
基于Al大模型的文生图技术方法研究及应用
作者贡献:Author Contributions
本研究由张新长构思;赵元和冯炜明完成实验设计和操作;张新长、齐霁、赵元和冯炜明完成论文的写作和修改。所有作者均阅读并同意最终稿件的提交。
The study was designed by ZHANG Xinchang. The experimental operation was completed by ZHAO Yuan, and FENG Weiming. The manuscript was drafted and revised by ZHANG Xinchang, QI Ji, ZHAO Yuan, and FENG Weiming. All the authors have read the last version of paper and consented for submission.
|
张新长(1957— ),男,新疆乌鲁木齐人,博士,教授,国际欧亚科学院院士、俄罗斯工程院外籍院士,主要从事空间数据整合及自适应更新技术方法、数字城市(智慧城市)理论与方法、深度学习与自然资源要素分类和提取等方面的教学与研究工作。E-mail: zhangxc@gzhu.edu.cn |
收稿日期: 2024-11-27
修回日期: 2024-12-14
网络出版日期: 2025-01-23
基金资助
国家自然科学基金面上项目(42071441)
国家自然科学基金面上项目(42371406)
Research and Application of Text-to-Image Technology Based on Al Foundation Models
Received date: 2024-11-27
Revised date: 2024-12-14
Online published: 2025-01-23
Supported by
National Natural Science Foundation of China(42071441)
National Natural Science Foundation of China(42371406)
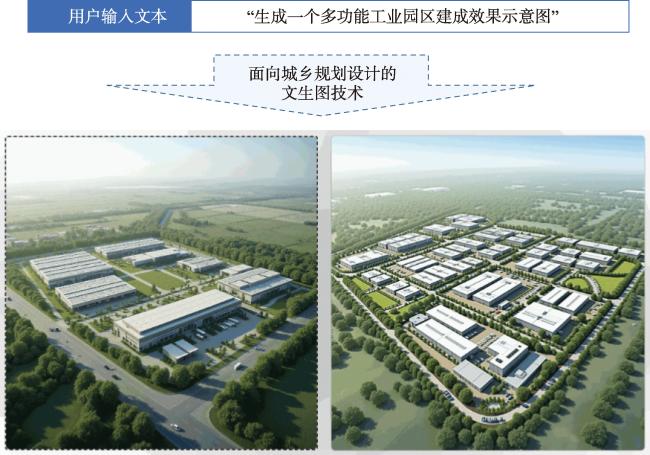
【目的】系统梳理基于AI大模型的文生图技术的进展,并探讨该技术在城乡规划领域的应用。【探讨】本文首先分别从训练数据集、模型和评价方法3个视角出发,对文生图技术发展进行了全面、系统的回顾,以揭示其成功背后的推动性因素。尽管文生图技术在通用计算机领域取得显著进展,但城乡规划领域的实际应用中仍面临诸多关键挑战,包括缺乏高质量领域数据、生成内容的可控性和可靠性不足,以及缺乏地学先验知识约束等。针对这些问题,本文提出了相应的研究思路,包括:面向领域需求的文生图数据增强策略、基于指令拓展的空间信息增强文生图模型、以及基于诱导布局的局部编辑文生图模型。在此基础上,结合多个实际应用案例展示文生图技术在城乡规划设计领域的应用价值和潜力。【展望】文生图技术通过技术突破和多学科融合,有望成为城乡规划设计领域的重要创新动力,为高效、智能化的设计实践提供支持。
张新长 , 赵元 , 齐霁 , 冯炜明 . 基于Al大模型的文生图技术方法研究及应用[J]. 地球信息科学学报, 2025 , 27(1) : 10 -26 . DOI: 10.12082/dqxxkx.2025.240657
[Objectives] To systematically review recent advancements in text-to-image generation technology driven by large-scale AI models and explore its potential applications in urban and rural planning. [Discussion] This study provides a comprehensive review of the development of text-to-image generation technology from the perspectives of training datasets, model architectures, and evaluation methods, highlighting the key factors contributing to its success. While this technology has achieved remarkable progress in general computer science, its application in urban and rural planning remains constrained by several critical challenges. These include the lack of high-quality domain-specific data, limited controllability and reliability of generated content, and the absence of constraints informed by geoscience expertise. To address these challenges, this paper proposes several research strategies, including domain-specific data augmentation techniques, text-to-image generation models enhanced with spatial information through instruction-based extensions, and locally editable models guided by induced layouts. Furthermore, through multiple case studies, the paper demonstrates the value and potential of text-to-image generation technology in facilitating innovative practices in urban and rural planning and design. [Prospect] With continued technological advancements and interdisciplinary integration, text-to-image generation technology holds promise as a significant driver of innovation in urban and rural planning and design. It is expected to support more efficient and intelligent design practices, paving the way for groundbreaking applications in this field.
利益冲突:Conflicts of Interest 所有作者声明不存在利益冲突。
All authors disclose no relevant conflicts of interest.
①
②
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
张岸, 朱俊锴. 新一代人工智能驱动下地图学研究的机遇与挑战[J]. 地球信息科学学报, 2024, 26(1):35-45.
[
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
朱禹, 叶继元. 人工智能生成内容(AIGC)研究综述:国际进展与热点议题[J]. 信息与管理研究, 2024, 9(4):13-27.
[
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
刘安安, 苏育挺, 王岚君, 等. AIGC视觉内容生成与溯源研究进展[J]. 中国图象图形学报, 2024, 29(6):1535-1554.
[
|
| [19] |
王常圣. 面向大模型艺术图像生成的提示词工程研究[J]. 图学学报,2024:1-14.
[
|
| [20] |
赖丽娜, 米瑜, 周龙龙, 等. 生成对抗网络与文本图像生成方法综述[J]. 计算机工程与应用, 2023, 59(19):21-39.
[
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
林懿伦, 戴星原, 李力, 等. 人工智能研究的新前线:生成式对抗网络[J]. 自动化学报, 2018, 44(5):775-792.
[
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
胡铭菲, 左信, 刘建伟. 深度生成模型综述[J]. 自动化学报, 2022, 48(1):40-74.
[
|
| [46] |
谢天圻, 吴媛媛, 敬超, 等. GAN模型生成图像检测方法综述[J]. 计算机工程与应用, 2024, 60(22):74-86.
[
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
|
| [51] |
|
| [52] |
|
| [53] |
|
| [54] |
|
| [55] |
|
| [56] |
|
| [57] |
|
| [58] |
|
| [59] |
|
| [60] |
|
| [61] |
|
| [62] |
|
| [63] |
|
| [64] |
|
| [65] |
|
| [66] |
|
| [67] |
|
| [68] |
|
| [69] |
|
| [70] |
|
| [71] |
|
| [72] |
|
| [73] |
|
/
| 〈 |
|
〉 |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}