
Journal of Geo-information Science >
Implementation of Cluster MPI-Based Parallel Polygon Union Algorithm at the Feature Layer Level
Received date: 2013-08-13
Request revised date: 2013-09-17
Online published: 2014-07-10
Copyright
Under the environment of cluster, OGC simple feature specification and MPI parallel programming model-based parallel polygon union algorithm should address the “many-to-many” mapping relationships between features of overlapping layers. However, spatially adjacent features are not necessarily continuous in the storage sequence. It cannot assign parallel tasks to computational nodes of cluster according to feature sequences, which lead to an implementation dilemma on the task mapping procedure of parallel union algorithm. This research is focused on the design and implementation of parallel polygon union algorithm in the cluster parallel environment. We believe that to determine the “one-to-many” or “many-to-many” relationships between polygons of the two overlapping layers is the primary prerequisite to the implementation of parallel polygon overlay algorithms at the feature layer level. Therefore, firstly we analyzed the differences on parallelizing algorithms by comparing impacts brought by the two kinds of feature mapping relationships. Secondly, we proposed six different parallel task mapping strategies based on the R-tree spatial index data structure, the exactly spatial searching functionalities of MySQL and the MPI communication mechanism. Finally, we implemented six parallel polygon union algorithms based on the six task-mapping approaches and conducted experiments to compare the pros and cons of each strategy. The experimental results show that the parallel polygon union algorithm based on R-tree-based feature pre-screening strategy is the most efficient one in serial, which also demonstrates better parallel accelerating effects than others. Furthermore, the strategy of exactly spatial searching based on MySQL shows higher time costs on feature pre-screening, but it can filter out all polygons which do not intersected with geometries which can thereby reduce redundant union operations and improve the computational efficiency. Therefore, the R-tree-based and MySQL exactly spatial searching-based feature pre-screening strategies are effective approaches to solving the parallel task mapping problem and implementing the parallel polygon union algorithm using the MPI programming model under the cluster environment.
Key words: polygon union; pre-screening; task mapping; parallel computing; MPI communicating
FAN Junfu , MA Ting , ZHOU Chenghu , JI Min , ZHOU Yuke , XU Tao . Implementation of Cluster MPI-Based Parallel Polygon Union Algorithm at the Feature Layer Level[J]. Journal of Geo-information Science, 2014 , 16(4) : 517 -523 . DOI: 10.3724/SP.J.1047.2014.00517
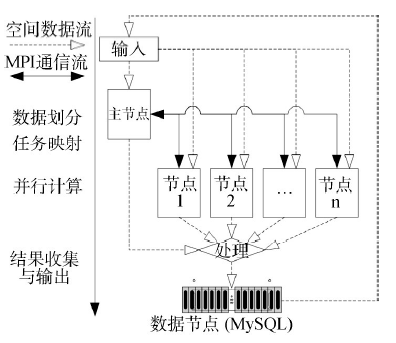
Fig.1 Logical flow of MPI-based parallel union algorithm of polygon layers图1 基于MPI的多边形图层并行合并算法流程 |
Fig.2 Contents of MPI data package of feature sequence-based data partition strategy图2 序列划分策略下MPI通信数据包内容 |
Fig.3 Contents of MPI data package of implicit data synchronization strategy图3 隐式数据同步策略下MPI通信数据包内容 |
Fig.4 Contents of MPI data package of spatial extent-based polling communicating strategy图4 基于空间范围的轮询通信策略下MPI通信数据包内容 |
Fig.5 Contents of MPI data package of spatial extent-based message packaging communicating strategy图5 基于空间范围的打包通信策略下MPI通信数据包内容 |
Tab.1 Software and hardware parameters of our experimental cluster表1 实验集群软硬件配置指标 |
| 项目 | 参数 |
|---|---|
| 制造商 | IBM |
| CPU | Intel Xeon X5650;2 *6核 |
| 内存 | 6*4GB |
| 网络 | 千兆网络 |
| 磁盘阵列 | IBM DS3512 (24*1TB);RAID5 |
| 节点数量 | 计算节点:6;存储节点:1 |
| 操作系统 | RHEL Server release 6.2 (Santiago) |
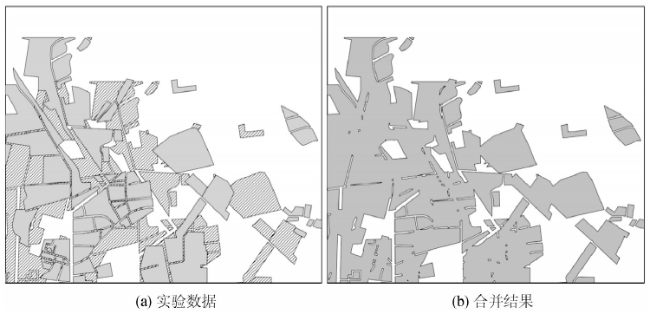
Fig.6 Experimental data and union results of polygon union algorithm图6 多边形叠加合并实验数据及合并结果 |
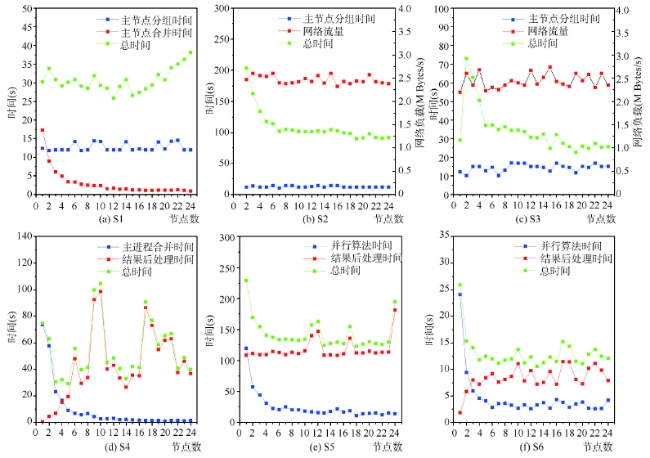
Fig.7 Experimental results of parallel polygon union algorithms based on different task mapping strategies图7 不同任务映射策略下多边形并行合并实验结果 |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
Environmental Systems Research Institute, Inc.. ESRI shapefile technical description[EB/OL]. Jul 1998. URL:
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
/
| 〈 |
|
〉 |




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}