
街景图像视觉位置识别技术研究综述
作者贡献:Author Contributions
张暖参与文献搜集、梳理归纳、论文撰写、论文修改;王涛、张艳、魏毅博、李镏文、刘熠晨参与论文的修改。所有作者均阅读并同意最终稿件的提交。
ZHANG Nuan participated in literature collection, sorting and summarizing, paper writing and revision; WANG Tao, ZHANG Yan, WEI Yibo, LI Liuwen and LIU Yichen participated in the revision of the paper. All the authors have read the last version of paper and consented for submission.
|
张 暖(2002— ),女,安徽铜陵人,硕士生,主要从事遥感影像定位、视觉图像位置识别技术等方向研究。E-mail: 1263513899@qq.com |
收稿日期: 2025-03-25
修回日期: 2025-06-08
网络出版日期: 2025-07-23
基金资助
智能空间信息国家级重点实验室基金(a8235)
An Overview of Visual Place Recognition Based on Street View Images
Received date: 2025-03-25
Revised date: 2025-06-08
Online published: 2025-07-23
Supported by
National Key Laboratory of Intelligent Spatial Information Fund(a8235)
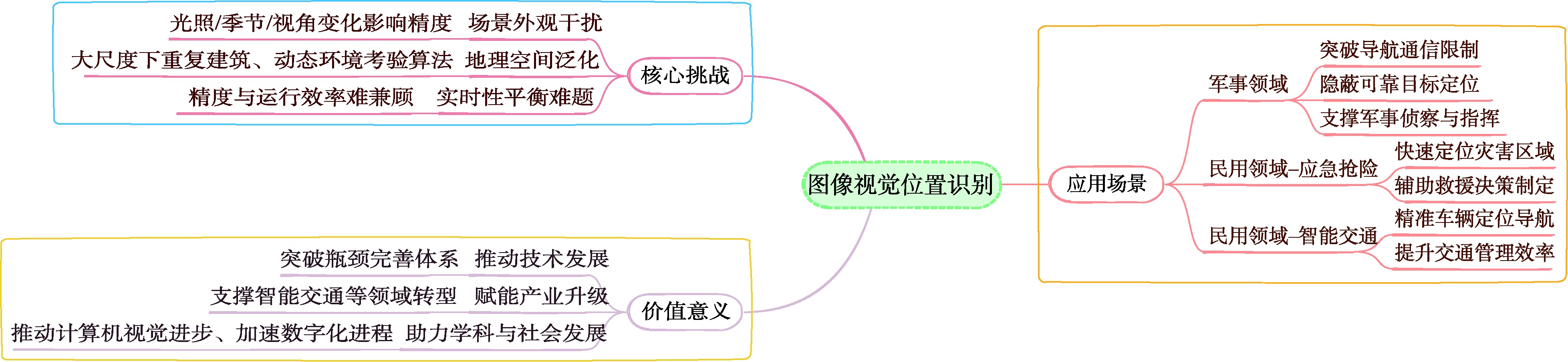
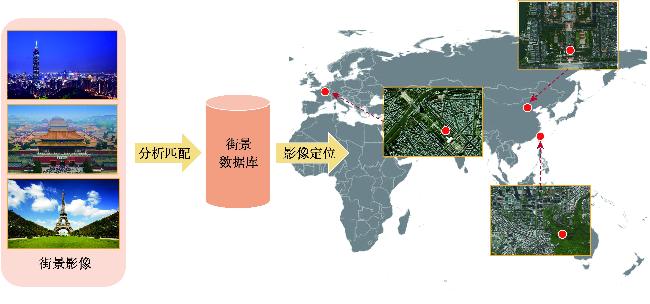
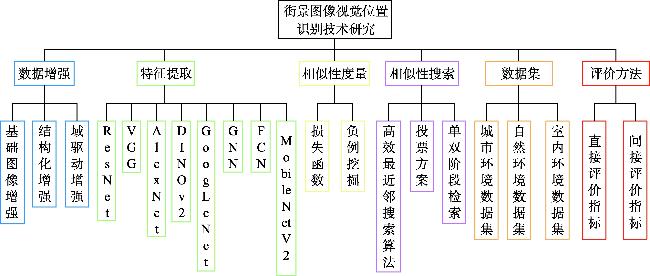
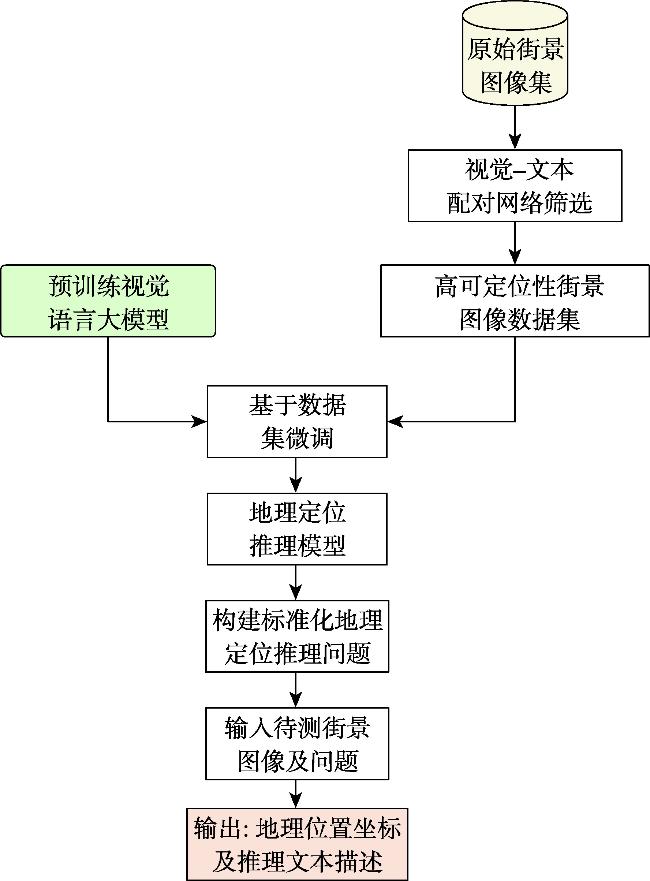
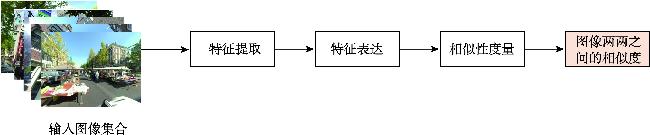
【意义】街景图像视觉位置识别(Street View Image-based Visual Place Recognition, SV-VPR)是一种基于视觉特征信息的地理位置识别技术,其核心任务是通过分析街景图像的视觉特征,实现对未知地点的地理位置预测和精确定位。该技术需要克服不同环境条件下的外观变化(如昼夜光照差异、季节更替特征演变等)和视点差异(如车载相机与卫星图像的视角偏差),并通过计算图像特征相似性、几何约束等条件来实现精准识别。作为计算机视觉与地理信息科学的交叉领域,SV-VPR与视觉定位、图像检索、SLAM等技术密切相关,在无人机自主导航、自动驾驶高精度定位、网络空间地理围栏构建、增强现实场景融合等领域具有重要应用价值,特别是在GPS信号缺失场景下展现出独特的定位优势。【分析】本文系统综述了街景图像视觉位置识别技术的研究进展,主要包含以下内容:首先,阐述了图像视觉位置识别技术的基础概念与分类,深入探讨了街景图像视觉位置识别技术的基础概念与分类方法;其次,详细分析了该领域的关键技术研究;此外,全面梳理了街景图像视觉位置识别技术相关的数据集资源;同时,梳理了该技术的评价方法与指标体系;最后,对街景图像视觉位置识别技术的未来研究方向进行了展望。【目的】通过本综述,旨在为相关研究者提供系统化的技术发展脉络梳理,帮助快速把握领域研究现状;关键技术与评估方法的对比分析,为算法选型提供决策依据;前沿挑战与潜在突破方向的预判,启发创新性研究思路。
张暖 , 王涛 , 张艳 , 魏毅博 , 李镏文 , 刘熠晨 . 街景图像视觉位置识别技术研究综述[J]. 地球信息科学学报, 2025 , 27(8) : 1751 -1779 . DOI: 10.12082/dqxxkx.2025.250137
[Significance] Street View Image-based Visual Place Recognition (SV-VPR) is a geographical location recognition technology that relies on visual feature information. Its core task is to predict and accurately locate unknown locations by analyzing the visual features of street view images. This technology must overcome challenges such as appearance changes under different environmental conditions (e.g., lighting differences between day and night, seasonal variations) and viewpoint differences (e.g., perspective deviations between vehicle-mounted cameras and satellite images). Accurate recognition is achieved through calculating image feature similarity, applying geometric constraints, and related methods. As an interdisciplinary field of computer vision and geographic information science, SV-VPR is closely related to visual positioning, image retrieval, SLAM, and more. It has significant application value in areas such as UAV autonomous navigation, high-precision positioning for autonomous driving, construction of geographical boundaries in cyberspace, and integration of augmented reality environments. It is particularly advantageous in GPS-denied environments. [Analysis] This paper systematically reviews the research progress of visual location recognition based on street view images, covering the following aspects: First, the basic concepts and classifications of visual place recognition technologies are introduced. Second, the foundational principles and categorization methods specific to street view image-based visual place recognition are discussed in depth. Third, the key technologies in this field are analyzed in detail. Furthermore, relevant datasets for street view image-based visual place recognition are comprehensively reviewed. In addition, evaluation methods and index systems used in this domain are summarized. Finally, potential future research directions for SV-VPR are explored. [Purpose] This review aims to provide researchers with a systematic overview of the technological development trajectory of SV-VPR, helping them quickly understand the current research landscape. It also offers a comparative analysis of key technologies and evaluation methods to support algorithm selection, and identifies emerging challenges and potential breakthrough areas to inspire innovative research.
表1 图像视觉位置识别表示形式Tab. 1 Visual Place Recognition representation |
| 缩写 | 全称 | 核心任务 | 应用场景 | 特点 |
|---|---|---|---|---|
| VPR[10-11] | Visual Place Recognition | 通过视觉信息识别地点 | 自动驾驶、机器人导航 | 依赖图像内容,无需额外传感器 |
| GL[18] | Geo-localization | 确定图像的地理位置 | 地图服务、社交媒体定位 | 结合图像和地理信息 |
| IBL[15] | Image-Based Localization | 通过图像匹配确定地理位置 | 自动驾驶、机器人导航 | 依赖图像内容,无需额外传感器 |
| IAL[16] | Image-Augmented Localization | 结合图像和其他传感器数据提高定位 | 高精度地图、室内定位 | 多模态数据融合,定位精度高 |
| CBIR[17] | Content-Based Image Retrieval | 基于图像内容检索相似图像 | 图像搜索引擎、医学图像分析 | 专注于图像相似性,不涉及定位 |
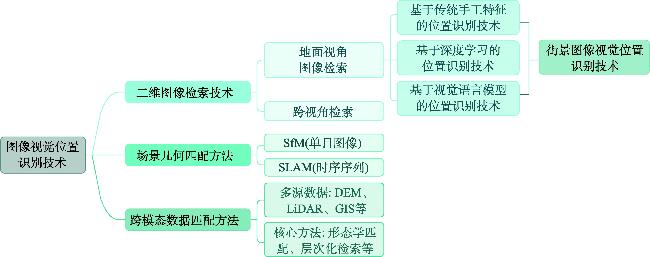
表2 街景图像视觉位置识别方法分类及特点对比Tab. 2 Classification and feature comparison of SV-VPR |
| 分类 | 内容 | 特点 |
|---|---|---|
| 传统手工特征方法 | 局部特征 全局特征 | 角点、边缘或特定的图像块 一个或多个向量描述整体特征 |
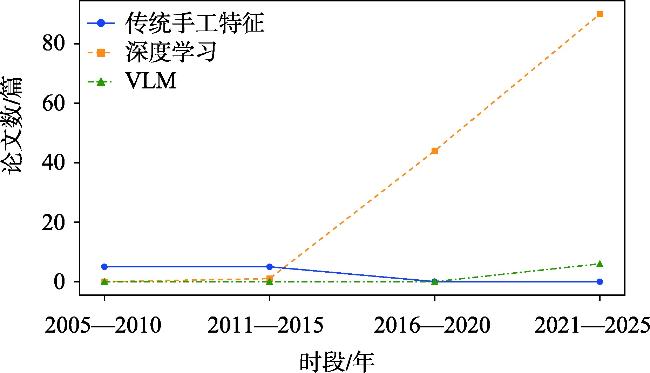
| 深度学习方法 | 卷积神经网络 Vision Transformer | 通过卷积核提取特征信息 通过自注意力机制获取图像全局特征信息 |
| 视觉语言模型方法 | Vision-Language Models, VLMs | 利用视觉信息和相关的文本描述进行联合推理 |
| 其他 | 分类方法 语义分割方法 | 将地理空间划分为多个离散的区域或类别 将视觉词收集到描述符中的鲁棒机制 |
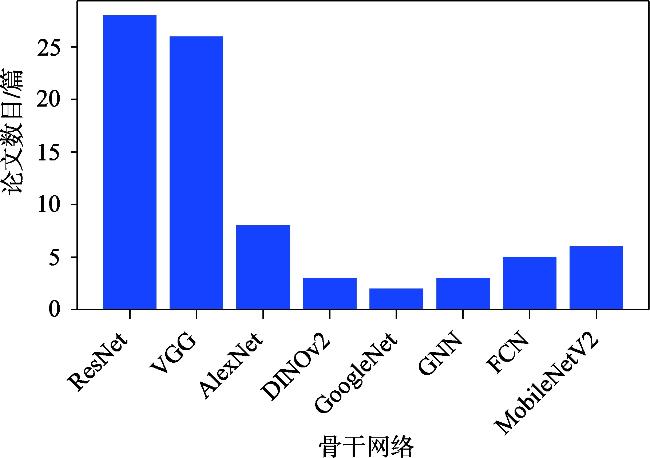
表3 街景图像视觉位置识别技术骨干网络Tab. 3 Backbone network of SV-VPR |
| 骨干网络 | 结构特点 | 核心优势 | 典型应用场景 | 改进方法 | 参考文献 |
|---|---|---|---|---|---|
| ResNet | 残差模块堆叠(残差连接+卷积层) | 解决梯度消失问题,支持超深层网络训练 | 全局特征模块(EigenPlaces)、局部-全局特征融合(DOLG)、跨区域泛化(AdAGeo) | 地理注意力模块、双分支门控机制、PCA降维 | [7]、[64-66] |
| VGG | 深度堆叠(16-19层)的3×3卷积与2×2池化 | 深度特征提取能力强,结构简单易扩展 | NetVLAD系列描述符生成、区域特征池化(R-MAC)、自监督鲁棒性优化(CRN/SFRS) | 多分辨率特征融合、对比学习策略、域自适应训练 | [3]、[9]、[30]、[67-73] |
| AlexNet | 5卷积层+3全连接层,ReLU与局部响应归一化 | 浅层特征保留丰富空间细节,适合轻量化部署 | 动态池化(GeM)、空间注意力迦百农(APANet)、序列特征融合(LSTS-VPR) | 多尺度权重分配、LSTM时序建模、金字塔注意力机制 | [8]、[47]、[75] |
| DINOv2 | 基于ViT架构,自监督预训练 | 无需微调即可迁移,具有强大场景泛化 能力 | 最优传输聚合(SALAD)、语义片段检索(SegVLAD)、遮挡鲁棒性定位 | 最优传输特征匹配、语义分割引导检索、多模态特征对齐 | [74]、[76] |
| GoogLeNet | Inception模块(并行多尺度卷积) | 多尺度特征联合计算,提升计算效率 | 大规模场景识别(Places数据集)、动态注意力调整(CFAM) | 上下文灵活注意力机制、跨层特征交互、轻量化Inception变体 | [36]、[77-78] |
| 图神经网络 | GCN/GAT/GAE等图结构建模 | 拓扑关系建模能力强,支持多模态数据整合 | 空间金字塔注意力(GSAP)、层次化点云匹配(HiBi-GCN)、多模态融合(iB-GAT) | 层次图聚类、双向图卷积、跨模态注意力门控 | [79]、[80-81] |
| 全卷积网络 | 全卷积层架构(无全连接层) | 支持任意尺寸输入,完整保留空间信息 | 结构化特征提取(Superpoint)、建筑立面分块建模(多尺度SPP) | 多尺度并行卷积、双输出热图-描述子联合训练、空间金字塔池化 | [82-83] |
| MobileNetV2 | 倒置残差结构(深度可分离卷积+线性瓶颈层) | 计算量减少75%, 适合移动端部署 | 低光环境定位(LSDNet)、边缘设备实时定位(动态NAS) | 光照补偿模块、低位宽量化、多分支注意力 剪枝 | [84-85] |
表4 街景图像视觉位置识别常用损失函数Tab. 4 Commonly used loss functions of SV-VPR |
| 损失函数 | 设计目标 | 方法或公式 | 公式说明 | 公式编号 | 应用 |
|---|---|---|---|---|---|
| 三元组损失(Triplet Loss) | 增强特征区分性,拉近正样本对距离,推远负样本对距离 | a为锚点; p为正样本; n为负样本 | (1) | FedVPR[99]、GPM[100]、JIST[6]、SOLAR[87]、Patch-NetVLAD+[68]、MultiRes-NetVLAD[69] | |
| 对抗损失 | 对齐源域与目标域特征分布,缓解环境差异 | 域判别网络使用二分类交叉熵损失: | G为特征提取网络; D为判别网络 | (2) | 基于难例挖掘和域自适应的视觉位置识别[71] |
| 多相似性损失 | 动态调整正、负样本对权重,优化相似性度量 | 结合样本对的相似性权重: | α、β为正负样本的对损失计算的“温度系数”; Sip为正样本对的相似性得分; Sin为负样本对的相似性得分; λ为阈值偏移量 | (3) | DINOv2-SALAD[74]、MixVPR[54]、BoQ[3]、Conv-AP[1] |
| ArcFace 损失 | 在余弦空间中引入余量,增强特征区分性 | s为缩放因子; θy样本特征与真实类别y对应的中心向量之间的夹角; m为角度余量; cos θi样本特征与类别j对应的中心向量之间的余弦相似度 | (4) | DELG[86]、Divide&Classify(D&C)[89]、DOLG[65] | |
| InfoNCE 损失 | 增强跨模态对比学习的鲁棒性 | τ为温度系数 | f(x)和f(y)分别为样本x、y的特征表示; τ为温度系数 | (5) | 结合分类与检索的全球尺度图像定位[101] |
| 负对数似然损失(NLL loss) | 优化全局描述符的分类概率分布 | 将全局描述符输入MLP生成类别概率,通过Log Softmax计算对数概率,最小化负对数似然 | GSAP[79] | ||
| 多任务联合损失 | 同时优化定位与辅助任务(如语义分割) | 加权和: (如交叉熵损失) | λ1、λ2控制不同任务对总损失的贡献度 | (6) | LSDNet[84] |
| 均方误差(MSE) | 回归任务中最小化预测值与真实值的平方差异 | n为样本数量; yi为真实值; 为预测值 | (7) | MeshVPR[5]、SOLAR、JIST、AddressCLIP[102] | |
| 交叉熵损失(Cross-Entropy) | 分类任务中优化概率分布匹配 | n为样本数量; yi为真实标签; 为预测概率 | (8) | Superpoint[31]、Places-CNN[77]、DELF[49]、GATs[103] 、FPN[104]、SFRS[9]、ETR[45]、EchoVPR[90]、GFS [105] |
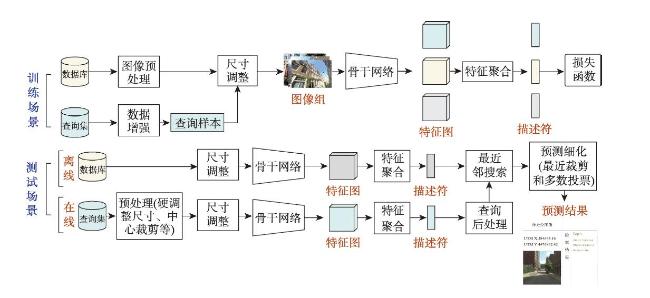
表5 街景图像视觉位置识别算法负例挖掘方法Tab. 5 Negative example mining method of SV-VPR algorithm |
| 方法分类 | 负例挖掘 | 核心描述 |
|---|---|---|
| 基于数据分布的 负例挖掘策略 | 全局与局部空间采样 | 1. 完整数据库挖掘:利用数据集全部负样本,适用于小规模数据集(PlaceNet[106]基于GPS坐标 阈值划分正负样本); 2. 数据库挖掘:随机采样部分负例池(如ETR[45]),或动态更新负样本池(SFRS[9]) |
| 困难样本挖掘机制 | 1.在线困难挖掘:在训练过程中实时筛选高损失样本(SARE),或基于特征空间最近邻动态构 建三元组(难例挖掘算法); 2. 离线困难挖掘:利用代理描述符缓存历史难例(如GPM[100]通过k-NN索引聚集相似负例), 或结合密集匹配筛选低匹配度样本(Patch-NetVLAD+通过RANSAC过滤候选) | |
| 基于地理信息的 负例生成方法 | 地理坐标约束 | 1. 采用GPS距离阈值划分正负例(SPE-NetVLAD以25 m为负例边界,PlaceNet以10 m为阈值); 2. 基于地球分区构建负例(如将不同地理单元格图像视为负例) |
| 地理语义关联 | 1. 通过场景类别标签排除同类别样本; 2. 利用地理语义聚类(GPM代理描述符) | |
| 基于特征空间的 负例优化方法 | 特征相似度度量 | 1. 使用欧氏距离或余弦距离筛选难例(SARE通过特征嵌入空间最近邻选取负例); 2. 结合视觉单词匹配与3D点对应关系(直接匹配方法建立特征-3D点关联) |
| 多模态特征融合 | 1. 联合地理与视觉特征(SPE-NetVLAD融合GPS与特征距离); 2. 构建多任务学习框架(SARE) |
表6 街景图像视觉位置识别技术最近邻搜索算法Tab. 6 Nearest neighbor search agorithm of SV-VPR |
| 方法分类 | 方法 | 原理与特点 | 适用场景 |
|---|---|---|---|
| 传统精确搜索方法 | 穷举kNN | 遍历所有特征点计算距离(如欧氏距离),确保全局最优解,但计算复杂度高 | 小规模数据集验证基准 |
| 穷尽式欧氏搜索 | 直接计算查询特征与数据库特征间的欧氏距离,无需索引构建(如GeM未微调CNN的特征匹配) | 低维度或小规模检索任务 | |
| 基于量化与压缩的近似方法 | 乘积量化(PQ) | 将高维向量分段量化,通过码本压缩表示,减少存储和计算量 | 大规模高维数据,内存受限场景 |
| IVFPQ(Inverted File with Product Quantization) | 倒排索引(IVF)聚类缩小搜索范围+PQ量化降低计算复杂度,平衡精度与效率 | 亿级规模图像检索 (如Faiss库实现) | |
| 基于树结构的搜索方法 | KD树 | 递归划分空间维度构建二叉树,适合低维数据精确搜索(DELF结合KD树加速局部特征匹配) | 中小规模结构化数据 (如2D特征验证) |
| k-means树 | 层次化聚类构建树,优先搜索最近聚类分支(HMM采用此方法优化搜索路径) | 中高维动态数据集 | |
| 随机KD树森林(AKM) | 并行构建多棵随机KD树,通过投票机制选择最优分支,提升搜索鲁棒性(用于AKM聚类加速) | 高维数据近似分配 | |
| 基于图的近似搜索方法 | HNSW(Hierarchical Navigable Small World) | 分层可导航小世界图,利用多层图结构快速导航至最近邻,支持动态插入和高召回率 | 高维数据实时检索 |
| 混合方法与优化策略 | 倒排多索引(MultiIndex) | 多级倒排索引结构,通过多维度分块提升检索速度 | 超大规模分布式检索 |
| 内积转欧氏搜索 | 通过数学变换将最小内积搜索转化为欧氏距离搜索 | 内积相似性优化场景 | |
| 曼哈顿距离优化(ODNPSM) | 采用曼哈顿距离(L1范数)替代欧氏距离,简化计算 | 硬件资源受限的嵌入式系统 |
表7 街景图像视觉位置识别技术投票方案Tab. 7 Voting schemes of SV-VPR |
| 方法 | 特点 | 适用场景 |
|---|---|---|
| 简单多数投票法 | 实现简单,计算效率高,但可能忽略不同模型的置信度差异 | 多模型并行处理且数据噪声较低的场景 |
| 加权投票法 | 能更精细地反映不同模块的重要性,但需设计合理的权重 分配策略 | 动态环境中需平衡多源信息时,如融合视觉和文本特征的VPR系统 |
| 聚类投票法 | 有效处理噪声和异常值,但计算复杂度较高 | 复杂路径规划或存在大量相似候选位置的场景 |
| 多模态融合投票 | 提升环境适应性,但需解决模态对齐和计算资源消耗问题 | 光照变化大或动态干扰多的环境,如自动驾驶中的实时定位。 |
| 基于深度学习的 投票机制 | 无需手动设计规则,依赖大量数据和算力 | 高精度要求的机器人导航,资源允许的情况下效果最佳。 |
| 基于倒排索引的 投票机制 | 检索速度快,适合大规模数据库,但对特征量化的精度 要求较高 | 适合大规模数据库 |
表8 街景图像视觉位置识别技术单阶段检索和双阶段检索对比Tab. 8 Comparison of single-stage and two-stage searches of SV-VPR |
| 对比维度 | 单阶段方法 | 双阶段方法 |
|---|---|---|
| 速度与效率 | 实时性强,适合移动端或大规模检索(如NetVLAD) | 计算开销大,依赖候选生成(如SIFT+R-MAC) |
| 精度与鲁棒性 | 易受复杂背景干扰,依赖数据量(如CosPlace) | 分阶段优化,复杂场景更稳定(如DELG) |
| 模型复杂度 | 结构简单,参数量少(如BoQ) | 多模块协同,需调参(如Hybrid-Swin-Transformer) |
| 适用场景 | 高动态环境、实时导航 | 高精度地理匹配、小样本检索 |
| 代表性方法 | NetVLAD、Patch-NetVLAD、DELF、SOLAR | HF-Net、R-MAC、DELG、DOLG-EfficientNet |
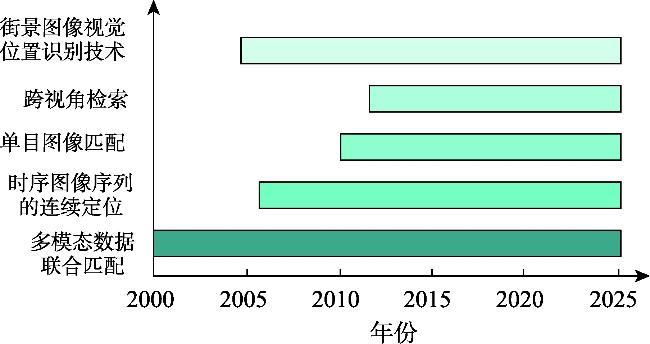
表9 典型VPR数据集Tab. 9 Typical VPR dataset |
| 数据集 | 时间/年 | 环境 | 查询集/张 | 参考集/张 | 条件变化 | 适用方法 | 图片大小/(像素×像素) | |
|---|---|---|---|---|---|---|---|---|
| 查询 | 参考 | |||||||
| Tokyo 24/7 | 2015 | 户外 | 315 | 75 984 | 光照 | Pair-VPR、EffoVPR | 3 264×2 448 | 640×480 |
| SF-XL | 2022 | 城市 | 1 000(v1) 598(v2) | 41.2 M | 光照、季节 | EffoVPR | 1 024×768 | 1 024×768 |
| AmsterTime | 2022 | 城市 | 1 231 | 1 231 | 长期时间、 光照 | EffoVPR | 1 024×1 024 | 1 920×1 080 |
| SYNTHIA | 2016 | 城市 | 200 | 200 | 天气、光照、 季节 | - | 300×200 | 300×200 |
| Pittsburgh | 2015 | 城市 | 1 000 | 23 000 | 视角 | Pair-VPR、EffoVPR、BoQ | 640×480 | 640×480 |
| MSLS | 2020 | 城市 | 11 000/514 000 (训练/测试) | 19 000/934 000(训练/测试) | 天气、季节 | BoQ、SelaVPR | 640×480 | 640×480 |
| St Lucia | 2018 | 城市郊区 | 1 464 | 1 509 | 天气、光照、 季节 | EffoVPR、BoQ | 640×480 | 640×480 |
| SPEDtest | 2018 | 户外 | 607 | 607 | 天气、季节 | BoQ、DINOV2 SALAD | 320×240 | 320×240 |
| GSV-Cities | 2022 | 户外 | 80 000 | 120 000 | 长期时间、光照、天气、动态 | - | 224×224 | 224×224 |
| Tokyo Time Machine | 2016 | 城市 | 315 | 76 000 | 时间 | - | 640×480 | 640×480 |
| Nordland | 2013 | 火车视角 | 2 760 | 27 592 | 季节 | EffoVPR、BoQ | 1 920×1 080 | 1 920×1 080 |
| GardensPoint | 2018 | 大学校园 | 200 | 200 | 光照 | AnyLoC、MixVPR | 960×540 | 640×360 |
| Campus Loop | 2011 | 自然 | 100 | 100 | 光照、视角 | - | 640×480 | 640×480 |
| Baidu Mall | 2015 | 室内 | 500~1 000 | >10 000 | 光照、 人群密度 | SegVLAD、 AnyLoc | 1 920×1 080 | 1 920×1 080 |
| 17 Places | 2016 | 室内 | 406 | 406 | 光照 | SegVLAD、 AnyLoc | 640×480 | 640×480 |
| 7-scenes | 2013 | 室内 | 15 000 | 56 000 | 视角、光照、重复纹理 | - | 640×480 | 640×480 |
表10 数据集方法应用排行(Tokyo 24/7)Tab. 10 Ranking of dataset method applications (Tokyo 24/7) |
| 排名 | 方法 | Recall@1 | 时间/年 | 备注 |
|---|---|---|---|---|
| 1 | Pair-VPR-p | 100.0 | 2024 | Re-ranking |
| 2 | EffoVPR | 98.7 | 2024 | DINOv2, Re-ranking |
| 3 | Pair-VPR-s | 98.1 | 2024 | Re-ranking |
| 4 | BoQ | 98.1 | 2024 | ResNet-50 |
| 5 | SelaVPR | 94.0 | 2024 | DINOv2, Re-ranking |
| 6 | EigenPlaces | 93.0 | 2023 | ResNet-50 |
| 7 | ProGEO | 88.6 | 2024 | CLIP |
| 8 | Patch-NetVLAD | 86.0 | 2021 | Re-ranking |
| 9 | CosPlace | 82.2 | 2022 | ResNet-50 |
表11 数据集方法应用排行(SF-XL test v1)Tab. 11 Ranking of dataset method applications (SF-XL test v1) |
| 排名 | 方法 | Recall@1 | 时间/年 |
|---|---|---|---|
| 1 | EffoVPR | 95.5 | 2024 |
| 2 | ProGEO | 84.7 | 2024 |
| 3 | EigenPlaces | 84.1 | 2023 |
| 4 | CosPlace | 64.7 | 2022 |
表12 数据集方法应用排行(SF-XL test v2)Tab. 12 Ranking of dataset method applications (SF-XL test v2) |
| 排名 | 方法 | Recall@1 | 时间/年 |
|---|---|---|---|
| 1 | EffoVPR | 94.5 | 2024 |
| 2 | ProGEO | 93 | 2024 |
| 3 | EigenPlaces | 90.8 | 2023 |
| 4 | CosPlace | 83.4 | 2022 |
表13 数据集方法应用排行(AmsterTime)Tab. 13 Ranking of dataset method applications (AmsterTime) |
| 排名 | 方法 | Recall@1 | 时间/年 | 备注 |
|---|---|---|---|---|
| 1 | EffoVPR | 65.5 | 2024 | DINOv2, Re-ranking |
| 2 | BoQ | 63.0 | 2024 | ResNet-50 |
| 3 | SegVLAD | 60.2 | 2024 | - |
| 4 | EigenPlaces | 48.9 | 2023 | ResNet-50 |
表14 数据集方法应用排行 (Pittsburgh-30k-test)Tab. 14 Ranking of dataset method applications (Pittsburgh-30k-test) |
| 排名 | 方法 | Recall@1 | 时间/年 | 备注 |
|---|---|---|---|---|
| 1 | Pair-VPR-p | 95.40 | 2024 | Re-ranking |
| 2 | Pair-VPR-s | 94.70 | 2024 | Re-ranking |
| 3 | EffoVPR | 98.10 | 2024 | DINOv2, Re-ranking |
| 4 | BoQ | 93.70 | 2024 | DINOv2 |
| 5 | SegVLAD- | 93.10 | 2024 | DINOv2 |
| 6 | ProGEO | 93.00 | 2024 | CLIP |
| 7 | SelaVPR | 92.80 | 2024 | DINOv2, Re-ranking |
| 8 | EigenPlaces | 92.50 | 2023 | ResNet-50 |
| 9 | MixVPR | 91.52 | 2023 | ResNet-50 |
| 10 | CosPlace | 90.45 | 2022 | ResNet-50 |
| 11 | Patch-NetVLAD | 88.70 | 2021 | Re-ranking |
| 12 | AnyLOC-VLAD-DINOV2 | 87.66 | 2023 | - |
| 13 | NetVLAD | 86.08 | 2015 | - |
表15 数据集方法应用排行(Pittsburgh-250k-test)Tab. 15 Ranking of dataset method applications (Pittsburgh-250k-test) |
| 排名 | 方法 | Recall@1 | 时间/年 | 备注 |
|---|---|---|---|---|
| 1 | BoQ | 96.6 | 2024 | DINOv2 |
| 2 | SelaVPR | 95.7 | 2024 | DINOv2, Re-ranking |
| 3 | DINOV2 SALAD | 95.1 | 2023 | DINOv2 |
| 4 | MixVPR | 94.6 | 2023 | ResNet-50 |
| 5 | EigenPlaces | 94.1 | 2023 | ResNet-50 |
| 6 | ConV-AP | 92.4 | 2022 | ResNet-50 |
| 7 | ProGEO | 92.2 | 2024 | CLIP |
| 8 | NetVLAD (with GPM) | 91.5 | 2023 | ResNet-50 |
| 9 | CosPlace | 91.5 | 2022 | ResNet-50 |
表16 数据集方法应用排行(MSLS)Tab. 16 Ranking of dataset method applications (MSLS) |
| 排名 | 方法 | Recall@1 | 时间/年 | 备注 |
|---|---|---|---|---|
| 1 | BoQ | 96.6 | 2024 | DINOv2 |
| 2 | SelaVPR | 95.7 | 2024 | DINOv2, Re-ranking |
| 3 | DINOV2 SALAD | 95.1 | 2023 | DINOv2 |
| 4 | MixVPR | 94.6 | 2023 | ResNet-50 |
| 5 | EigenPlaces | 94.1 | 2023 | ResNet-50 |
| 6 | ConV-AP | 92.4 | 2022 | ResNet-50 |
| 7 | ProGEO | 92.2 | 2024 | CLIP |
| 8 | NetVLAD (with GPM) | 91.5 | 2023 | ResNet-50 |
| 9 | CosPlace | 91.5 | 2022 | ResNet-50 |
表17 数据集方法应用排行(St Lucia)Tab. 17 Ranking of dataset method applications (St Lucia) |
| 排名 | 方法 | Recall@1 | 年份 | 备注 |
|---|---|---|---|---|
| 1 | EffoVPR | 100 | 2024 | DINOv2, Re-ranking |
| 2 | BoQ | 100 | 2024 | DINOv2 |
| 3 | SelaVPR | 99.8 | 2024 | Re-ranking |
| 4 | ProGEO | 99.7 | 2023 | CLIP |
| 5 | MixVPR | 99.66 | 2023 | ResNet-50 |
| 6 | CosPlace | 99.59 | 2022 | ResNet-50 |
| 7 | AnyLoC | 96.17 | 2023 | |
| 8 | DINOv2 | 78.62 | 2023 | |
| 9 | NetVLAD | 57.92 | 2015 | |
| 10 | DINO | 45.22 | 2021 |
表18 数据集方法应用排行(SPED)Tab. 18 Ranking of dataset method applications (SPED) |
| 排名 | 方法 | Recall@1 | 年份 | 备注 |
|---|---|---|---|---|
| 1 | BoQ | 92.5 | 2024 | ResNet-50 |
| 2 | DINOV2 SALAD | 92.1 | 2023 | DINOv2 |
| 3 | BoQ(ResNet-50) | 86.5 | 2024 | |
| 4 | MixVPR | 85.2 | 2023 | ResNet-50 |
表19 数据集方法应用排行(Nordland)Tab. 19 Ranking of dataset method applications (Nordland) |
| 排名 | 方法 | Recall@1 | 时间/年 | 备注 |
|---|---|---|---|---|
| 1 | EffoVPR | 95 | 2024 | DINOv2, Re-ranking |
| 2 | BoQ | 90.6 | 2024 | ResNet-50 |
| 3 | SelaVPR | 86.6 | 2024 | DINOv2, Re-ranking |
| 4 | DINOV2 SALAD | 85.2 | 2023 | DINOv2 |
| 5 | MixVPR | 76.0 | 2023 | ResNet-50 |
| 6 | Patch-NetVLAD | 58.4 | 2021 | Re-ranking |
| 7 | NetVLAD(with GPM) | 44.9 | 2023 | ResNet-50 |
| 8 | Cony-AP | 38.5 | 2022 | ResNet-50 |
表20 数据集方法应用排行(GardensPoint)Tab. 20 Ranking of dataset method applications (GardensPoint) |
| 排名 | 方法 | Recall@1 | 时间/年 |
|---|---|---|---|
| 1 | AnyLoC | 95.50 | 2023 |
| 2 | MixVPR | 91.50 | 2023 |
| 3 | DINO | 78.50 | 2021 |
| 4 | CosPlace | 74.00 | 2022 |
| 5 | DINOv2 | 71.50 | 2023 |
| 6 | NetVLAD | 58.50 | 2015 |
| 7 | CLIP | 42.50 | 2023 |
表21 数据集方法应用排行(Baidu Mall)Tab. 21 Ranking of dataset method applications (Baidu Mall) |
| 排名 | 方法 | Recall@1 | 时间/年 | 备注 |
|---|---|---|---|---|
| 1 | SegVLAD- PreT | 80.40 | 2024 | DINOv2 |
| 2 | AnyLoc | 75.22 | 2024 | DINOv2 |
| 3 | MixVPR | 64.44 | 2023 | - |
| 4 | CLIP | 56.02 | 2023 | - |
| 5 | NetVLAD | 53.10 | 2015 | - |
| 6 | DINOv2 | 49.21 | 2023 | - |
| 7 | CosPlace | 41.62 | 2022 | - |
表22 数据集方法应用排行(17 Places)Tab. 22 Ranking of dataset method applications (17 Places) |
| 排名 | 方法 | Recall@1 | 时间/年 |
|---|---|---|---|
| 1 | SegVLAD-FineT | 95.30 | 2024 |
| 2 | AnyLoc | 65.02 | 2024 |
| 3 | MixVPR | 63.79 | 2023 |
| 4 | DINOv2 | 61.82 | 2023 |
| 5 | NetVLAD | 61.58 | 2015 |
| 6 | CosPlace | 61.08 | 2022 |
| 7 | CLIP | 59.36 | 2023 |
表23 评价指标Tab. 23 Evaluation indicators |
| 指标类型 | 主要用途 | 指标输出形式 | 典型方法 |
|---|---|---|---|
| RecallRate@N | PL+LC+IR | N个值输出 | HF-Net、Hybrid-Swin-Transformer |
| AUC-PR | PL+LC+IR | 单个值输出 | NetVLAD、DINOv2 SALAD |
| AUC-ROC | PL+LC+IR | 单个值输出 | HOG、NetVLAD |
| 真阳性分布 | LC+IR | 单个值输出 | SegVLAD、EchoVPR |
| PCU | PL+LC | 单个值输出 | BoQ、APANet |
注: PL(primary localisation)代表初始定位; LC(loop-closure)代表闭环; IR(image retrieval)代表图像检索。 |
利益冲突:Conflicts of Interest 所有作者声明不存在利益冲突。
All authors disclose no relevant conflicts of interest.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
[
|
| [51] |
|
| [52] |
|
| [53] |
|
| [54] |
|
| [55] |
|
| [56] |
|
| [57] |
|
| [58] |
|
| [59] |
|
| [60] |
|
| [61] |
|
| [62] |
袁一, 程亮, 宗雯雯, 等. 互联网众源照片的三维重建定位技术[J]. 测绘学报, 2018, 47(5):631-643.
[
|
| [63] |
|
| [64] |
|
| [65] |
|
| [66] |
|
| [67] |
|
| [68] |
|
| [69] |
|
| [70] |
|
| [71] |
|
| [72] |
仇晓松, 邹旭东, 王金戈, 等. 基于卷积神经网络的视觉位置识别方法[J]. 计算机工程与设计, 2019, 40(1):223-229.
[
|
| [73] |
[
|
| [74] |
|
| [75] |
|
| [76] |
|
| [77] |
|
| [78] |
|
| [79] |
|
| [80] |
|
| [81] |
|
| [82] |
|
| [83] |
|
| [84] |
|
| [85] |
|
| [86] |
|
| [87] |
|
| [88] |
|
| [89] |
|
| [90] |
|
| [91] |
|
| [92] |
|
| [93] |
|
| [94] |
|
| [95] |
|
| [96] |
|
| [97] |
|
| [98] |
|
| [99] |
|
| [100] |
|
| [101] |
|
| [102] |
|
| [103] |
|
| [104] |
|
| [105] |
|
| [106] |
王红君, 郝金龙, 赵辉, 等. 大规模城市环境下视觉位置识别技术的研究[J]. 计算机应用与软件, 2021, 38(8):194-198,226.
[
|
| [107] |
孔德磊, 方正, 李昊佳, 等. 基于事件的端到端视觉位置识别弱监督网络架构[J]. 机器人, 2022, 44(5):613-625.
[
|
| [108] |
|
| [109] |
|
| [110] |
|
| [111] |
|
| [112] |
|
| [113] |
|
| [114] |
|
| [115] |
|
| [116] |
|
| [117] |
|
| [118] |
|
| [119] |
|
| [120] |
|
| [121] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}