
细节增强与跨尺度几何特征融合的遥感影像建筑物提取网络
|
苏世龙(2000— ),男,河南开封人,硕士生,研究方向为遥感计算机视觉理解。E-mail: xjdssl163@163.com |
Copy editor: 黄光玉 , 蒋树芳
收稿日期: 2024-11-14
修回日期: 2025-02-12
网络出版日期: 2025-03-25
基金资助
国家自然科学基金面上项目(52278125)
Detail Enhancement and Cross-Scale Geometric Feature Sharing Network for Remote Sensing Building Extraction
Received date: 2024-11-14
Revised date: 2025-02-12
Online published: 2025-03-25
Supported by
National Natural Science Foundation of China(52278125)
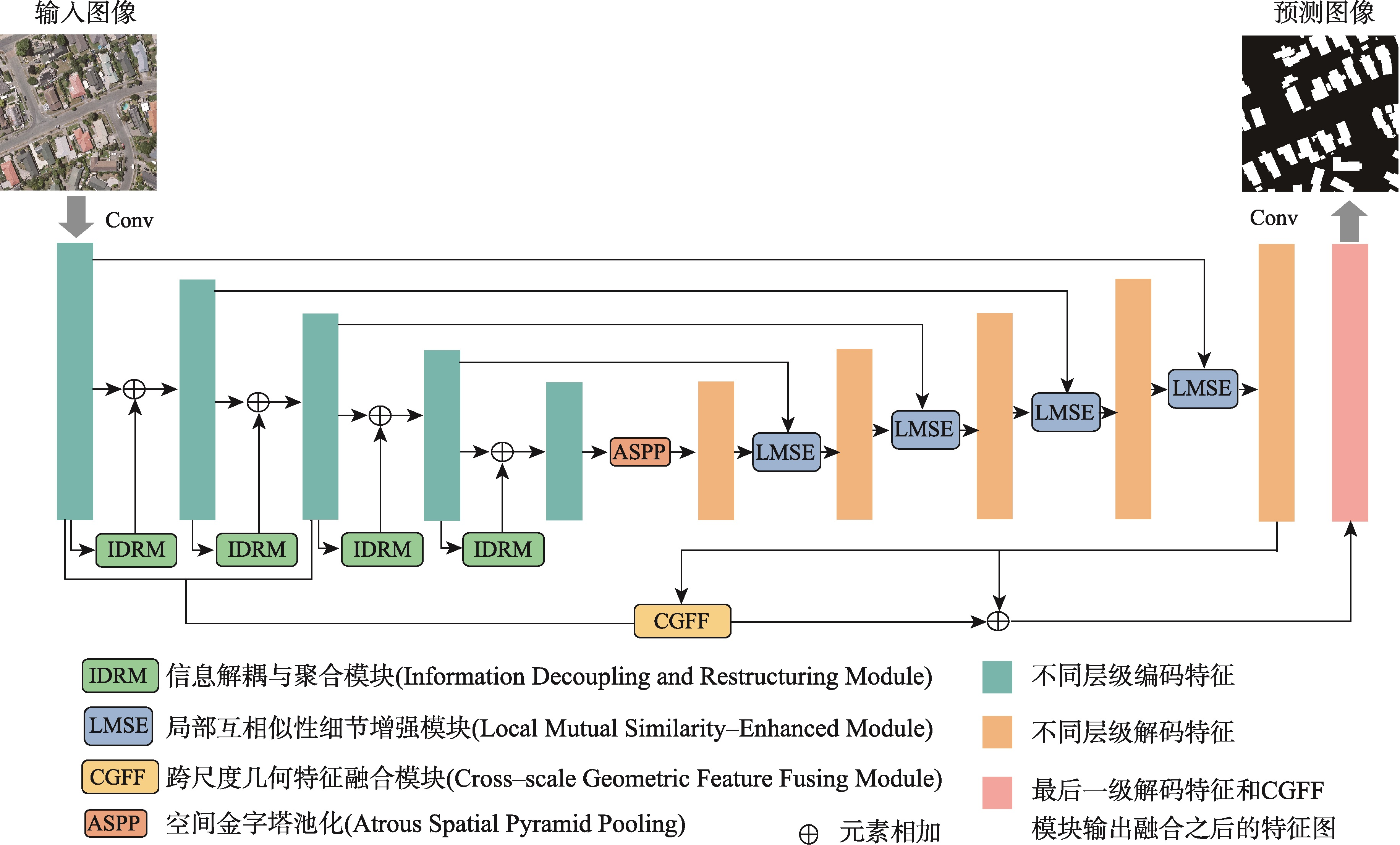
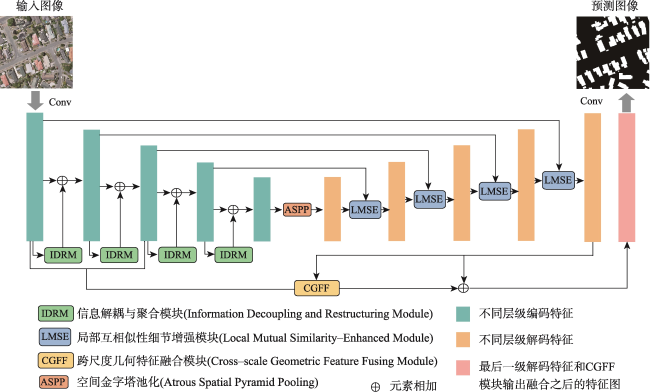
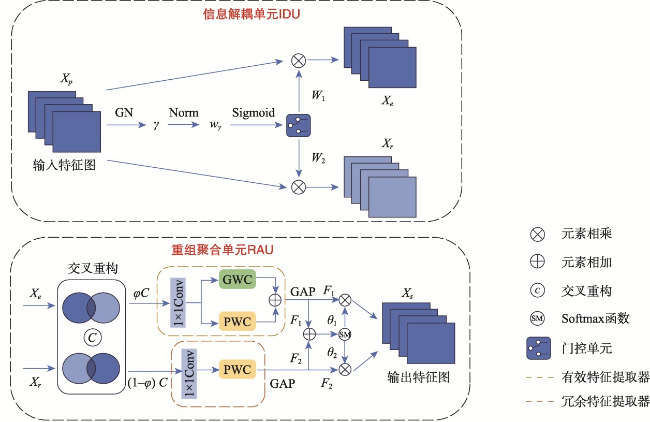
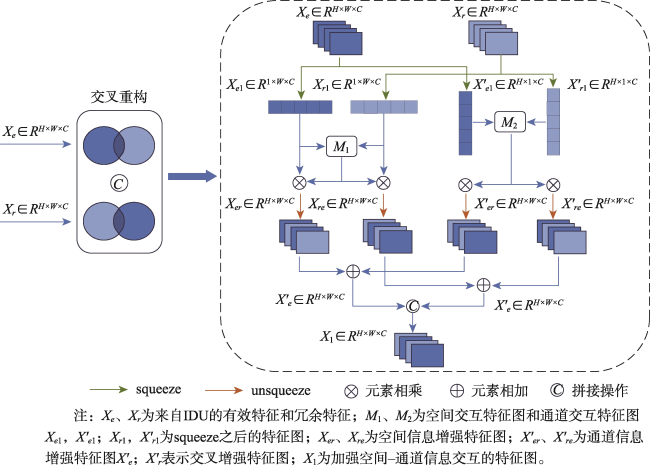
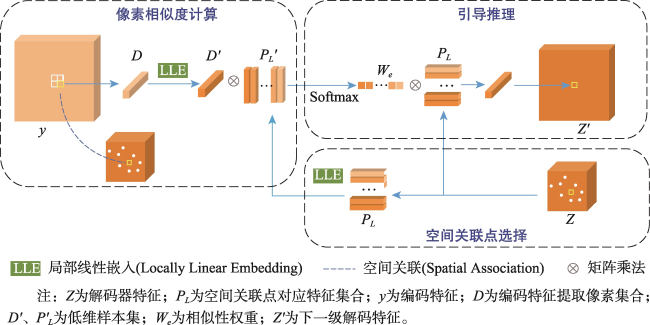
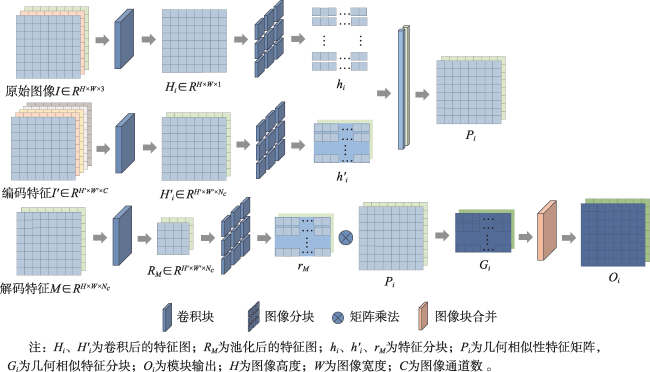
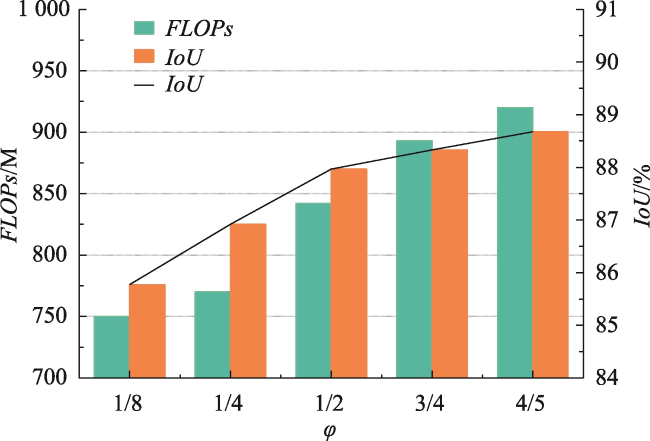
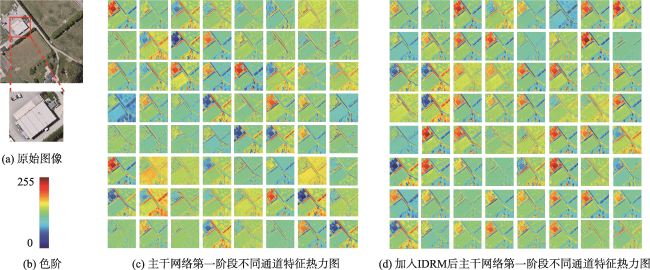
【目的】针对现有遥感影像建筑物提取模型中因冗余导致的特征表示能力差、建筑物边界不清晰及微小建筑物丢失问题。【方法】提出一种细节增强与跨尺度几何特征融合网络DCS-Net,由信息解耦与聚合模块(IRDM)、局部互相似性细节增强模块(LMSE)和引导小目标推理的跨尺度几何特征融合模块(CGFF)组成。IRDM模块通过分配权重将冗余特征分离并重构,从空间和通道2个维度抑制冗余,促进有效特征学习; LMSE模块通过动态选择窗格以及编-解码特征之间的局部互相似性指定像素聚类,提升建筑物边缘信息的准确性和完整性; CGFF模块计算原始图像与不同语义级特征图间的特征分块关系,补偿信息损失以提升微小建筑物的提取性能。【结果】本文的实验基于2个公开数据集: WHU航拍数据集和Massachusetts建筑物检测数据集。实验结果表明,与UNet、PSPNet、Deeplab V3+、MANet、MAPNet、DRNet、Build-Former、MBR-HRNet、SDSNet、HDNet、DFFNet、UANet等现有建筑物提取算法相比,DCS-Net在各项评价指标中得到了显著提升,验证了所提方法的有效性。在WHU数据集上的交并比、 F1值和95%HD达到92.94%、96.35%和75.79,对比现有最佳算法分别提升了0.79%、0.44%和1.90;在Massachusetts数据集上的指标为77.13%、87.06%和205.26,分别提升了0.72%、0.43%和13.84。【结论】DCS-Net能更为准确完整地提取出遥感影像中的建筑物,并显著缓解微小建筑物丢失的问题。
孟月波 , 苏世龙 , 黄欣羽 , 王恒 . 细节增强与跨尺度几何特征融合的遥感影像建筑物提取网络[J]. 地球信息科学学报, 2025 , 27(4) : 930 -945 . DOI: 10.12082/dqxxkx.2025.240633
[Objectives] To address issues in existing remote sensing building extraction models, including poor feature representation ability due to redundancy, unclear building boundaries, and the loss of small buildings, [Methods] we propose a detail enhancement and cross-scale geometric feature sharing network (DCS-Net). This network consists of an Information Decoupling and Aggregation Module (IRDM), a Local Mutual Similarity Detail Enhancement Module (LMSE), and a Cross-scale Geometric Feature Fusing Module (CGFF), designed to guide small target inference. The IRDM module separates and reconstructs redundant features by assigning weights, thereby suppressing redundancy in both spatial and channel dimensions and promoting effective feature learning. The LMSE module enhances the accuracy and completeness of building edge information by dynamically selecting windows and specifying pixel clustering based on local mutual similarity between encoder-decoder features. The CGFF module computes the feature block relationships between the original image and various semantic-level feature maps to compensate for information loss, thereby improving the extraction performance of small buildings. [Results] The experiments in this paper are based on two public datasets: the WHU aerial dataset and the Massachusetts building detection dataset. The experimental results demonstrate the following: (1) Compared with existing building extraction algorithms such as UNet, PSPNet, Deeplab V3+, MANet, MAPNet, DRNet, Build-Former, MBR-HRNet, SDSNet, HDNet, DFFNet, and UANet, DCS-Net has achieved significant improvements across various evaluation metrics, demonstrating the effectiveness of the proposed method. (2) On the WHU dataset, the Intersection over Union (IoU), F1 score, and 95% Hausdorff Distance (95%HD) reached 92.94%, 96.35%, and 75.79%, respectively, outperforming the current best algorithm by 0.79%, 0.44%, and 1.90%. (3) On the Massachusetts dataset, the metrics were 77.13%, 87.06%, and 205.26, with improvements of 0.72%, 0.43%, and 13.84%, respectively. [Conclusions] These results indicate that DCS-Net can more accurately and comprehensively extract buildings from remote sensing images, significantly alleviating the issue of small building loss.
表1 WHU遥感建筑物数据集定量评估结果Tab. 1 Quantitative evaluation results of WHU remote sensing building dataset |
| 提取方法 | 评价指标 | 参数量 | |||||
|---|---|---|---|---|---|---|---|
| IoU/% | Pre/% | Rec/% | F1/% | 95%HD | Params/M | ||
| UNet | 84.15 | 90.72 | 92.41 | 91.24 | 82.13 | 17.26 | |
| PSPNet | 85.51 | 92.32 | 92.52 | 92.39 | 83.61 | 53.58 | |
| DeeplabV3+ | 85.43 | 91.96 | 92.31 | 92.13 | 81.23 | 15.31 | |
| MAPNet | 89.94 | 95.59 | 93.84 | 94.7 | 85.18 | 24.00 | |
| DR-Net | 88.3 | 94.31 | 94.31 | 94.38 | 88.56 | 10.00 | |
| MBR-HRNet | 91.31 | 95.48 | 94.88 | 95.18 | 80.02 | 31.02 | |
| CFENet | 89.31 | 94.33 | 94.39 | 94.35 | 83.46 | 171.00 | |
| SDSNet | 90.20 | 95.32 | 94.41 | 94.82 | 83.52 | 65.14 | |
| HDNet | 90.4 | 95.00 | 95.00 | 95.00 | 82.13 | 13.89 | |
| DFFNet | 90.5 | 95.4 | 94.6 | 95.0 | 80.73 | 32.15 | |
| BuildFormer | 91.44 | 95.65 | 95.4 | 95.53 | 79.37 | 40.52 | |
| UANet | 92.15 | 95.96 | 95.86 | 95.91 | 77.69 | 38.15 | |
| 本文方法 | 92.94 | 96.37 | 96.33 | 96.35 | 75.79 | 28.50 | |
注:加粗数值表示定量对比实验中最优评价指标。95%HD是95%的豪斯多夫距离,数值表示2个点集的相似程度,数值越大表示差异越大,反之越小,无具体单位。 Params是模型参数量,因语义分割模型参数量庞大,学术界一般以M来表示,1 M表示模型有100万个参数。 |
表2 Massachusetts建筑物检测数据集定量评估结果Tab. 2 Quantitative evaluation results of Massachusetts building detection dataset |
| 提取方法 | 评价指标 | 参数量 | ||||
|---|---|---|---|---|---|---|
| IoU/% | Pre/% | Rec/% | F1/% | 95%HD | Params/M | |
| UNet | 68.43 | 79.99 | 80.84 | 80.47 | 319.00 | 17.26 |
| PSPNet | 68.75 | 80.12 | 81.72 | 80.65 | 331.05 | 53.58 |
| DeeplabV3+ | 67.38 | 78.44 | 81.75 | 73.47 | 315.32 | 15.31 |
| MAPNet | 71.51 | 86.84 | 80.2 | 83.39 | 290.03 | 24.00 |
| DR-Net | 66.05 | 80.77 | 83.12 | 79.50 | 343.44 | 10.00 |
| MBR-HRNet | 70.97 | 86.4 | 80.85 | 83.53 | 267.52 | 31.02 |
| CFENet | 68.02 | 79.35 | 82.68 | 80.97 | 289.68 | 171.00 |
| SDSNet | 71.60 | 86.42 | 80.70 | 83.49 | 280.21 | 65.14 |
| HDNet | 72.48 | 86.95 | 81.26 | 83.91 | 271.52 | 13.89 |
| DFFNet | 72.64 | 87.22 | 81.36 | 84.17 | 267.51 | 32.15 |
| BuildFormer | 75.54 | 87.52 | 84.91 | 86.19 | 253.40 | 40.52 |
| UANet | 76.41 | 85.35 | 87.94 | 86.63 | 219.10 | 38.15 |
| 本文方法 | 77.13 | 87.71 | 86.42 | 87.06 | 205.26 | 28.50 |
注:加粗数值表示定量对比实验中最优评价指标。95%HD是95%的豪斯多夫距离,数值表示2个点集的相似程度,数值越大表示差异越大,反之越小,无具体单位。Params是模型参数量,因语义分割模型参数量庞大,学术界一般以M来表示,1 M表示模型有100万个参数。 |
表3 消融实验定量分析Tab. 3 Quantitative analysis of ablation experiment (%) |
| 方法 | 评价指标 | |||
|---|---|---|---|---|
| IoU | Pre | Rec | F1 | |
| Baseline | 84.15 | 90.72 | 92.41 | 91.24 |
| Baseline+A | 85.74 | 92.33 | 92.54 | 92.40 |
| Baseline+A+I | 88.26 | 93.48 | 93.76 | 93.62 |
| Baseline+A+I+L | 91.75 | 95.32 | 95.52 | 95.42 |
| Baseline+A+I+L+C | 92.94 | 96.37 | 96.33 | 96.35 |
注:A、I、L和C分别代表ASPP模块、IDRM模块、LMSE模块和CGFF模块。 |
| [1] |
王俊, 秦其明, 叶昕, 等. 高分辨率光学遥感图像建筑物提取研究进展[J]. 遥感技术与应用, 2016, 31(4):653-662,701.
[
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
马梁, 苟于涛, 雷涛, 等. 基于多尺度特征融合的遥感图像小目标检测[J]. 光电工程, 2022, 49(4):210363.
[
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
杨明旺, 赵丽科, 叶林峰, 等. 基于卷积神经网络的遥感影像建筑物提取方法综述[J]. 地球信息科学学报, 2024, 26(6):1500-1516.
[
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
于明洋, 陈肖娴, 张文焯, 等. 融合网格注意力阀门和特征金字塔结构的高分辨率遥感影像建筑物提取[J]. 地球信息科学学报, 2022, 24(9):1785-1802.
[
|
| [22] |
吴锋振, 杨德宏, 李俊, 等. 非对称卷积金字塔残差网络的遥感影像建筑物提取[J]. 遥感技术与应用, 2023, 38(6):1467-1476.
[
|
| [23] |
苏步宇, 杜小平, 慕号伟, 等. 耦合Mask R-CNN和注意力机制的建筑物提取及后处理策略[J]. 遥感技术与应用, 2024, 39(3):620-632.
[
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
/
| 〈 |
|
〉 |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}