
混合特征与多尺度融合的光学小目标检测算法
作者贡献:Author Contributions
史世豪和施群山参与实验设计;史世豪、齐凯参与实验操作;史世豪、周杨、胡校飞参与论文的写作与修改。所有作者均阅读并同意最终稿件的提交。
The study was designed by SHI Shihao and SHI Qunshan. SHI Shihao and QI Kai conducted the experiments; SHI Shihao, ZHOU Yang and HU Xiaofei contributed to the writing and revision of the manuscript. All authors have read and approved the final manuscript.
|
史世豪(1999— ),男,河南开封人,硕士生,主要从事摄影测量与遥感、目标检测跟踪等研究。E-mail: syw15690860529@163.com |
收稿日期: 2025-01-06
修回日期: 2025-04-22
网络出版日期: 2025-07-07
基金资助
国家自然科学基金(42001338)
河南省自然科学基金项目(202300410536)
智慧中原地理信息技术河南省协同创新中心和时空感知与智能处理自然资源部重点实验室基金项目(212108)
An Optical Small Object Detection Algorithm Using Hybrid Features and Multi-Scale Fusion
Received date: 2025-01-06
Revised date: 2025-04-22
Online published: 2025-07-07
Supported by
National Natural Science Foundation of China(42001338)
Natural Science Foundation of Henan province(202300410536)
Joint Fund of Collaborative Innovation Center of Geo-Information Technology for Smart Central Plains, Henan Province and Key Laboratory of Spatiotemporal Perception and Intelligent processing, Ministry of Natural Resources(212108)
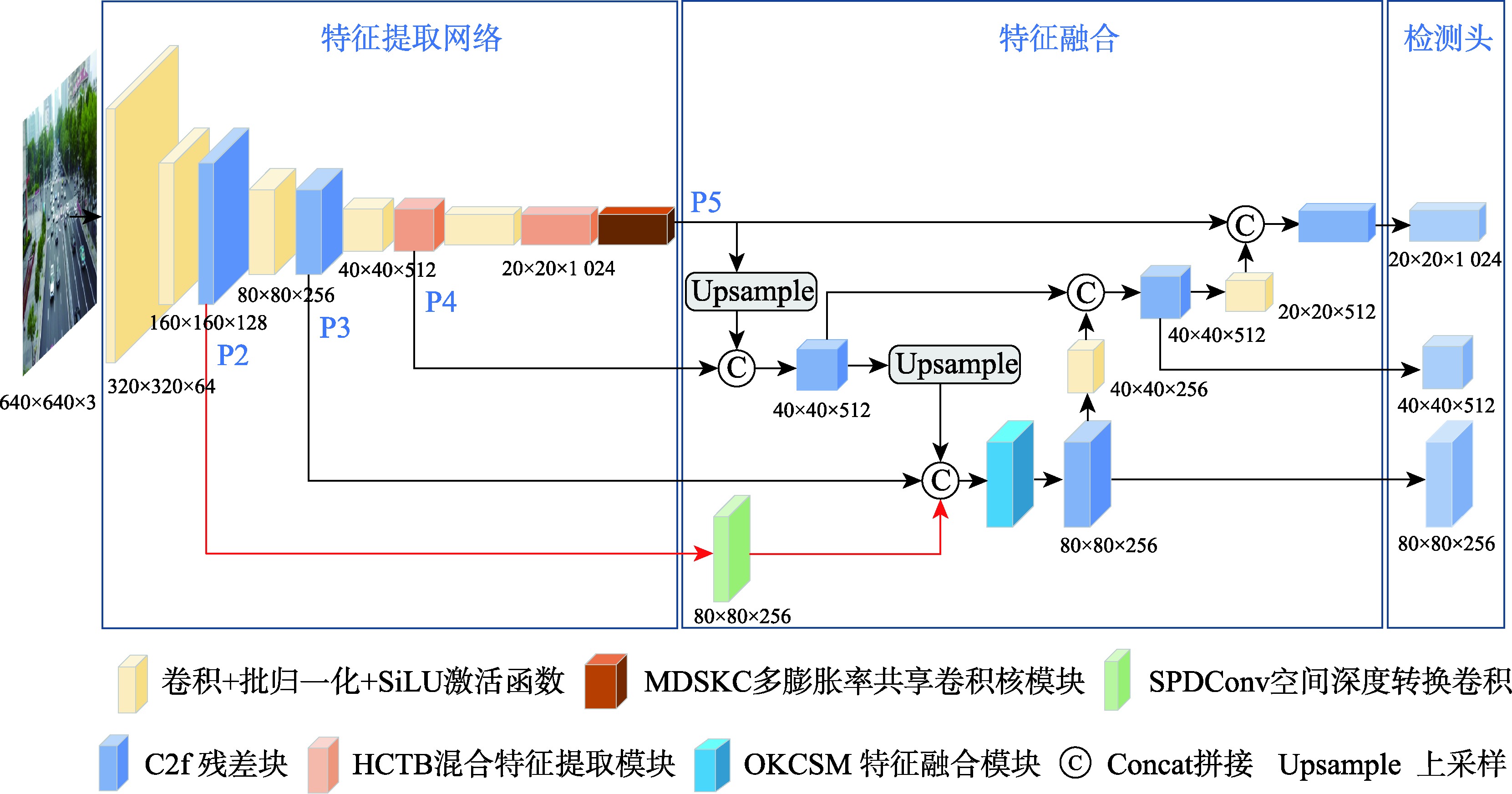
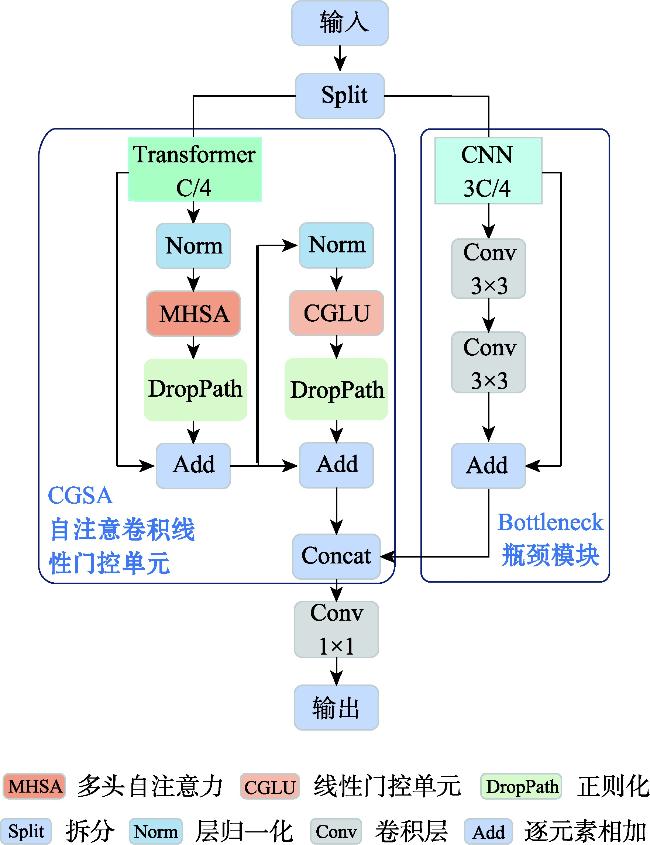
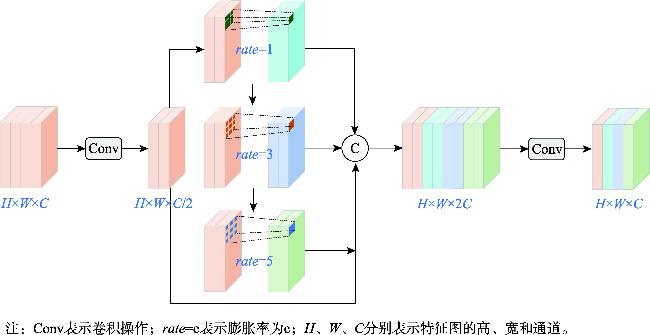
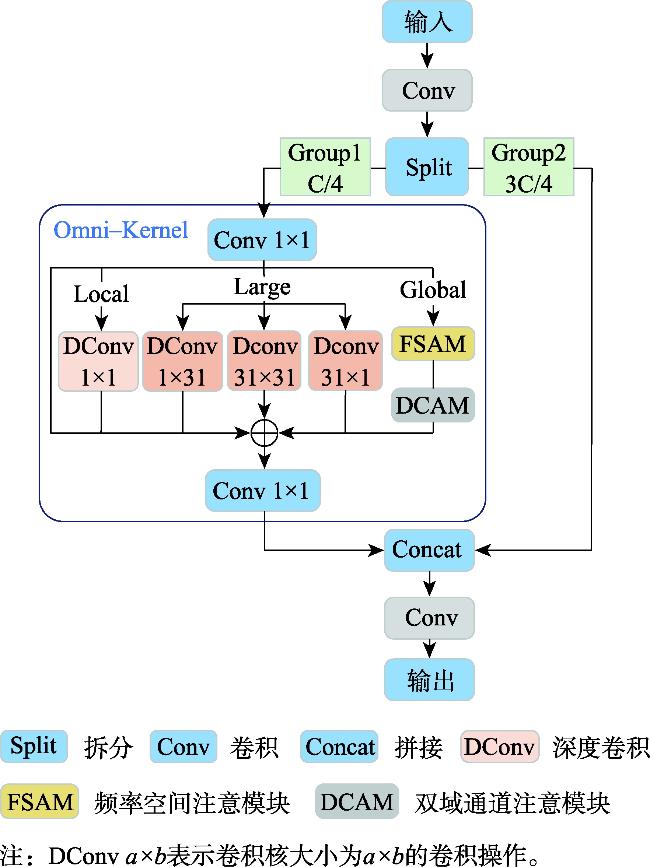
【目的】小目标检测在军事和民用领域具有重要意义,但由于低分辨率、高噪声环境、目标遮挡及背景复杂等因素的影响,传统检测方法在精度和鲁棒性上难以满足实际需求,复杂场景下的小目标检测问题仍极具挑战性。因此,本文提出一种混合特征与多尺度融合的小目标检测算法。【方法】首先,本文设计了一种混合特征提取模块(Hybrid Conv and Transformer Block, HCTB),充分利用局部和全局上下文信息来增强网络对小目标感知,优化了计算效率和特征提取能力;其次,提出了多膨胀率共享卷积核模块(Multi-Dilated Shared Kernel Conv, MDSKC),通过不同膨胀率的空洞卷积扩展主干的感受野,高效提取多尺度特征;最后,结合基于Omni-Kernel和Cross Stage Partial思想构建的全核跨阶段特征融合模块(Omni-Kernel Cross Stage Model, OKCSM),优化了小目标特征金字塔网络,更大程度上保留小目标的信息,提高了检测性能。【结果】本文在 VisDrone2019和TinyPerson数据集上进行了消融实验和对比实验,结果表明:本文方法相较于基线模型yolov8n,在查准率、召回率、mAP50、mAP50:95上分别提升为1.3%、3.1%、3%、1.9%和3.6%、1.3%、2.1%、0.7%,且模型尺寸和GFLOPs仅为6.3 MB和11.3 G;此外,在与HIC-Yolov5、TPH-yolov5、Drone-YOLO等经典算法的对比实验中,本文提出的算法显示出明显的优势,优于其他对比方法。【结论】本文算法有效提升了检测精度,证明了本文算法面对复杂场景中小目标检测问题方面具有良好的检测性能。
史世豪 , 施群山 , 周杨 , 胡校飞 , 齐凯 . 混合特征与多尺度融合的光学小目标检测算法[J]. 地球信息科学学报, 2025 , 27(7) : 1596 -1607 . DOI: 10.12082/dqxxkx.2025.250015
[Objectives] Small object detection is of great significance in both military and civil applications. However, due to challenges such as low resolution, high noise environments, target occlusion, and complex backgrounds, traditional detection methods often struggle to achieve the necessary accuracy and robustness. The problem of detecting small objects in complex scenes remains highly challenging. Therefore, this paper proposes a hybrid feature and multi-scale fusion algorithm for small object detection. [Methods] First, a Hybrid Conv and Transformer Block (HCTB) is designed to fully utilize local and global context information, enhancing the network's perception of small objects while optimizing computational efficiency and feature extraction capability. Second, a Multi-Dilated Shared Kernel Conv (MDSKC) module is introduced to extend the receptive field of the backbone network using dilated convolutions with varying expansion rates, thereby enabling efficient multi-scale feature extraction. Finally, the Omni-Kernel Cross Stage Model (OKCSM), constructed based on the concepts of Omni-Kernel and Cross Stage Partial, is integrated to optimize the small target feature pyramid network. This approach helps preserve small object information and significantly improves detection performance. [Results] Ablation and comparison experiments were conducted on the VisDrone2019 and TinyPerson datasets. Compared to the baseline model YOLOv8n, the proposed method improves precision, recall, mAP@50, and mAP@50:95 by 1.3%, 3.1%, 3%, and 1.9%, respectively on VisDrone2019, and by 3.6%, 1.3%, 2.1%, and 0.7%, respectively on TinyPerson. Additionally, the model size and GFLOPs are only 6.3 MB and 11.3 G, demonstrating its efficiency. Furthermore, compared with classical algorithms, such as HIC-YOLOv5, TPH- YOLOv5, and Drone-YOLO, the proposed algorithm demonstrates significant advantages and superior performance. [Conclusions] The algorithm effectively improves detection accuracy, confirming its strong performance in addressing small object detection in complex scenes.
表1 算法各模块在VisDrone2019数据集上检测精度的评估结果Tab. 1 Evaluation results of the detection accuracy of each module of the algorithm on the VisDrone2019 dataset |
| 模块 | P/% | R/% | mAP50/% | mAP50:95/% | Model Size/MB | Params/M |
|---|---|---|---|---|---|---|
| yolov8n | 56.2 | 43.0 | 45.7 | 28.2 | 6.3 | 3.2 |
| yolov8n+HCTB | 55.8 | 44.2 | 46.2 | 28.5 | 5.5 | 2.7 |
| yolov8n+HCTB+OKCSM | 58.2 | 45.2 | 48.2 | 29.7 | 6.1 | 3.0 |
| yolov8n+HCTB+OKCSM+ MDSKC(本文算法 ) | 57.5 | 46.1 | 48.7 | 30.1 | 6.3 | 3.1 |
注:加粗数值表示本文最终算法的实验结果。 |
表2 算法各模块在TinyPerson数据集上检测精度的评估结果Tab. 2 Evaluation results of detection accuracy of each module of the algorithm on the TinyPerson dataset |
| 模块 | P/% | R/% | mAP50/% | mAP50:95/% | Model Size/MB | Params/M |
|---|---|---|---|---|---|---|
| yolov8n | 51.5 | 35.6 | 36.3 | 15.7 | 6.3 | 3.2 |
| yolov8n+HCTB | 53.6 | 35.9 | 36.6 | 16.0 | 5.5 | 2.7 |
| yolov8n+HCTB+OKCSM | 53.7 | 36.4 | 37.0 | 15.8 | 6.1 | 3.0 |
| yolov8n+HCTB+OKCSM+ MDSKC(本文算法 ) | 55.1 | 36.9 | 38.4 | 16.4 | 6.3 | 3.1 |
注:加粗数值表示本文最终算法的实验结果。 |
表3 VisDrone2019数据集各模型对比结果Tab. 3 Comparison results of various models in VisDrone2019 dataset |
| 模型 | P/% | R/% | mAP50/% | mAP50:95/% | Model Size/MB | GFLOPs |
|---|---|---|---|---|---|---|
| Yolov3-tiny | 46.3 | 34.8 | 34.9 | 20.4 | 19.2 | 14.3 |
| Yolv5s | 56.9 | 45.0 | 46.8 | 28.1 | 14.6 | 16.0 |
| Yolov6n | 49.1 | 39.6 | 40.4 | 28.1 | 8.6 | 11.5 |
| Yolov7-tiny | 56.7 | 47.8 | 47.3 | 27.0 | 12.4 | 13.3 |
| HIC-Yolov5n | 51.0 | 43.5 | 43.5 | 25.2 | 6.6 | 8.2 |
| TPH-yolov5s | 55.9 | 47.2 | 48.5 | 29.1 | 19.4 | 23.4 |
| Drone-YOLO | 54.3 | 43.7 | 45.1 | 27.7 | 6.5 | 12.6 |
| 本文算法 | 57.5 | 46.1 | 48.7 | 30.1 | 6.3 | 11.3 |
注:加粗数值表示本文算法的实验结果。 |
表4 TinyPerson数据集各模型对比结果Tab. 4 Comparison results of various models in TinyPerson dataset |
| 模型 | P/% | R/% | mAP50/% | mAP50:95/% | Model Size/MB | GFLOPs |
|---|---|---|---|---|---|---|
| Yolov3-tiny | 41.9 | 21.8 | 20.7 | 7.15 | 19.2 | 14.3 |
| Yolv5s | 52.6 | 35.6 | 36.1 | 15.6 | 14.6 | 16.0 |
| Yolov6n | 46.2 | 30.3 | 28.5 | 11.7 | 8.6 | 11.5 |
| Yolov7-tiny | 57.0 | 34.9 | 33.5 | 12.1 | 12.4 | 13.3 |
| HIC-Yolov5n | 52.0 | 38.5 | 36.9 | 14.1 | 6.6 | 8.2 |
| TPH-plus | 55.1 | 35.9 | 35.7 | 14.0 | 14.3 | 30.1 |
| Drone-YOLO | 52.5 | 37.2 | 36.6 | 16.0 | 6.5 | 12.5 |
| 本文算法 | 55.1 | 36.9 | 38.4 | 16.4 | 6.3 | 11.3 |
注:加粗数值表示本文算法的实验结果。 |
利益冲突:Conflicts of Interest 所有作者声明不存在利益冲突。
All authors disclose no relevant conflicts of interest.
| [1] |
胡惠娟, 秦一锋, 徐鹤, 等. 面向无人机航拍图像的YOLOv8目标检测改进算法[J]. 计算机科学, 2025, 52(4):202-211.
[
|
| [2] |
|
| [3] |
潘玮, 韦超, 钱春雨, 等. 面向无人机视角下小目标检测的YOLOv8s改进模型[J]. 计算机工程与应用, 2024, 60(9):142-150.
[
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
董一兵, 曾辉, 侯少杰. LMUAV-YOLOv8:低空无人机视觉目标检测轻量化网络[J]. 计算机工程与应用, 2025, 61(3):94-110.
[
|
| [11] |
梁燕, 何孝武, 邵凯, 等. 改进YOLOv8的无人机航拍图像目标检测算法[J]. 计算机工程与应用, 2025, 61(1):121-130.
[
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}