
CATrans:基于跨尺度注意力Transformer的高分辨率遥感影像土地覆盖语义分割框架
作者贡献:Author Contributions
陈丽佳和陈宏辉参与实验设计;陈丽佳、陈宏辉、谢艳秋、何天友、叶菁完成实验操作;陈丽佳、陈宏辉、谢艳秋、吴林煌参与论文的写作和修改。所有作者均阅读并同意最终稿件的提交。
The study was designed by CHEN Lijia and CHEN Honghui. The experimental operation was completed by CHEN Lijia, CHEN Honghui, XIE Yanqiu, HE Tianyou, and YE Jing. The manuscript was drafted and revised by CHEN Lijia and CHEN Honghui, XIE Yanqiu, and WU Linhuang. All the authors have read the last version of paper and consented for submission.
|
陈丽佳(1990— ),女,福建福州人,博士生,主要从事风景园林、遥感信息分析研究。E-mail: 2211775005@fafu.edu.cn |
收稿日期: 2025-02-26
修回日期: 2025-05-06
网络出版日期: 2025-07-07
基金资助
国家自然科学基金项目(62171135)
福建省重大产学研专项(2023XQ004)
CATrans: A Cross-Scale Attention Transformer for Land Cover Semantic Segmentation in High-Resolution Remote Sensing Images
Received date: 2025-02-26
Revised date: 2025-05-06
Online published: 2025-07-07
Supported by
National Natural Science Foundation of China(62171135)
Fujian Province Key Industry-University Project(2023XQ004)
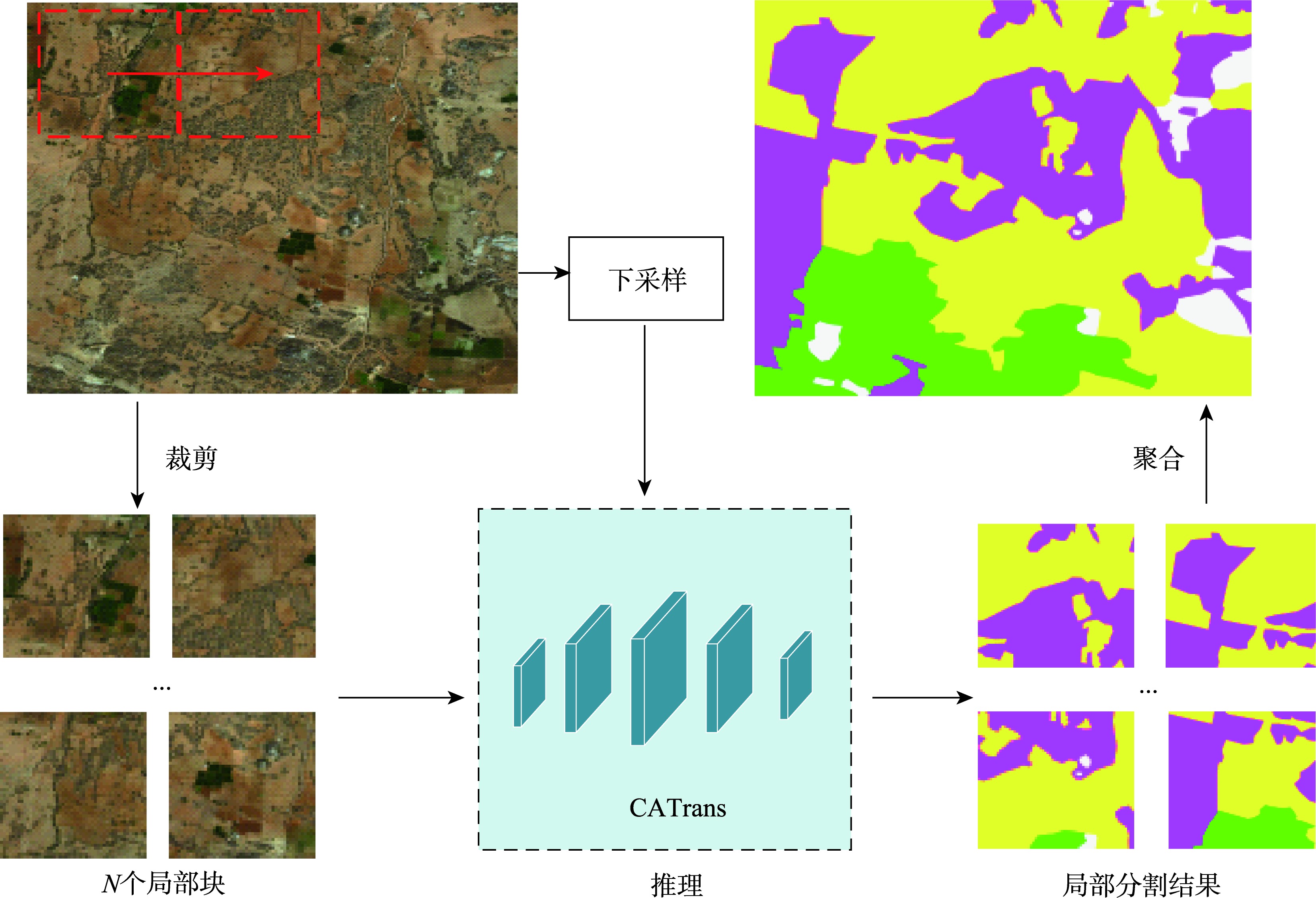
【目的】高分辨率遥感影像语义分割通过精准提取地物信息,为城市规划、土地分析利用提供了重要的数据支持。当前分割方法通常将遥感影像划分为标准块,进行多尺度局部分割和层次推理,未充分考虑影像中的上下文先验知识和局部特征交互能力,影响了推理分割质量。【方法】为了解决这一问题,本文提出了一种联合跨尺度注意力和语义视觉Transformer的遥感影像分割框架(Cross-scale Attention Transformer, CATrans),融合跨尺度注意力模块和语义视觉Transformer,提取上下文先验知识增强局部特征表示和分割性能。首先,跨尺度注意力模块通过空间和通道两个维度进行并行特征处理,分析浅层-深层和局部-全局特征之间的依赖关系,提升对遥感影像中不同粒度对象的注意力。其次,语义视觉Transformer通过空间注意力机制捕捉上下文语义信息,建模语义信息之间的依赖关系。【结果】本文在DeepGlobe、Inria Aerial和LoveDA数据集上进行对比实验,结果表明:CATrans的分割性能优于现有的WSDNet(Discrete Wavelet Smooth Network)和ISDNet(Integrating Shallow and Deep Network)等分割算法,分别取得了76.2%、79.2%、54.2%的平均交并比(Mean Intersection over Union, mIoU)和86.5%、87.8%、66.8%的平均F1得分(Mean F1 Score, mF1),推理速度分别达到38.1 FPS、13.2 FPS和95.22 FPS。相较于本文所对比的最佳方法WSDNet, mIoU和mF1在3个数据集中分别提升2.1%、4.0%、5.3%和1.3%、1.8%、5.6%,在每类地物的分割中都具有显著优势。【结论】本方法实现了高效率、高精度的高分辨率遥感影像语义分割。
陈丽佳 , 陈宏辉 , 谢艳秋 , 何天友 , 叶菁 , 吴林煌 . CATrans:基于跨尺度注意力Transformer的高分辨率遥感影像土地覆盖语义分割框架[J]. 地球信息科学学报, 2025 , 27(7) : 1624 -1637 . DOI: 10.12082/dqxxkx.2025.250092
[Objectives] High-resolution remote sensing image segmentation provides essential data support for urban planning, land use, and land cover analysis by accurately extracting terrain information. However, traditional methods face challenges in predicting object categories at the pixel level due to the high computational cost of processing high-resolution images. Current segmentation approaches often divide remote sensing images into a series of standard blocks and perform multi-scale local segmentation, which captures semantic information at different granularities. However, these methods exhibit weak feature interaction between blocks, as they do not consider contextual prior knowledge, ultimately reducing local segmentation performance. [Methods] To address this issue, this paper proposes a high-resolution remote sensing image segmentation framework named CATrans (Cross-scale Attention Transformer), which combines cross-scale attention with a semantic-based visual Transformer. CATrans first predicts the segmentation results of local blocks and then merges them to produce the final global image segmentation. It introduces contextual prior knowledge to enhance local feature representation. Specifically, we propose a cross-scale attention mechanism to integrate contextual semantic information with multi-level features. The multi-branch parallel structure of the cross-scale attention module enhances focus on objects of varying granularities by analyzing shallow-deep and local-global dependencies. This mechanism aggregates cross-spatial information across various dimensions and weights multi-scale kernels to strengthen multi-level feature representations, enabling the model to avoid deep stacking and multiple sequential processes. Additionally, a semantic-based visual Transformer is adopted to couple multi-level contextual semantic information. Spatial attention is used to reinforce these semantic representations. The multi-level contextual information is grouped to form abstract semantic concepts, which are then fed into the Transformer for sequence modeling. The self-attention mechanism within the Transformer captures dependencies between different positions in the input sequence, thereby enhancing the correlation between contextual semantics and spatial positions. Finally, enhanced contextual semantics are generated through feature mapping. [Results] This paper conducts comparative experiments on the DeepGlobe, Inria Aerial, and LoveDA datasets. The results show that CATrans outperforms existing segmentation methods, including Discrete Wavelet Smooth Network (WSDNet) and Integrating Shallow and Deep Network (ISDNet). CATrans achieves a Mean Intersection over Union (mIoU) of 76.2%, 79.2%, and 54.2%, and a Mean F1 Score (mF1) of 86.5, 87.8%, and 66.8%, with inference speeds of 38.1 FPS, 13.2 FPS, and 95.22 FPS on the respective datasets. Compared to the best-performing method, WSDNet, CATrans improves segmentation performance across all classes, with mIoU gains of 2.1%, 4.0%, and 5.3%, and mF1 gains of 1.3%, 1.8%, and 5.6%. [Conclusions] These findings highlight that the proposed CATrans framework significantly enhances high-resolution remote sensing image segmentation by incorporating contextual prior knowledge to improve local feature representation. It achieves an effective balance between segmentation performance and computational efficiency.
利益冲突:Conflicts of Interest 所有作者声明不存在利益冲突。
All authors disclose no relevant conflicts of interest.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
衡雪彪, 许捍卫, 唐璐, 等. 基于改进全卷积神经网络模型的土地覆盖分类方法研究[J]. 地球信息科学学报, 2023, 25(3):495-509.
[
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
王春艳, 王子康. 改进区间二型模糊神经网络的遥感图像分割方法[J]. 地球信息科学学报, 2025, 27(2):522-535.
[
|
| [13] |
|
| [14] |
张银胜, 单梦姣, 陈昕, 等. 基于多模态特征提取与层级感知的遥感图像分割[J]. 地球信息科学学报, 2024, 26(12):2741-2758.
[
|
| [15] |
林雨准, 金飞, 王淑香, 等. 多分支双任务的多模态遥感影像道路提取方法[J]. 地球信息科学学报, 2024, 26(6):1547-1561.
[
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
/
| 〈 |
|
〉 |