
基于多尺度特征聚合的轻量化跨视角匹配定位方法
作者贡献:Author Contributions
刘瑞康和卢俊参与了实验设计;刘瑞康、卢俊、郭海涛、张雪松完成实验操作;刘瑞康、朱坤、侯青峰、汪泽田参与论文的写作和修改。所有作者均阅读并同意最终稿件的提交。
The study was designed by LIU Ruikang and LU Jun. The experimental operation was completed by LIU Ruikang, LU Jun, GUO Haitao and ZHANG Xuesong. The manuscript was drafted and revised by LIU Ruikang, ZHU Kun, HOU Qingfeng and WANG Zetian. All the authors have read the last version of paper and consented for submission.
|
刘瑞康(2000— ),男,山东烟台人,硕士生,主要从事多尺度跨视角遥感影像场景匹配与定位方面的研究。E-mail: 13001613005@163.com。 |
收稿日期: 2024-09-27
修回日期: 2024-12-03
网络出版日期: 2025-01-23
基金资助
国家自然科学基金项目(42301464)
国家自然科学基金项目(42201443)
A Lightweight Cross-View Image Localization Method Based on Multi-Scale Feature Aggregation
Received date: 2024-09-27
Revised date: 2024-12-03
Online published: 2025-01-23
Supported by
National Natural Science Foundation of China(42301464)
National Natural Science Foundation of China(42201443)
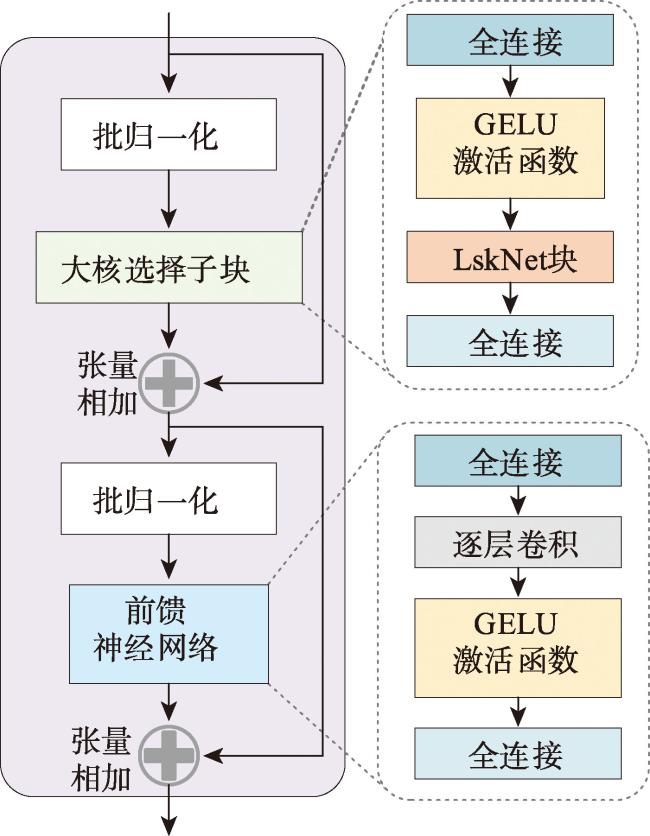
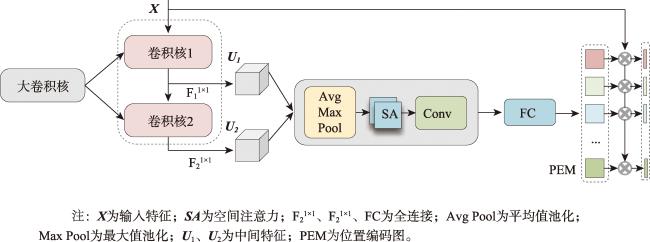
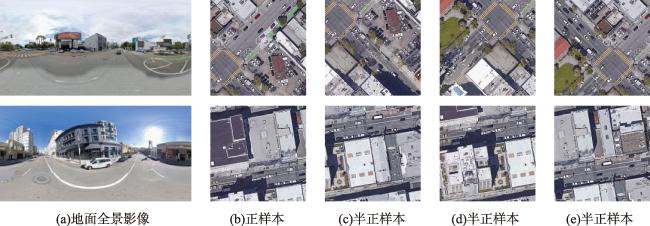
【目的】跨视角图像匹配与定位是指通过将地视查询影像与带有地理标记的空视参考影像进行匹配,从而确定地视查询影像地理位置的技术。目前的跨视角图像匹配与定位技术主要使用固定感受野的CNN或者具有全局建模能力的Transformer作为特征提取主干网络,不能充分考虑影像中不同特征之间的尺度差异,且由于网络参数量和计算复杂度较高,轻量化部署面临显著挑战。【方法】为了解决这些问题,本文提出了一种面向地面全景影像和卫星影像的多尺度特征聚合轻量化跨视角图像匹配与定位方法,首先使用LskNet提取影像特征,然后设计一个多尺度特征聚合模块,将影像特征聚合为全局描述符。在该模块中,本文将单个大卷积核分解为两个连续的相对较小的逐层卷积,从多个尺度聚合影像特征,显著减少了网络的参数量与计算量。【结果】本文在CVUSA、CVACT、VIGOR 3个公开数据集上进行了对比实验和消融实验,实验结果表明,本文方法在VIGOR数据集和CVACT数据集上的Top1召回率分别达到79.00%和91.43%,相比于目前精度最高的Sample4Geo分别提升了1.14%、0.62%,在CVUSA数据集上的Top1召回率达到98.64%,与Sample4Geo几乎相同,但参数量与计算量降至30.09 M和16.05 GFLOPs,仅为Sample4Geo的34.36%、23.70%。【结论】与现有方法相比,本文方法在保持高精度的同时,显著减少了参数量和计算量,降低了模型部署的硬件要求。
刘瑞康 , 卢俊 , 郭海涛 , 朱坤 , 侯青峰 , 张雪松 , 汪泽田 . 基于多尺度特征聚合的轻量化跨视角匹配定位方法[J]. 地球信息科学学报, 2025 , 27(1) : 193 -206 . DOI: 10.12082/dqxxkx.2025.240538
[Objectives] Cross-view image matching and localization refers to the technique of determining the geographic location of a ground-view query image by matching it with a geotagged aerial reference image. However, significant differences in geometric appearance and spatial layout between different viewpoints often hinder traditional image matching algorithms. Existing methods for cross-view image matching and localization typically rely on Convolutional Neural Networks (CNNs) with fixed receptive fields or Transformers with global modeling capabilities for feature extraction. However, these approaches fail to fully address the scale differences among various features in the image. Additionally, due to their large number of network parameters and high computational complexity, these methods face significant challenges in lightweight deployment. [Methods] To address these issues, this paper proposes a lightweight cross-view image matching and localization method that employs multi-scale feature aggregation for ground panoramic and satellite images. The method first extracts image features using LskNet, then designs and introduces a multi-scale feature aggregation module to combine image features into a global descriptor. The module decomposes a single large convolution kernel into two sequential smaller depth-wise convolutions, enabling multiple scale feature aggregation. Meanwhile, spatial layout information is encoded into the global feature, producing a more discriminative global descriptor. By integrating LskNet and the multi-scale feature aggregation module, the proposed method significantly reduces parameters and computational cost while achieving superior accuracy on publicly available datasets. [Results] Experimental results on the CVUSA, CVACT, and VIGOR datasets demonstrate that the proposed method achieves Top-1 recall rates of 79.00% and 91.43% on the VIGOR and CVACT datasets, respectively, surpassing the current highest-accuracy method, Sample4Geo, by 1.14% and 0.62%. On the CVUSA dataset, the Top-1 recall rate reaches 98.64%, comparable to Sample4Geo, but with parameters and computational costs reduced to 30.09 M and 16.05 GFLOPs, representing only 34.36% and 23.70% of Sample4Geo's values, respectively. Additionally, ablation experiments on public datasets show that the multi-scale feature aggregation module improves the Top-1 recall rate of the baseline network by 1.60% on the CVUSA dataset and by 13.48% on the VIGOR dataset, further validating the effectiveness of the proposed method. [Conclusions] Compared to existing methods, the proposed algorithm significantly reduces both parameters and computational costs while maintaining high accuracy, thereby lowering hardware requirements for model deployment.
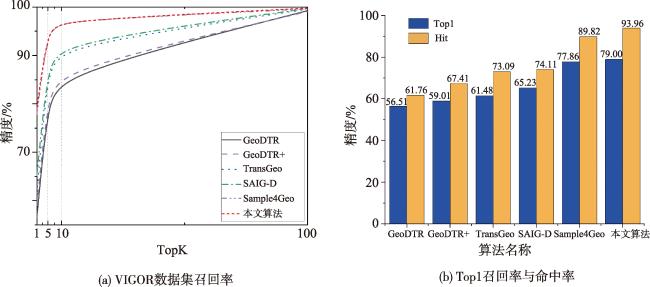
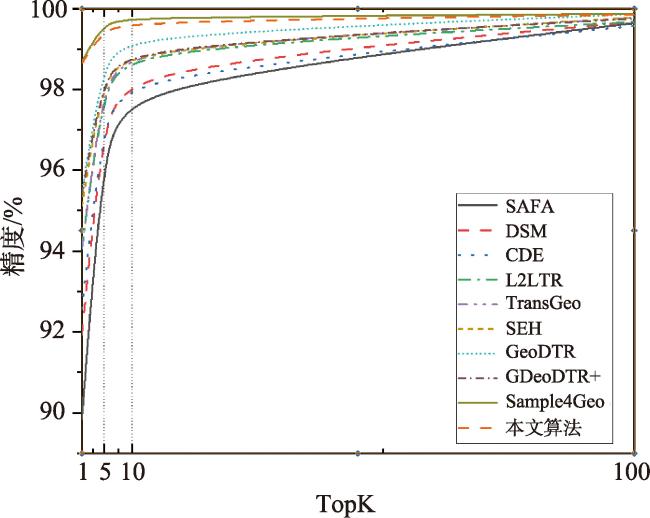
表2 VIGOR数据集匹配精度Tab. 2 Retrieval accuracy (percentage) of different methods on VIGOR dataset (%) |
| 算法 | R@1 | R@5 | R@10 | R@1% | Hit Rate |
|---|---|---|---|---|---|
| GeoDTR[25] | 56.51 | 80.37 | 86.21 | 99.25 | 61.76 |
| GeoDTR+[23] | 59.01 | 81.77 | 87.10 | 99.07 | 67.41 |
| TransGeo[14] | 61.48 | 87.54 | 91.88 | 99.56 | 73.09 |
| SAIG-D[26] | 65.23 | 88.08 | - | 99.68 | 74.11 |
| Sample4Geo[11] | 77.86 | 95.66 | 97.21 | 99.61 | 89.82 |
| 本文算法 | 79.00 | 95.65 | 97.18 | 99.77 | 93.96 |
注:加粗数值为每列最优值,“-”表示原论文中未提供该数值。 |
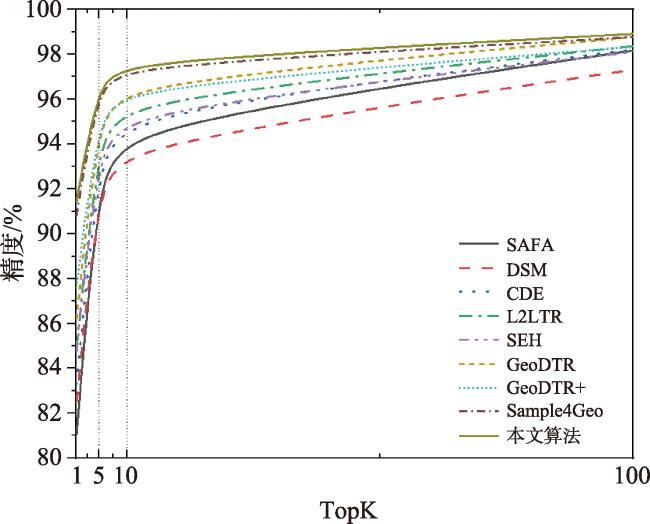
表3 CVUSA数据集匹配精度Tab. 3 Retrieval accuracy (percentage) of different methods on CVUSA dataset (%) |
| 算法 | R@1 | R@5 | R@10 | R@1% |
|---|---|---|---|---|
| SAFA[7] | 89.84 | 96.93 | 98.14 | 99.64 |
| DSM[22] | 91.93 | 97.50 | 98.54 | 99.67 |
| CDE[8] | 92.56 | 97.55 | 98.33 | 99.57 |
| L2LTR[16] | 94.05 | 98.27 | 98.99 | 99.67 |
| TransGeo[14] | 94.08 | 98.36 | 99.04 | 99.77 |
| SEH[27] | 95.11 | 98.45 | 99.00 | 99.78 |
| GeoDTR[25] | 95.43 | 98.86 | 99.34 | 99.86 |
| GeoDTR+[23] | 95.40 | 98.44 | 99.05 | 99.75 |
| Sample4Geo[11] | 98.68 | 99.68 | 99.78 | 99.87 |
| 本文算法 | 98.64 | 99.50 | 99.67 | 99.85 |
注:加粗数值为每列最优值。 |
表4 CVACT数据集匹配精度Tab.4 Retrieval accuracy (percentage) of different methods on CVACT dataset (%) |
| 算法 | R@1 | R@5 | R@10 | R@1% |
|---|---|---|---|---|
| SAFA[7] | 81.03 | 92.80 | 94.84 | 98.17 |
| DSM[22] | 82.49 | 92.44 | 93.99 | 97.32 |
| CDE[8] | 83.28 | 93.57 | 95.42 | 98.22 |
| L2LTR[16] | 84.89 | 94.59 | 95.96 | 98.37 |
| SHE[27] | 84.75 | 93.97 | 95.46 | 98.11 |
| GeoDTR[25] | 86.21 | 95.44 | 96.72 | 98.77 |
| GeoDTR+[23] | 87.61 | 95.48 | 96.52 | 98.34 |
| Sample4Geo[11] | 90.81 | 96.74 | 97.48 | 98.77 |
| 本文算法 | 91.43 | 96.90 | 97.69 | 98.92 |
注:加粗数值为每列最优值。 |
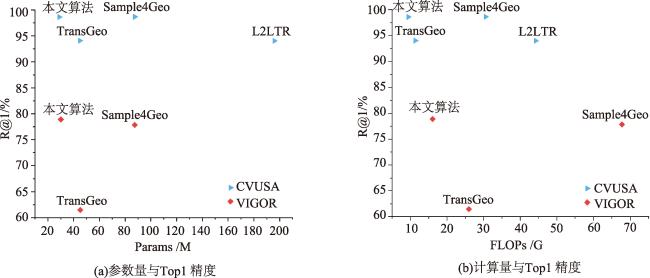
表5 不同模型参数量、计算量对比Tab. 5 Comparison of parameter count and computational cost for different models |
| 算法 | CVUSA | VIGOR | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 参数量/M | 共享权重 | 计算量/GFLOPs | R@1/% | 参数量/M | 共享权重 | 计算量/GFLOPs | R@1/% | ||
| 本算法 | 28.85 | × | 9.41 | 98.64 | 30.09 | × | 16.05 | 79.00 | |
| TransGeo | 44.92 | × | 11.34 | 94.08 | 45.18 | × | 25.96 | 61.48 | |
| Sample4Geo | 87.57 | √ | 30.50 | 98.68 | 87.57 | √ | 67.71 | 77.86 | |
| L2LTR | 195.91 | × | 44.16 | 94.05 | × | × | × | × | |
注:加粗数值为每列最优值。 |
表6 卷积核分解消融实验Tab. 6 Ablation Experiment on Convolution Kernel Decomposition (%) |
| R@1 | R@5 | R@10 | R@1% | Hit Rate | |
|---|---|---|---|---|---|
| 单个大卷积核 | 77.12 | 94.42 | 96.38 | 99.75 | 92.10 |
| 卷积核分解 | 79.00 | 95.65 | 97.18 | 99.77 | 93.96 |
注:加粗数值为每列最优值。 |
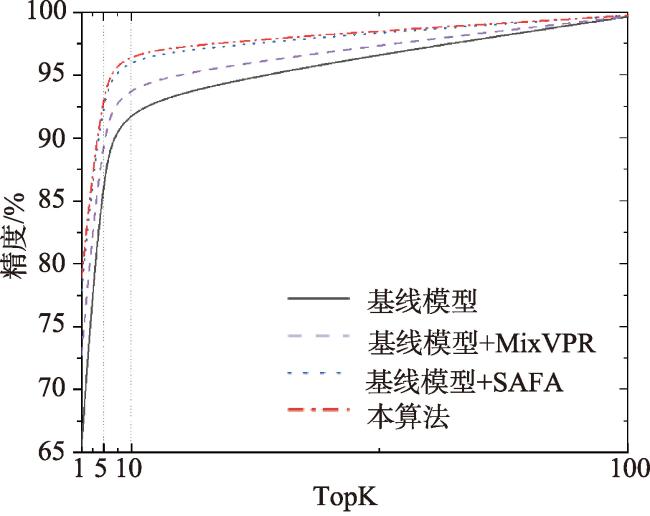
表7 多尺度特征聚合消融实验Tab. 7 Ablation experiment on multi-scale feature aggregation (%) |
| 算法 | VIGOR | CVUSA | |||||||
|---|---|---|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@1% | R@1 | R@5 | R@10 | R@1% | ||
| 基线模型 | 65.52 | 89.99 | 93.69 | 99.66 | 97.04 | 99.26 | 99.47 | 99.88 | |
| 基线模型+MixVPR | 72.74 | 92.52 | 95.13 | 99.69 | 97.34 | 99.38 | 99.57 | 99.86 | |
| 基线模型+SAFA | 77.87 | 95.19 | 97.02 | 99.77 | 98.19 | 99.50 | 99.66 | 99.84 | |
| 本算法 | 79.00 | 95.65 | 97.18 | 99.77 | 98.64 | 99.50 | 99.67 | 99.85 | |
注:加粗数值为每列最优值。 |
利益冲突:Conflicts of Interest 所有作者声明不存在利益冲突。
All authors disclose no relevant conflicts of interest.
| [1] |
|
| [2] |
朱容蔚, 詹银虎, 李广云. 利用恒星与低轨卫星同时成像实现地面定位的算法[J]. 测绘学报, 2024, 53(7):1278-1287.
[
|
| [3] |
饶子昱, 卢俊, 郭海涛, et al. 利用视角转换的跨视角影像匹配方法[J]. 地球信息科学学报, 2023, 25(2):368-379.
[
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
/
| 〈 |
|
〉 |






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}