
基于多模态特征提取与层级感知的遥感图像分割
|
张银胜(1975— ),男,江苏泰州人,教授,硕士生导师,主要从事遥感图像处理与深度学习研究。E-mail: yorkzhang@nuist.edu.cn |
Office editor: 黄光玉
收稿日期: 2024-09-02
修回日期: 2024-10-18
网络出版日期: 2024-11-28
基金资助
国家自然科学基金项目(62071240)
国家自然科学基金项目(62106111)
江苏省产教融合型一流课程(2022-133)
无锡学院教改研究课题(XYJG2023010)
无锡学院教改研究课题(XYJG2023011)
Remote Sensing Image Segmentation Based on Multi-modal Feature Extraction and Hierarchical Perception
Received date: 2024-09-02
Revised date: 2024-10-18
Online published: 2024-11-28
Supported by
National Natural Science Foundation of China(62071240)
National Natural Science Foundation of China(62106111)
The First-class Course of Industry-Education Integration in Jiangsu Province(2022-133)
The Teaching Reform Research Topic of Wuxi University(XYJG2023010)
The Teaching Reform Research Topic of Wuxi University(XYJG2023011)
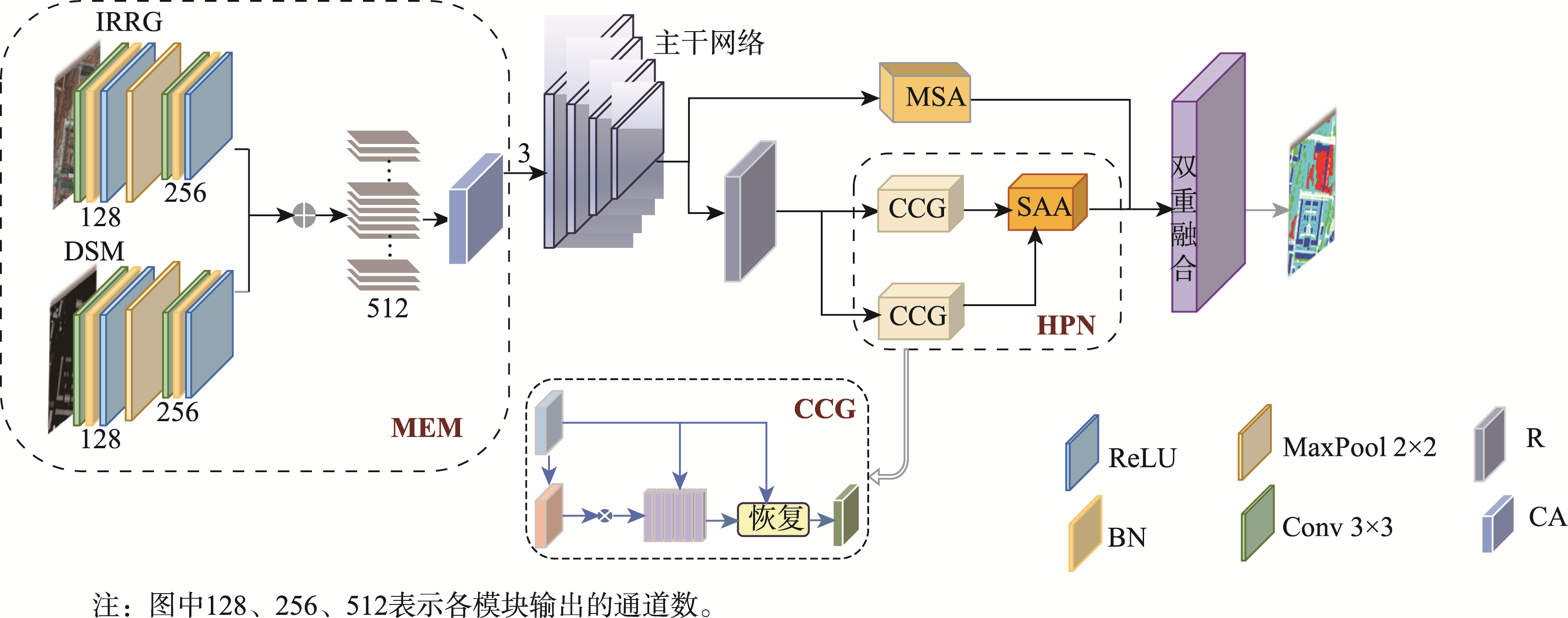
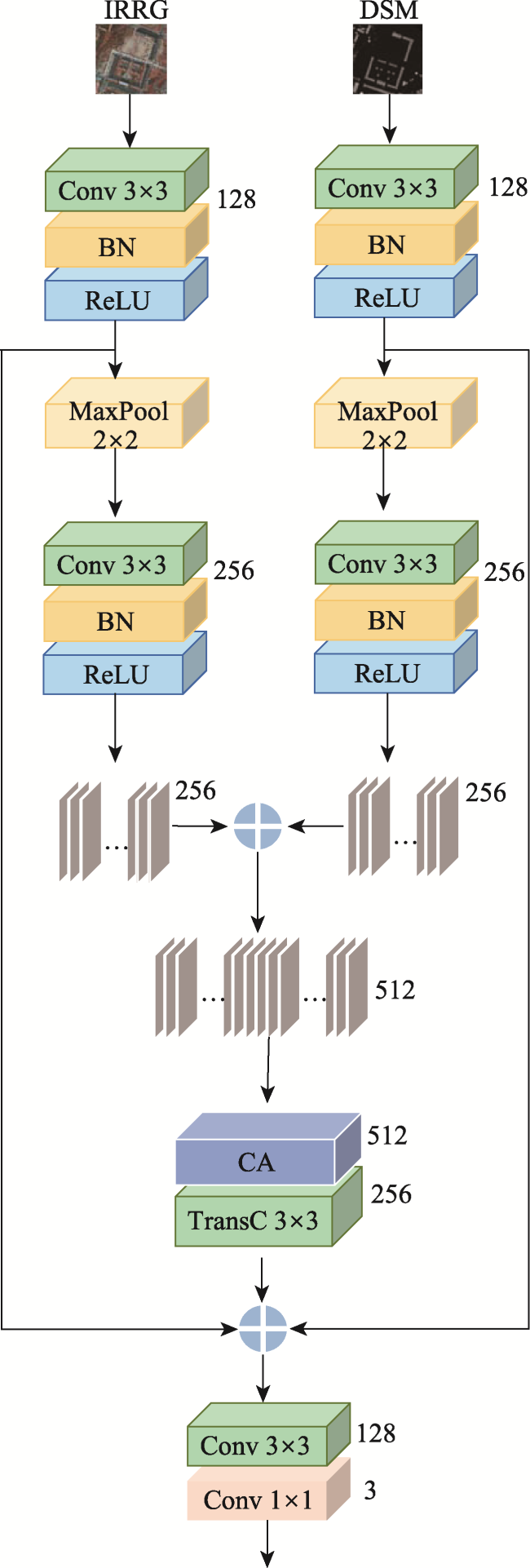
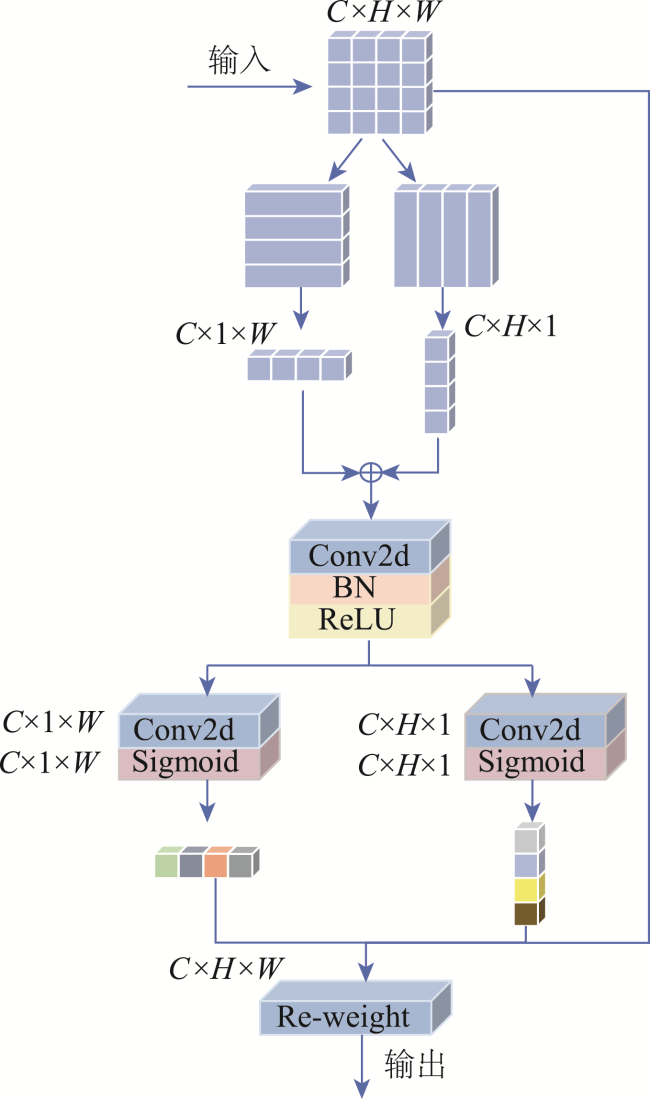
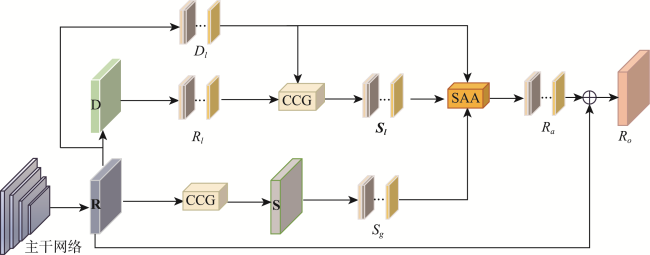
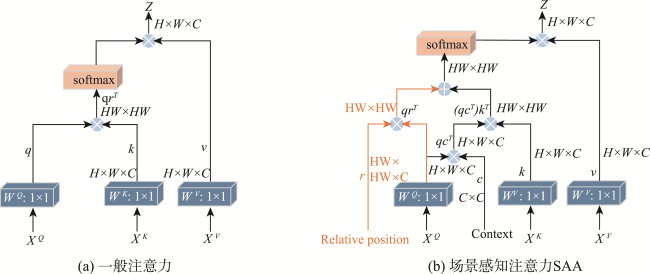
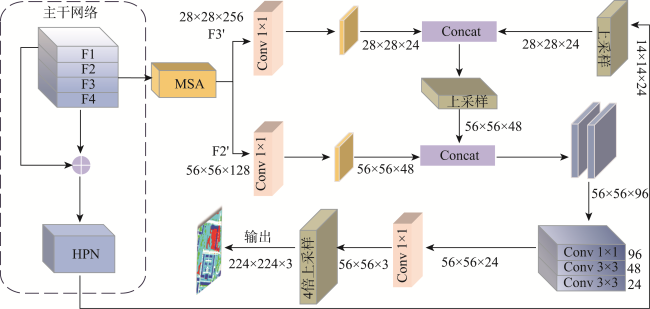
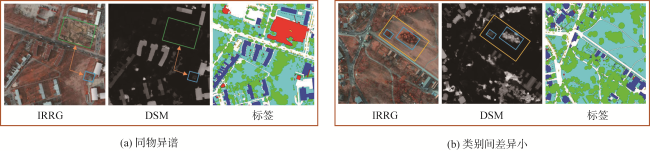
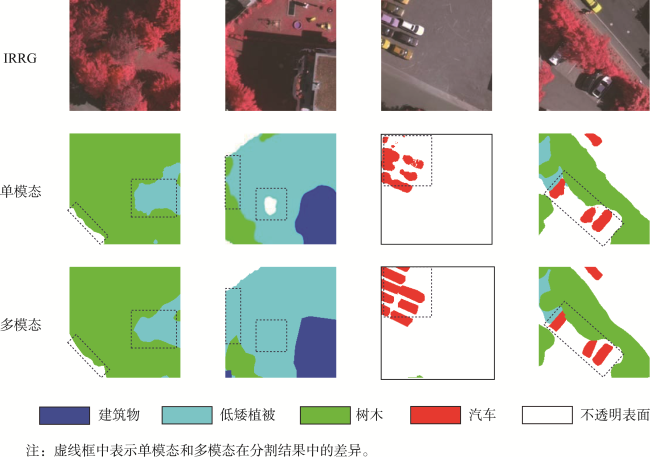
高分辨率遥感图像中存在物体视觉特征模糊和同物异谱的问题,在单一模态下对相似地物和阴影遮挡的地物分割较为困难,因此本文提出了一种基于多模态特征提取与层级感知的遥感图像分割模型。本文引入了多模态特征提取模块来提 取不同模态的特征信息,并通过坐标注意力机制充分融合不同模态的特征。抽象特征提取模块采用具有双路径瓶颈块的MobileNetV3作为主干网络,并引入了层级感知网络来提取深层次的抽象特征,通过嵌入像素的场景感知来改进注意力机制,实现高效且准确的类级上下文建模。解码部分设计了多尺度聚合双重融合,将低级特征与高级抽象语义特征相结合,利用逐步上采样实现特征恢复。本文基于ISPRS Vaihingen和Potsdam数据集上的高分辨率遥感图像,实验结果表明: ① 在包括C3Net、AMM-FuseNet、MMFNet、CMFet、CIMFNet和EDGNet在内的一系列对比模型中,MFEHPNet在各项性能指标上得到了显著提高,验证了遥感图像的语义分割性能; ② MFEHPNet在ISPRS Vaihingen和Potsdam的总体精度为92.21%和93.45%、平均交并比为83.24%和83.94%、Kappa为0.85、频率加权交并比为89.24%和90.12%,显著提高了遥感图像的语义分割性能,能有效解决分割中的特征边界模糊和同物异谱等问题。
张银胜 , 单梦姣 , 陈昕 , 陈戈 , 童俊毅 , 吉茹 , 单慧琳 . 基于多模态特征提取与层级感知的遥感图像分割[J]. 地球信息科学学报, 2024 , 26(12) : 2741 -2758 . DOI: 10.12082/dqxxkx.2024.240488
In high-resolution remote sensing images, challenges such as blurred visual features of objects and different spectra for the same object arise. Segmenting similar ground objects and shaded ground objects in a single mode is difficult. Therefore, this paper proposes a remote sensing image segmentation model based on multi-modal feature extraction and hierarchical perception. The proposed model introduces a multi-modal feature extraction module to capture feature information from different modalities. Using the complementary information of IRRG and DSM, accurate pixel positions in the feature map are obtained, improving semantic segmentation of high-resolution remote sensing images. The coordinate attention mechanism fully fuses the features from different modalities to address issues of blurred visual features and different object spectra during image segmentation. The abstract feature extraction module uses MobileNetV3 with dual-path bottleneck blocks as the backbone network, reducing the number of parameters while maintaining model accuracy. The hierarchical perception network is introduced to extract deep abstract features, and the attention mechanism is improved by embedding scene perception of pixels. Leveraging the inherent spatial correlation of ground objects in remote sensing images, efficient and accurate class-level context modeling is achieved, minimizing excessive background noise interference and significantly improving the semantic segmentation performance. In the decoding module, the model uses multi-scale aggregation dual fusion for feature recovery, strengthening the connection between the encoder and the decoder. This combines low-level features with high-level abstract semantic features, enabling effective spatial and detailed feature fusion. Progressive upsampling is used for feature recovery, resolving the issue of blurred visual features and improving segmentation accuracy. Based on high-resolution remote sensing images from the ISPRS Vaihingen and Potsdam datasets, the experimental results demonstrate that MFEHPNet outperforms a series of comparison models, including C3Net, AMM-FuseNet, MMFNet, CMFet, CIMFNet, and EDGNet, across various performance indicators. In the ISPRS Vaihingen and Potsdam datasets, MFEHPNet achieves an overall accuracy of 92.21% and 93.45%, an average intersection ratio of 83.24 % and 83.94 %, and a Kappa coefficient of 0.85. The frequency-weighted intersection ratio is 89.24 % and 90.12%, respectively, significantly improving the semantic segmentation performance of remote sensing images and effectively addressing the issues of blurred feature boundaries and different spectra during segmentation.
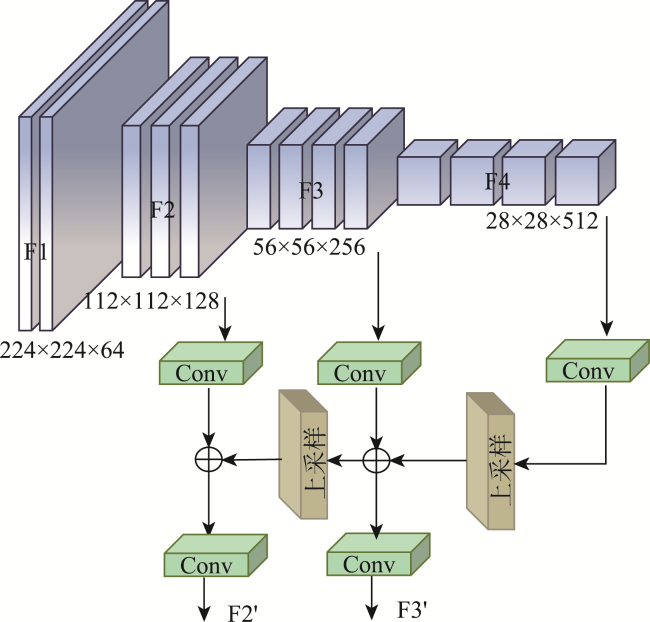
表1 MobileNetV3网络结构Tab. 1 The network structure of MobileNetV3 |
| 输入 | 操作 | 拓展大小 | #out | SE | NL | S |
|---|---|---|---|---|---|---|
| 2242×3 | conv2d | - | 16 | - | HS | 2 |
| 1122×16 | bneck,3×3 | 16 | 16 | - | RE | 1 |
| 1122×16 | DBB,3×3 | 64 | 24 | - | RE | 2 |
| 562×24 | bneck,3×3 | 72 | 24 | - | RE | 1 |
| 562×24 | DBB,5×5 | 72 | 40 | √ | RE | 2 |
| 282×40 | bneck,5×5 | 120 | 40 | √ | RE | 1 |
| 282×40 | bneck,5×5 | 120 | 40 | √ | RE | 1 |
| 282×40 | DBB,3×3 | 240 | 80 | - | HS | 2 |
| 142×80 | bneck,3×3 | 200 | 80 | - | HS | 1 |
| 142×80 | bneck,3×3 | 184 | 80 | - | HS | 1 |
| 142×80 | bneck,3×3 | 184 | 80 | - | HS | 1 |
| 142×80 | DBB,3×3 | 480 | 112 | √ | HS | 1 |
| 142×112 | bneck,3×3 | 672 | 112 | √ | HS | 1 |
| 142×112 | DBB,5×5 | 672 | 160 | √ | HS | 2 |
| 72×160 | bneck,5×5 | 960 | 160 | √ | HS | 1 |
| 72×160 | bneck,5×5 | 960 | 160 | √ | HS | 1 |
| 72×160 | conv2d,1×1 | - | 960 | - | HS | 1 |
| 72×960 | pool,7×7 | - | - | - | - | 1 |
| 12×960 | conv2d,1×1,NBN | - | 1280 | - | HS | 1 |
| 12×1 280 | conv2d,1×1,NBN | - | k | - | - | 1 |
注: #out表示输出通道的数量;SE表示是否使用SE模块; NL表示非线性激活函数的类型,其中包括HS(H-Swish)和RE(ReLU); S为步长,表示网络使用stride操作进行降采样; NBN表示没有BN操作;k表示卷积核的扩展因子。 |
表2 实验配置信息Tab. 2 Experimental configuration information |
| 配置名称 | 参数 |
|---|---|
| CPU | Intel(R) Core(TM) i9-12900KF |
| GPU | NVIDIA GeForce RTX3090 |
| 操作系统 | Windows 10 |
| 框架 | Pytorch1.12.0 |
| Memory | 32 G |
| Video Memory | 24 G |
表3 多模态融合方式实验对比(Vaihingen)Tab. 3 Experimental comparison of multi-modal fusion methods (Vaihingen) (%) |
| 融合方式 | OA | P | R | F1 | MIoU |
|---|---|---|---|---|---|
| Add | 88.74 | 89.06 | 82.42 | 85.91 | 80.97 |
| Concat | 90.21 | 89.78 | 86.16 | 87.63 | 82.66 |
| WS | 90.85 | 90.69 | 87.35 | 91.82 | 82.42 |
| CA | 91.66 | 92.14 | 89.83 | 92.55 | 82.89 |
注:加粗数值表示最优值。 |
表5 主干网络特征提取实验对比(Vaihingen)Tab. 5 Comparison of backbone network feature extraction (Vaihingen) |
| 网络 | OA/% | P/% | R/% | F1/% | FPS/(帧/s) | MIoU/% |
|---|---|---|---|---|---|---|
| ResNet | 81.87 | 83.61 | 80.14 | 81.46 | 97.38 | 76.91 |
| V3 | 85.44 | 86.03 | 81.89 | 82.90 | 106.21 | 79.39 |
| DBB | 86.54 | 87.21 | 82.73 | 84.92 | 113.11 | 80.78 |
注:加粗数值表示最优值。 |
表6 抽象深层特征提取实验对比(Vaihingen)Tab. 6 Comparison of abstract deep feature extraction (Vaihingen) (%) |
| 模块 | OA | P | R | F1 | MIoU |
|---|---|---|---|---|---|
| ASPP | 82.64 | 83.89 | 81.35 | 82.60 | 77.51 |
| D-A | 85.67 | 87.21 | 82.73 | 84.92 | 78.65 |
| HPN | 90.44 | 91.29 | 88.63 | 90.84 | 80.82 |
注:加粗数值表示最优值。 |
表7 解码方式提取实验对比(Vaihingen)Tab. 7 Experimental comparison of decoding method extraction (Vaihingen) (%) |
| 解码方式 | OA | P | R | F1 | MIoU |
|---|---|---|---|---|---|
| 4U | 91.42 | 92.07 | 89.73 | 91.90 | 78.44 |
| D2U | 92.04 | 92.76 | 91.41 | 92.39 | 80.39 |
| MSADF | 92.14 | 93.60 | 92.08 | 92.73 | 81.91 |
注:加粗数值表示最优值。 |
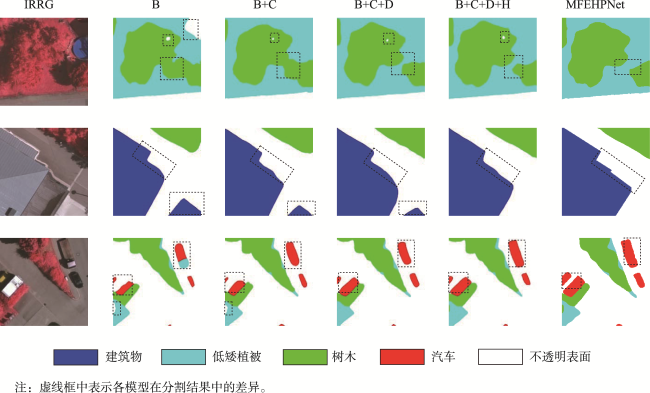
表8 各个模块的消融实验(Vaihingen)Tab. 8 Ablation experiments of each module (Vaihingen) |
| 模型 | OA/% | P/% | R/% | F1/% | MIoU/% | FPS/(帧/s) | Kappa | FWIoU/% |
|---|---|---|---|---|---|---|---|---|
| B | 86.26 | 86.74 | 76.59 | 81.35 | 78.69 | 92.97 | 0.74 | 84.12 |
| +C | 88.95 | 89.31 | 78.26 | 83.42 | 81.12 | 97.14 | 0.77 | 85.03 |
| +D | 86.70 | 87.22 | 76.84 | 81.79 | 79.06 | 98.31 | 0.76 | 82.55 |
| +H | 88.42 | 88.84 | 77.87 | 82.90 | 80.22 | 96.82 | 0.79 | 86.87 |
| +M | 87.64 | 88.03 | 77.39 | 82.36 | 79.47 | 96.09 | 0.78 | 83.65 |
| +CD | 89.48 | 89.93 | 78.98 | 83.16 | 81.52 | 98.83 | 0.77 | 87.57 |
| +CDH | 90.42 | 90.71 | 79.48 | 83.85 | 81.93 | 108.48 | 0.79 | 87.72 |
| +CHM | 90.94 | 91.50 | 80.03 | 84.43 | 82.68 | 106.21 | 0.83 | 86.92 |
| +CDHM | 92.21 | 92.66 | 80.51 | 87.94 | 83.24 | 113.11 | 0.85 | 89.24 |
注:加粗数值表示最优值。 |
表9 模型计算时间对比Tab. 9 Comparison of model calculation time |
| 模型 | 训练/h | 测试/s | |||
|---|---|---|---|---|---|
| Vaihingen | Potsdam | Vaihingen | Potsdam | ||
| C3Net | 12 | 21 | 1.25 | 1.70 | |
| AMM | 8 | 18 | 1.05 | 1.85 | |
| MMFNet | 9.5 | 16.38 | 0.95 | 1.35 | |
| CMFet | 8.5 | 13.5 | 0.85 | 1.25 | |
| CIMFNet | 10.0 | 17.5 | 1.25 | 1.75 | |
| EDGNet | 8.5 | 14.0 | 0.90 | 1.45 | |
| HFESANet | 7.5 | 12.0 | 0.80 | 1.20 | |
注:加粗数值表示最优值。 |
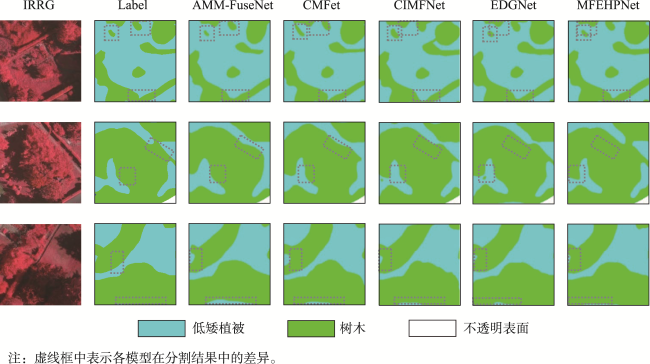
表10 不同模型对比实验(Vaihingen)Tab. 10 Comparative experiments of different models (Vaihingen) |
| 模型 | F1/% | OA /% | MIoU/% | Kappa | FWIoU/% | ||||
|---|---|---|---|---|---|---|---|---|---|
| 建筑物 | 低矮植被 | 树木 | 汽车 | 不透明表面 | |||||
| C3Net | 89.04 | 80.52 | 85.53 | 84.77 | 88.92 | 86.50 | 78.41 | 0.65 | 82.56 |
| AMM | 89.63 | 82.29 | 86.51 | 85.46 | 89.35 | 87.44 | 79.68 | 0.70 | 84.37 |
| MMFNet | 90.55 | 82.79 | 86.83 | 85.54 | 89.53 | 88.01 | 78.93 | 0.78 | 82.69 |
| CMFet | 91.14 | 83.00 | 87.05 | 86.44 | 90.41 | 88.63 | 80.89 | 0.79 | 85.48 |
| CIMFNet | 92.37 | 83.74 | 87.26 | 87.72 | 90.64 | 89.38 | 80.42 | 0.82 | 84.82 |
| EDGNet | 93.65 | 84.11 | 88.68 | 88.85 | 90.87 | 89.94 | 82.31 | 0.80 | 86.68 |
| HFESANet | 93.89 | 85.71 | 89.14 | 89.78 | 91.19 | 92.21 | 83.24 | 0.85 | 89.24 |
注:加粗数值表示最优值。 |
表11 不同模型对比实验(Potsdam)Tab. 11 Comparative experiments of different models (Potsdam) |
| 模型 | F1/% | OA/% | MIoU/% | Kappa | FWIoU | ||||
|---|---|---|---|---|---|---|---|---|---|
| 建筑物 | 低矮植被 | 树木 | 汽车 | 不透明表面 | |||||
| C3Net | 92.89 | 86.86 | 88.01 | 89.45 | 90.45 | 90.07 | 79.21 | 0.71 | 83.50 |
| AMM | 92.35 | 86.13 | 87.76 | 89.14 | 89.34 | 89.89 | 80.04 | 0.70 | 85.37 |
| MMFNet | 93.23 | 87.39 | 88.90 | 89.02 | 90.68 | 90.34 | 79.92 | 0.74 | 84.42 |
| CMFet | 93.56 | 87.66 | 89.12 | 89.76 | 90.23 | 90.72 | 81.29 | 0.79 | 85.69 |
| CIMFNet | 94.17 | 88.30 | 90.08 | 90.08 | 90.91 | 91.21 | 81.66 | 0.78 | 86.41 |
| EDGNet | 94.55 | 88.67 | 89.83 | 90.56 | 91.64 | 91.57 | 82.57 | 0.84 | 88.62 |
| HFESANet | 95.01 | 89.42 | 90.30 | 91.79 | 92.34 | 93.45 | 83.94 | 0.85 | 90.12 |
注:加粗数值表示最优值。 |
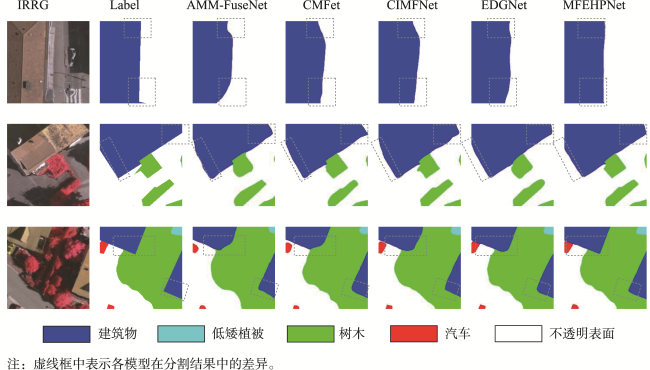
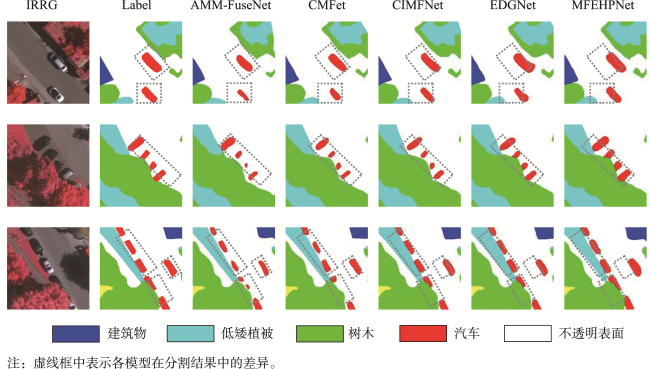
图14 Vaihingen中低矮植被和树木分割结果Fig. 14 Segmentation results of low vegetation and trees in Vaihingen |
图15 Vaihingen中建筑物和背景分割结果Fig. 15 Segmentation results of buildings and roads in Vaihingen |
| [1] |
韦兴旺, 张雪锋, 薛云. 基于光谱和形状的遥感图像分割质量评估方法[J]. 地球信息科学学报, 2018, 20(10):1489-1499.
[
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
张寅丹, 王苗苗, 陆海霞, 等. 基于监督与非监督分割评价方法提取高分辨率遥感影像特定目标地物的对比研究[J]. 地球信息科学学报, 2019, 21(9):1430-1443.
[
|
| [7] |
李倩楠, 张杜娟, 潘耀忠, 等. MPSPNet和UNet网络下山东省高分辨耕地遥感提取[J]. 遥感学报, 2023, 27(2):471-491.
[
|
| [8] |
|
| [9] |
蒋伟杰, 张春菊, 徐兵, 等. AED-Net:滑坡灾害遥感影像语义分割模型[J]. 地球信息科学学报, 2023, 25(10):2012-2025.
[
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
张银胜, 吉茹, 童俊毅, 等. 基于双模态高效特征学习的高分辨率遥感图像分割[J]. 遥感学报, 2024, 28(2):481-493.
[
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
孙汉淇, 潘晨, 何灵敏, 等. 多模态特征融合的遥感图像语义分割网络[J]. 计算机工程与应用, 2022, 58(24):256-264.
[
|
| [24] |
李钰, 袁晴龙, 徐少铭, 等. 基于感知注意力和轻量金字塔融合网络模型的室内场景语义分割方法[J]. 华东理工大学学报(自然科学版), 2023, 49(1):116-127.
[
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
郑凯, 李建胜, 杨戬峰, 等. 天绘一号卫星遥感影像云雪检测的ResNet与DeepLabV3+综合法[J]. 测绘学报, 2020, 49(10):1343-1353.
[
|
| [32] |
|
| [33] |
|
/
| 〈 |
|
〉 |




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}