
大语言模型空间认知能力测试标准研究
注:本文为中国人工智能学会第九届全国大数据与社会计算学术会议(CAAI BDSC 2024)专题论文。
作者贡献:Author Contributions
吴若玲完成实验设计与实验,吴若玲和郭旦怀负责论文的写作和修改。所有作者均阅读并同意最终稿件的提交。
The experimental design and operation were completed by WU Ruoling. The manuscript was drafted and revised by WU Ruoling and GUO Danhuai. All authors read and approved the final manuscript for submission.
SRT4LLM代码及测试用例见:https://github.com/LLING000/SRT4LLM
|
吴若玲(2001— ),女,北京人,硕士生,主要从事地理大模型研究。E-mail: ling010511@163.com |
收稿日期: 2024-12-17
修回日期: 2025-02-25
网络出版日期: 2025-04-23
基金资助
国家自然科学基金项目(42371476)
中央高校基本科研业务费资助项目(buctrc202132)
Research on Evaluation Standards for Spatial Cognitive Abilities in Large Language Models
Received date: 2024-12-17
Revised date: 2025-02-25
Online published: 2025-04-23
Supported by
National Natural Science Foundation of China(42371476)
Fundamental Research Funds for the Central Universities(buctrc202132)
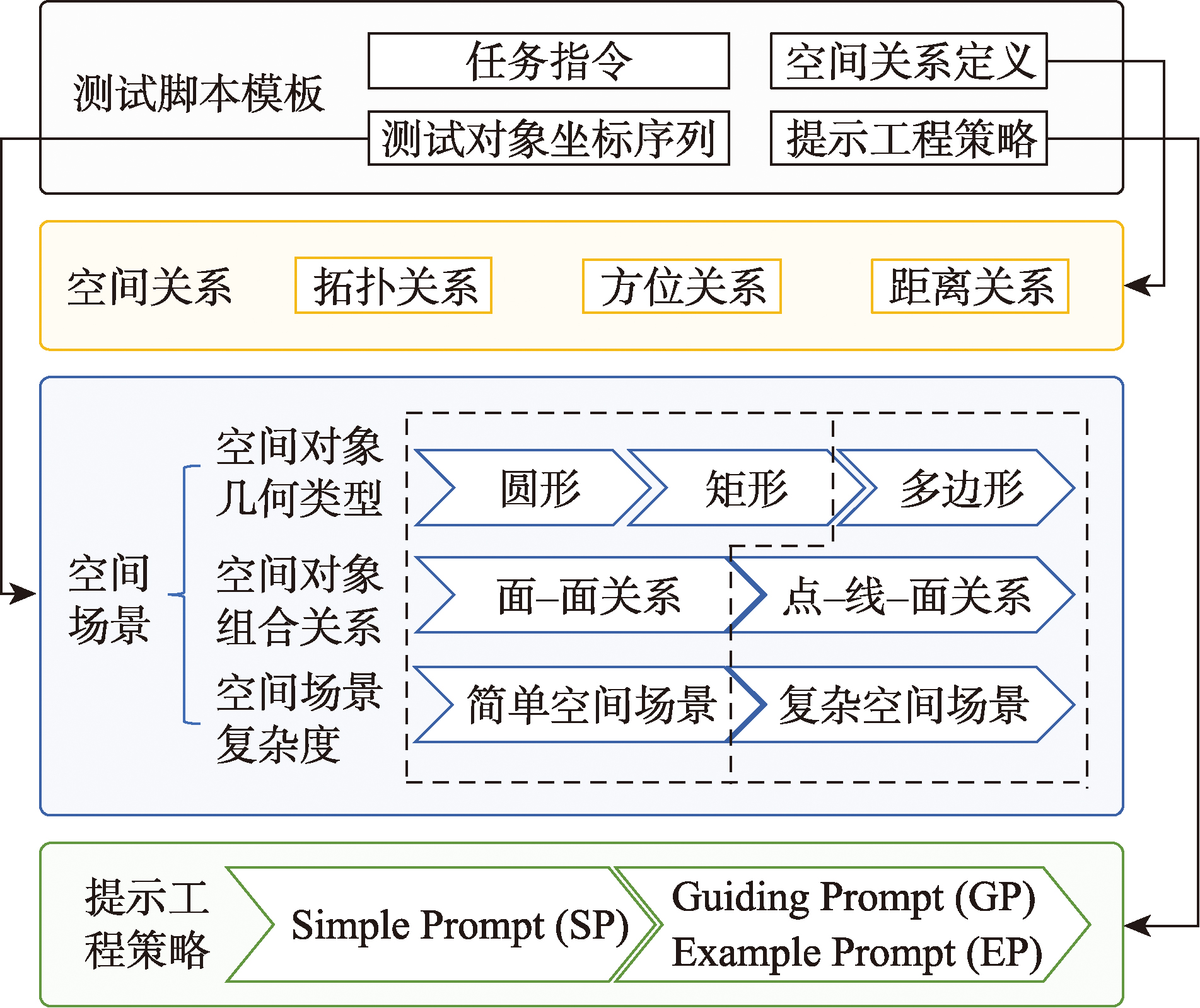
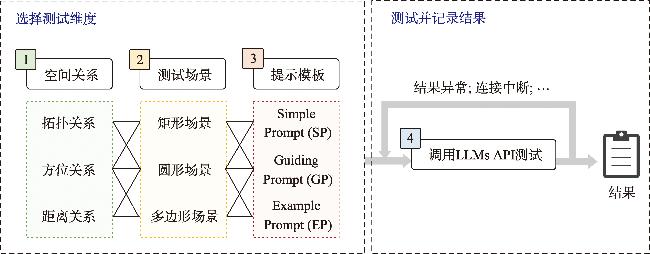
【目的】 大语言模型是否具有空间认知能力及其水平的量化方法,是大模型和地理信息科学研究的重要问题。目前还缺乏大语言模型空间认知能力测评的系统方法和标准。本文在研究现有大语言模型特征的基础上开展大语言模型在空间认知问题上的测试标准研究,最终形成一套具备大语言模型空间认知能力的测试标准框架SRT4LLM和测试流程,用以评估大语言模型的空间认知能力。【方法】 SRT4LLM分别从空间场景中的空间对象类型、空间关系和Prompt策略3个维度研究构建测试体系,包括3种空间对象类型、3种空间关系和3种提示工程策略,并制定标准化测试流程。通过对8个不同参数的大语言模型进行多轮测试,验证SRT4LLM标准的有效性和结果的稳定性,据此标准测试不同大模型在逐次改进的提示工程的得分。【结果】 输入空间对象的几何复杂度影响大语言模型空间认知,不同大模型表现差异较大,但同一大模型得分较为稳定,随着空间对象几何复杂性和空间关系复杂度的增加,大语言模型对3种空间关系的判断准确率最大仅有7.2%的小幅下降,显示本测试标准在不同场景间的较强的适应性。改进的提示工程能够部分改善大语言模型的空间认知问答得分,且不同大模型的改善程度差异较大,本标准具备挖掘大模型空间认知能力的能力。同一大语言模型多轮测试表明测试结果收敛,大模型之间的分值差也较稳定。【结论】 SRT4LLM具备度量大语言模型空间认知能力的能力,可作为大语言模型空间认知能力的评估的标准化工具,可为下一步构建原生的地理大模型提供支持。
吴若玲 , 郭旦怀 . 大语言模型空间认知能力测试标准研究[J]. 地球信息科学学报, 2025 , 27(5) : 1041 -1052 . DOI: 10.12082/dqxxkx.2025.240694
[Objectives] Understanding whether Large Language Models (LLMs) possess spatial cognitive abilities and how to quantify them are critical research questions in the fields of large language models and geographic information science. However, there is currently a lack of systematic evaluation methods and standards for assessing the spatial cognitive abilities of LLMs. Based on an analysis of existing LLM characteristics, this study develops a comprehensive evaluation standard for spatial cognition in large language models. Ultimately, it establishes a testing standard framework, SRT4LLM, along with standardized testing processes to evaluate and quantify spatial cognition in LLMs. [Methods] The testing standard is constructed along three dimensions: spatial object types, spatial relations, and prompt engineering strategies in spatial scenarios. It includes three types of spatial objects, three categories of spatial relations, and three prompt engineering strategies, all integrated into a standardized testing process. The effectiveness of the SRT4LLM standard and the stability of the results are verified through multiple rounds of testing on eight large language models with different parameter scales. Using this standard, the performance scores of different LLMs are evaluated under progressively improved prompt engineering strategies. [Results] The geometric complexity of input spatial objects influences the spatial cognition of LLMs. While different LLMs exhibit significant performance variations, the scores of the same model remain stable. As the geometric complexity of spatial objects and the complexity of spatial relations increase, LLMs' accuracy in judging three spatial relations decreases by only 7.2%, demonstrating the robustness of the test standard across different scenarios. Improved prompt engineering strategies can partially enhance LLM's spatial cognitive Question-Answering (Q&A) performance, with varying degrees of improvement across different models. This verifies the effectiveness of the standard in analyzing LLMs' spatial cognitive abilities. Additionally, Multiple rounds of testing on the same LLM indicate that the results are convergent, and score differences between different LLMs exhibit a stable distribution. [Conclusions] SRT4LLM effectively measures the spatial cognitive abilities of LLMs and serves as a standardized evaluation tool. It can be used to assess LLMs' spatial cognition and support the development of native geographic large models in future research.
| 算法1 Simple Prompt (SP) |
|---|
| 输入:空间对象形状shape; 空间对象坐标coordinate; 空间关系 定义relation 输出:Simple Prompt模板 1. 初始化Simple Prompt模板: Your task is to determine the topological relation between two closed geometrical shapes in the same coordinate system. The eight kinds of topological relations will be delimited with ``` tag. ```{relation}```. The two geometrical shapes are {shape} that will be given their positions by coordinates: {coordinate}. 2. 将具体测试数据的shape、coordinate和 relation分别替换模板 中的占位符{shape}; {coordinate}; {relation} 3. 返回生成的SP提示语 |
| 算法2 Guiding Prompt (GP) |
|---|
| 输入:空间对象形状shape; 空间对象坐标coordinate; 空间关系 定义relation 输出:Guiding Prompt模板 1. 初始化Guiding Prompt模板: Your task is to determine the topological relation between two closed geometrical shapes in the same coordinate system. The eight kinds of topological relations will be delimited with ``` tag. ```{relation}```. The two geometrical shapes are {shape} that will be given their positions by coordinates: {coordinate}. Pay attention to the following points in responding: (1) By specifying the range of x-coordinate and y-coordinate, clearly define the positions of two geometrical shapes in the coordinate system. (2) Two {shape} can only be overlapping if their x-coordinate and y-coordinate overlap at the same time. (3) TPP, NTPP, TPPi, NTPPi and EQ are special cases of PO and should be categorized separately if their definitions are met. If not, categorized as PO. 2. 将具体测试数据的shape、coordinate和relation分别替换模板 中的占位符{shape}; {coordinate}; {relation} 3. 返回生成的GP提示语 |
| 算法3 Example Prompt (EP) |
|---|
| 输入:空间对象形状shape; 空间对象坐标coordinate; 空间关系 定义relation 输出:Example Prompt模板 1. 初始化Example Prompt模板: Your task is to determine the topological relation between two closed geometrical shapes in the same coordinate system. The eight kinds of topological relations will be delimited with ``` tag. ```{relation}```. You will be given two cases to learn how to reason the question out. Case 1 - The two geometrical shapes are {shape} that will be given their position by coordinates: rectangle x: (5, 6), (7, 6), (7, 7), (5, 7), (5, 6); rectangle y: (4, 5), (8, 5), (8, 8), (4, 8), (4,5). Answer 1 - Based on the given coordinate information, the position of the two circles in the coordinate system can be determined: rectangle x: x-coordinate ranges from 5 to 7, y-coordinate ranges from 6 to 7. rectangle y: x-coordinate ranges from 4 to 8, y-coordinate ranges from 5 to 8. |
| Next, reason about the topological relation between two rectangles: (1). The two rectangles overlap in both the x and y coordinate ranges, so it is not DC(x, y) or EC(x, y). (2). Rectangle x's x and y coordinates are both completely contained in rectangle y, so they are not partially overlapping or identical. It is a TPP(x, y) or NTPP(x, y) relation. (3). Rectangle x and rectangle y are not tangent, so it is a NTPP(x, y) relationship. Therefore, it is concluded that the two rectangles are NTPP(x, y). Case 2 - The two geometrical shapes are {shape} that will be given their position by coordinates: rectangle x: (1, 2), (3, 2), (3, 5), (1, 5), (1, 2); rectangle y: (3, 3), (5, 3), (5, 4), (3, 4), (3, 3). Answer 2 - Based on the given coordinate information, the position of the two rectangles in the coordinate system can be determined: rectangle x: x-coordinate ranges from 1 to 3, y-coordinate ranges from 2 to 5. rectangle y: x coordinate ranges from 3 to 5, y coordinate ranges from 3 to 4. Next, reason about the topological relation between two rectangles: (1). The y-coordinate ranges of the two rectangles overlap, but the x-coordinate ranges do not, so it is DC(x, y) or EC(x, y), not the others. (2). The x-coordinate ranges of the two rectangles do not overlap, but are connected, indicating that the two rectangles are externally connected, so it is EC(x, y). Therefore, it is concluded that the two rectangles are EC(x, y). Question - The two geometrical shapes are {shape} that will be given their position by coordinates: {coordinate}. 2. 将具体测试数据的shape、coordinate和relation分别替换模板 中的占位符{shape}; {coordinate}; {relation} 3. 返回生成的EP提示语 |
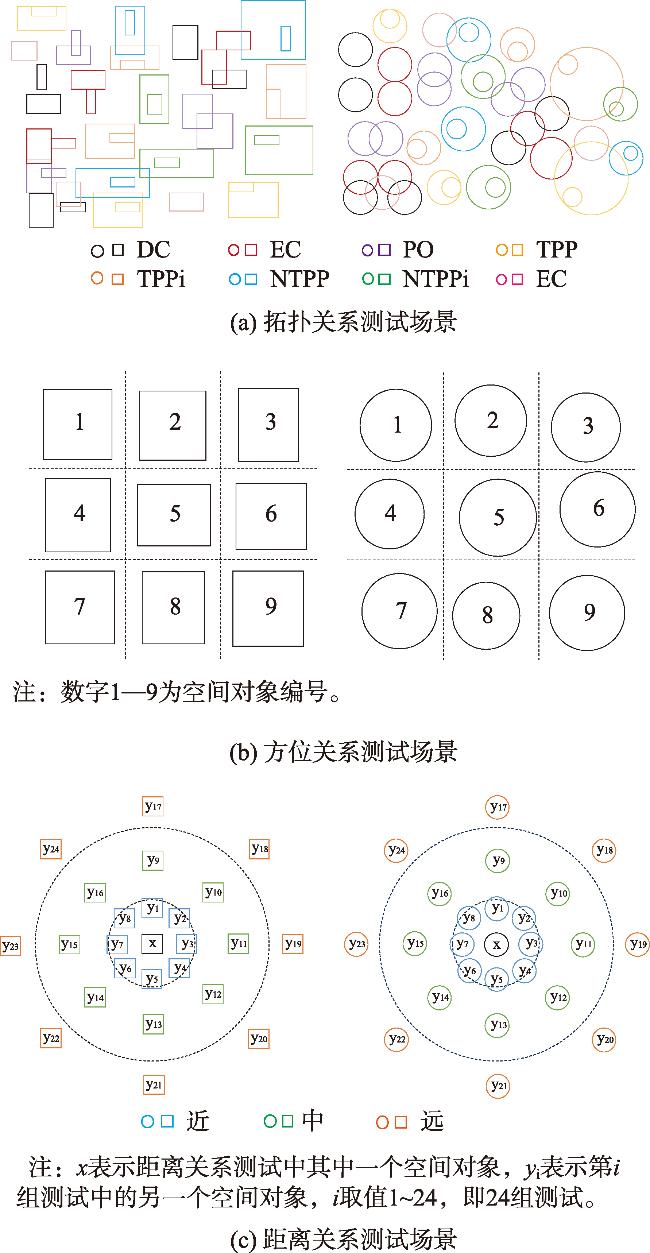
表1 SRT4LM 3种基础空间关系的定义Tab. 1 Definitions of three spatial relations in SRT4LLM |
| 空间关系 | SRT4LLM对空间关系的定义 |
|---|---|
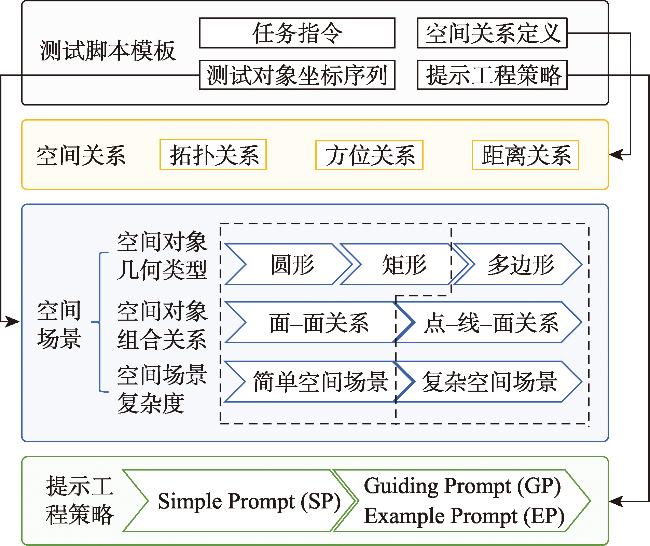
| 拓扑关系 | (1) DC(x, y): x is disconnected from y. (2) EC(x, y): x is externally connected to y without any overlap. (3) PO(x, y): x partially overlaps y, with neither being a part of the other. (4) TPP(x, y): x is a tangential proper part of y. (5) NTPP(x, y): x is a nontangential proper part of y. (6) TPPi(x, y): y is a tangential proper part of x. (7) NTPPi(x, y): y is a nontangential proper part of x. (8) EQ(x, y): x is identical with y. |
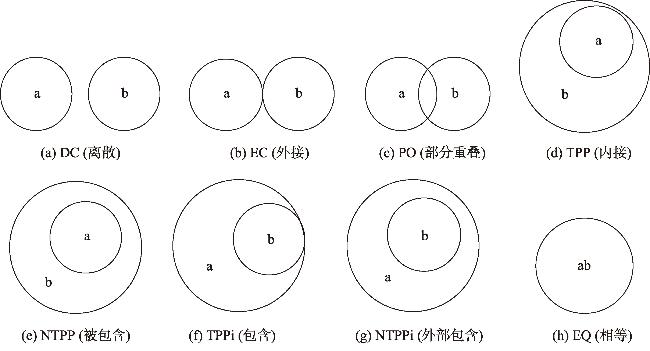
| 方位关系 | (1) Up(x, y): y is roughly above x. (2) Down(x, y): y is roughly below x. (3) Left(x, y): y is roughly to the left of x. (4) Right(x, y): y is roughly to the right of x. (5) Upper Left(x, y): y is roughly to the upper left of x. (6) Lower Left(x, y): y is roughly to the lower left of x. (7) Upper Right(x, y): y is roughly to the upper right of x. (8) Lower Right(x, y): y is roughly to the lower right of x. |
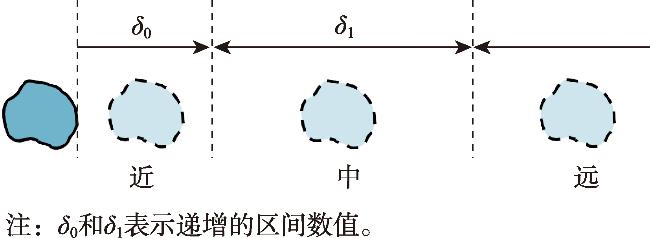
| 距离关系 | Qualitatively describe the relation by delimiting the distance range. (1) Close(x, y): The length of the distance from x to y is [0, δ0]. (2) Medium(x, y): The length of the distance from x to y is (δ0, δ0+δ1]. (3) Far(x, y): The length of the distance from x to y is (δ0+δ1, +∞). |
表2 测试大模型Tab. 2 Tested large language models |
| 大模型名称及版本 | 发布机构 | 发布时间 | 测试版本号 |
|---|---|---|---|
| ChatGLM3 | 智谱AI | 2023年10月27日 | ChatGLM3-6B |
| ERNIE Bot | 百度 | 2023年3月16日 | ERNIE-Bot-turbo-0922 |
| Gemini | 2023年12月6日 | gemini-pro | |
| GPT-3.5 | OpenAI | 2022年11月30日 | gpt-3.5-turbo |
| GPT-4 | OpenAI | 2023年3月15日 | gpt-4-0125-preview |
| LLaMa2 | Meta AI | 2023年7月19日 | LLaMa2-13B-chat |
| QWEN | 阿里云 | 2023年3月16日 | qwen-max |
| SparkDesk | 科大讯飞 | 2023年5月6日 | sparkv3.5 |
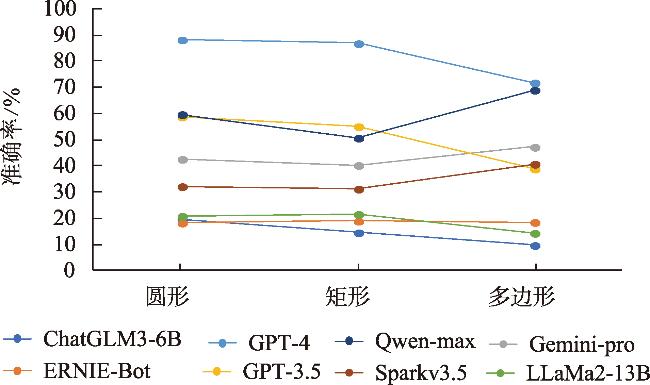
表3 3种空间场景上的测试准确率Tab. 3 Accuracy on three spatial scenes (%) |
| 大模型 | 拓扑关系 | 方位关系 | 距离关系 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 圆形 | 矩形 | 多边形 | 圆形 | 矩形 | 多边形 | 圆形 | 矩形 | 多边形 | |||
| ChatGLM3-6B | 22.2 | 13.9 | 4.2 | 11.8 | 11.8 | 13.9 | 25.0 | 18.0 | 11.1 | ||
| ERNIE-Bot | 9.7 | 16.0 | 8.3 | 10.4 | 10.4 | 18.1 | 34.8 | 30.6 | 29.2 | ||
| Gemini-pro | 38.2 | 25.0 | 45.8 | 38.2 | 37.5 | 40.3 | 51.4 | 58.3 | 55.6 | ||
| GPT-3.5 | 40.3 | 27.8 | 29.2 | 54.2 | 52.1 | 41.7 | 81.9 | 85.4 | 45.8 | ||
| GPT-4 | 78.5 | 72.9 | 63.9 | 87.5 | 95.1 | 72.2 | 98.6 | 92.4 | 79.2 | ||
| LLaMa2-13B | 22.9 | 14.6 | 11.1 | 14.6 | 18.1 | 15.3 | 25.0 | 32.0 | 16.7 | ||
| Qwen-max | 47.2 | 29.2 | 54.2 | 55.5 | 60.4 | 68.1 | 76.4 | 62.5 | 84.7 | ||
| Sparkv3.5 | 27.1 | 29.9 | 44.4 | 38.2 | 31.9 | 27.8 | 31.3 | 32.0 | 50.0 | ||
| 平均值 | 35.8 | 28.6 | 32.6 | 38.8 | 39.7 | 37.2 | 53.0 | 51.4 | 46.5 | ||
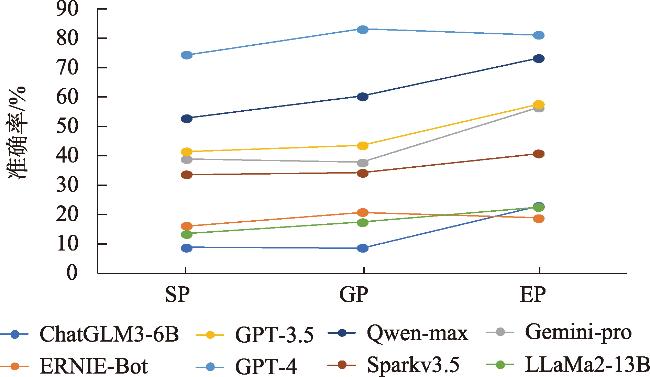
表4 Simple Prompt (SP)、Guiding Prompt (GP)和Example Prompt (EP)策略下的大模型空间认知准确率Tab. 4 Spatial cognitive accuracy of large language models using Simple Prompt (SP), Guiding Prompt (GP), and Example Prompt (EP) (%) |
| 大模型 | 拓扑关系 | 方位关系 | 距离关系 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| SP | GP | EP | SP | GP | EP | SP | GP | EP | |||
| ChatGLM3-6B | 12.0 | 11.5 | 9.9 | 12.0 | 10.4 | 16.1 | 2.1 | 4.2 | 42.7 | ||
| ERNIE-Bot | 8.3 | 13.5 | 9.9 | 14.6 | 11.5 | 16.7 | 25.5 | 37.5 | 29.7 | ||
| Gemini-pro | 36.5 | 36.0 | 43.7 | 26.0 | 33.9 | 57.3 | 54.2 | 43.2 | 68.2 | ||
| GPT-3.5 | 27.1 | 27.6 | 40.1 | 36.5 | 40.6 | 62.0 | 60.9 | 62.5 | 70.9 | ||
| GPT-4 | 63.6 | 72.4 | 73.4 | 73.4 | 87.5 | 84.4 | 86.5 | 89.6 | 85.9 | ||
| LLaMa2-13B | 12.0 | 16.2 | 16.7 | 13.0 | 15.6 | 18.7 | 15.1 | 20.3 | 32.3 | ||
| Qwen-max | 40.1 | 45.3 | 53.1 | 50.5 | 63.6 | 75.0 | 67.7 | 71.9 | 91.7 | ||
| Sparkv3.5 | 37.0 | 35.9 | 36.5 | 21.9 | 23.4 | 49.0 | 42.2 | 43.3 | 37.0 | ||
| 平均值 | 29.6 | 32.3 | 35.4 | 31.0 | 35.8 | 47.4 | 44.3 | 46.6 | 57.3 | ||
注: 3类空间关系中3种Prompt的准确率最高得分用粗体标注,优化后准确率下降的加注下划线。 |
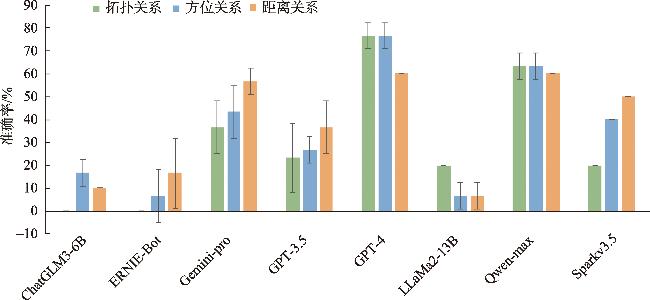
表5 多轮测试结果得分Tab. 5 The result scores of multiple rounds of testing |
| 大模型 | 拓扑关系 | 方位关系 | 距离关系 | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 第一轮 | 第二轮 | 第三轮 | 平均值 | 标准差 | 第一轮 | 第二轮 | 第三轮 | 平均值 | 标准差 | 第一轮 | 第二轮 | 第三轮 | 平均值 | 标准差 | |||
| ChatGLM3-6B | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 20.0 | 10.0 | 20.0 | 16.7 | 5.8 | 10.0 | 10.0 | 10.0 | 10.0 | 0.0 | ||
| ERNIE-Bot | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 20.0 | 6.7 | 11.5 | 30.0 | 0.0 | 20.0 | 16.7 | 15.3 | ||
| Gemini-pro | 30.0 | 30.0 | 50.0 | 36.7 | 11.5 | 50.0 | 30.0 | 50.0 | 43.3 | 11.5 | 50.0 | 60.0 | 60.0 | 56.7 | 5.8 | ||
| GPT-3.5 | 20.0 | 40.0 | 10.0 | 23.3 | 15.3 | 30.0 | 30.0 | 20.0 | 26.7 | 5.8 | 30.0 | 50.0 | 30.0 | 36.7 | 11.5 | ||
| GPT-4 | 80.0 | 70.0 | 80.0 | 76.7 | 5.8 | 80.0 | 70.0 | 80.0 | 76.7 | 5.8 | 60.0 | 60.0 | 60.0 | 60.0 | 0.0 | ||
| LLaMa2-13B | 20.0 | 20.0 | 20.0 | 20.0 | 0.0 | 10.0 | 0.0 | 10.0 | 6.7 | 5.8 | 10.0 | 0.0 | 10.0 | 6.7 | 5.8 | ||
| Qwen-max | 60.0 | 60.0 | 70.0 | 63.3 | 5.8 | 70.0 | 60.0 | 60.0 | 63.3 | 5.8 | 60.0 | 60.0 | 60.0 | 60.0 | 0.0 | ||
| Sparkv3.5 | 20.0 | 20.0 | 20.0 | 20.0 | 0.0 | 40.0 | 40.0 | 40.0 | 40.0 | 0.0 | 50.0 | 50.0 | 50.0 | 50.0 | 0.0 | ||
利益冲突: Conflicts of Interest 所有作者声明不存在利益冲突。
All authors disclose no relevant conflicts of interest.
| [1] |
|
| [2] |
陈炫婷, 叶俊杰, 祖璨, 等. GPT系列大语言模型在自然语言处理任务中的鲁棒性[J]. 计算机研究与发展, 2024, 61(5):1128-1142.
[
|
| [3] |
|
| [4] |
陈露, 张思拓, 俞凯. 跨模态语言大模型:进展及展望[J]. 中国科学基金, 2023, 37(5):776-785.
[
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
郭旦怀. 基于空间场景相似性的地理空间分析[M]. 北京: 科学出版社, 2016.
[
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}