局 |
| 水库分布与深度 | 栅格 | 518 km2 | 武汉东湖水务局 | |
| 道路数据 | 道路交通流量以及与消防站间距离 | 矢量 | 652条 | 武汉东湖交通大队 |
| 电力数据 | 电力设施分布 | 矢量 | 348条 | 武汉东湖管委会 |
| 建筑数据 | 建筑分布和类型 | 矢量 | 482条 | 武汉东湖管委会 |
| 电信数据 | 人口密度分布 | 矢量 | 275条 | 武汉东湖管委会 |
注:表中数据的年份为2017—2021年,与风险样本保持一致。 |
| [1] |
|
| [2] |
刘海洋, 王录仓, 常跟应. 郑州“7·20” 特大暴雨灾害对中国铁路运网的冲击过程和机制[J]. 地理学报, 2024, 79(3):617-634.
[
|
| [3] |
卢小丽, 于海峰. 基于知识元的突发事件风险分析[J]. 中国管理科学, 2014, 22(8):108-114.
[
|
| [4] |
李锋, 王慧敏. 基于知识元的非常规突发洪水事件演化风险研究[J]. 系统工程理论与实践, 2016, 36(12):3255-3264.
[
|
| [5] |
王楠, 程维明, 张一驰, 等. 全国山洪灾害防治县房屋损毁风险评估及原因探究[J]. 地球信息科学学报, 2017, 19(12):1575-1583.
[
|
| [6] |
郭君, 赵思健, 黄崇福. 自然灾害概率风险的系统误差及校正研究[J]. 系统工程理论与实践, 2017, 37(2):523-534.
[
|
| [7] |
尹占娥, 许世远, 殷杰, 等. 基于小尺度的城市暴雨内涝灾害情景模拟与风险评估[J]. 地理学报, 2010, 65(5):553-562.
[
|
| [8] |
谢捷, 刘玮, 徐月顺, 等. 基于AHP-熵权法的西宁地区汛期暴雨灾害风险评估[J]. 自然灾害学报, 2022, 31(3):60-74.
[
|
| [9] |
|
| [10] |
苏凯, 程昌秀,
[
|
| [11] |
|
| [12] |
|
| [13] |
梁春阳, 林广发, 张明锋, 等. 社交媒体数据对反映台风灾害时空分布的有效性研究[J]. 地球信息科学学报, 2018, 20(6):807-816.
[
|
| [14] |
周超, 方秀琴, 吴小君, 等. 基于三种机器学习算法的山洪灾害风险评价[J]. 地球信息科学学报, 2019, 21(11):1679-1688.
[
|
| [15] |
程昌秀, 裴韬, 刘瑜, 等. 新时代自然灾害态势感知的实践与方法探索[J]. 地理学报, 2023, 78(3):548-557.
[
|
| [16] |
刘奕, 钱静, 范维澄. 走向精准:突发事件风险分析方法发展综述[J]. 中国安全科学学报, 2022, 32(9):1-10.
[
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
李长升, 汪诗烨, 李延铭, 等. 人工智能的逆向工程——反向智能研究综述[J]. 软件学报, 2023, 34(2):712-732.
[
|
| [23] |
包云, 高歌, 李亚群, 等. 基于监测数据挖掘的高铁气象灾害风险评估方法研究[J]. 灾害学, 2022, 37(2):44-48,53.
[
|
| [24] |
王启盛, 熊俊楠, 程维明, 等. 耦合统计方法、机器学习模型和聚类算法的滑坡易发性评价方法[J]. 地球信息科学学报, 2024, 26(3):620-637.
[
|
| [25] |
陈希, 张怡斐, 孙亚亚, 等. 面向突发事件的应急献血者聚类与分配方法研究[J]. 中国管理科学, 2022, 30(12):77-85.
[
|
| [26] |
|
| [27] |
|
| [28] |
邱凤婷, 过志峰, 张宗科, 等. 基于改进SVM分类法的SAR图像水体面积提取研究[J]. 地球信息科学学报, 2022, 24(5):940-948.
[
|
| [29] |
|
| [30] |
|
| [31] |
姚潇, 李可, 余乐安. 非平衡样本下基于生成对抗网络过抽样技术的公司债券违约风险预测研究[J]. 系统工程理论与实践, 2022, 42(10):2617-2634.
[
|
| [32] |
|
| [33] |
|
| [34] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}