
Journal of Geo-information Science >
Research on the LBS Matching Based on Stay Point of the Semantic Trajectory
Received date: 2013-10-14
Request revised date: 2013-12-04
Online published: 2014-09-04
Copyright
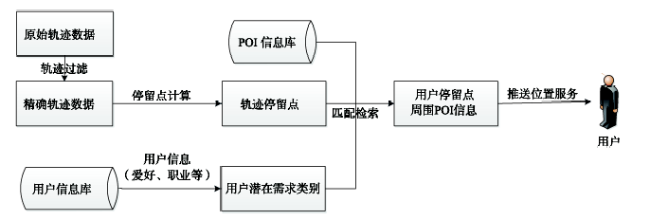
Location Based Service (LBS), with the support of GIS, is a thriving service for users related with coordinates received by wireless communication network or GPS. The trajectories composed with a set of received coordinates mainly express the character and habit of user’s behavior. Through analyzing and mining users’ trajectories, we will improve the efficiency of location based service. In this paper, firstly, the trajectories data including location coordinates and semantic fields are collected through GPS signal by the self-developed software installed in the terminal. The semantic fields contain the ID of user, current speed, nearby landmark and so on. Then the mistakes incorporated in raw trajectories due to the GPS instability should be filtered to enhance data accuracy. A method has been applied to filter the “jitter” points and to calculate the angle (angle threshold is 15°) and time interval (time threshold is 3s). Different from the conventional method that calculates mean value as the stay point’s coordinate directly, we divide the points in sub-trajectory into different groups based on semantic information. Afterwards, on the basis of the number of points in each group, we acquire weighted coordinate of the stay point. Finally, we match the stay points with POIs, which have ample information, like opening hours, special offers, etc., and then get a set of matched POIs around the stay point. In addition, through analyzing the interest and job of user, it could retrieve the more appropriate service and send it to user accordingly.
Key words: semantic trajectory; stay point; LBS; POI
QI Lingyan , CHEN Rongguo , WEN Xin . Research on the LBS Matching Based on Stay Point of the Semantic Trajectory[J]. Journal of Geo-information Science, 2014 , 16(5) : 720 -726 . DOI: 10.3724/SP.J.1047.2014.00720
Fig.1 Flow Chart of Trajectory Analysis图1 轨迹分析流程图 |
Tab.1 Semantic trajectory表1 语义轨迹表 |
| 字段名 | 数据类型 | 意义 |
|---|---|---|
| id | int | 编号 |
| latitude | int | 纬度 |
| longitude | int | 经度 |
| time | date | 时间 |
| owner | int | 用户 |
| speed | float | 速度 |
| landmark | varchar(200) | 地标 |
| …… | …… | …… |
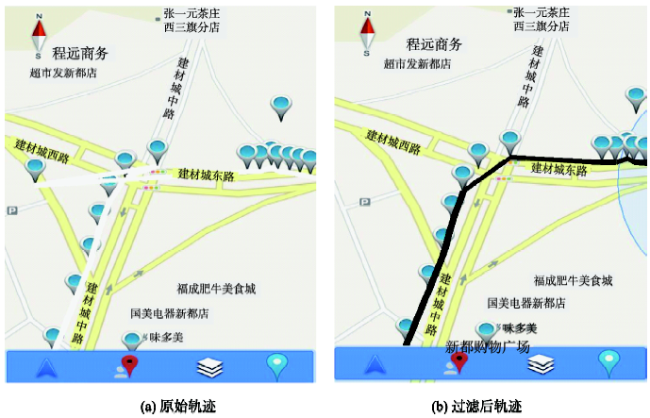
Fig. 2 Raw trajectory and trajectory after filtering the “jitter”图2 过滤“跳点”前后轨迹对比 |
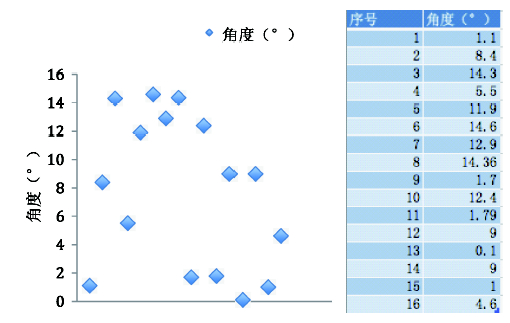
Fig.3 Angles of jitters (partial)图3 部分跳点角度 |
| Algorithm NewStayPointDetection(sema_Traj, θt, θd) | |
|---|---|
| Input: 原始语义轨迹sema_Traj,时间阈值θt,距离阈值θd | |
| Output: 停留点集合S | |
| 1. | i=0, pointNum=|sema_Traj|; |
| 2. | while i < pointNum do |
| 3. | for j←i+1 to pointNum do |
| 4. | begin |
| 5. | dist:= calDistance(Pi, Pj)); |
| 6. | if dist < θd then |
| 7. | time=Pj.t-Pi.t |
| 8. | If time>θt then |
| 9. | for m←i to j+1 do |
| 10. | stayTaj.add(Pm) |
| 11. | s.lat = NewComputeLat(stayTaj); |
| 12. | s.lngt = NewComputeLngt(stayTaj); |
| 13. | S.add(s); |
| 14. | i: = j; |
| 15. | end |
| 16. | i := i + 1; |
| 17. | return S |
| Algorithm NewComputeLat (stayTaj) |
|---|
| Input: 停留轨迹stayTaj Output: 停留点纬度lat 1. i=0, pointNum=|group_Traj|, result//按语义分组的轨迹集合 2. for i←0 to pointNum-1 do 3. if (!isContain(result,Pi.sema)) 4. for j:=0 to pointNum do 5. if ( Pi.sema.equals(Pj.sema) 6. group.add(Pj) 7. result.add(group); 8. for r←0 to pointNum do 9. sum += result.Traj(r).size()*result.Traj(r).size();//计算平方和 10. w= pointNum /sum;//计算单位权重值 11. latSum=0; 12. for r←0 to resultNum do 13. for t←0 to result.Traj(r).size() do 14. groupSum+=result.Traj(r).Pt.latitude);//计算分组后纬度和 15. latSum +=groupSum*a* result.Traj(r).size();//计算分组后纬 度和乘上权重 16. lat= latSum/tempList.size(); 17. return lat |
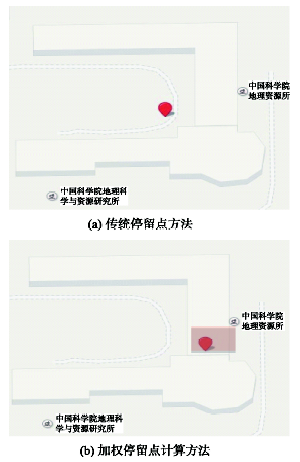
Fig.4 Contrast of stay points by two different methods图4 某个停留点计算结果对比图 |
Tab.2 Coordinates of stay points表2 停留点计算结果统计表 |
| 序号 | 语义轨迹方法计算停留点结果 | 传统方法计算停留点结果 | |||
|---|---|---|---|---|---|
| 经度 | 纬度 | 经度 | 纬度 | ||
| 1 | 116.392198 | 40.009142 | 116.391907 | 40.009172 | |
| 2 | 116.390877 | 40.008942 | 116.390834 | 40.008923 | |
| 3 | 116.374965 | 40.066685 | 116.372644 | 40.065261 | |
| 4 | 116.390364 | 40.008784 | 116.390368 | 40.008784 | |
| 5 | 116.389654 | 40.008596 | 116.389824 | 40.008608 | |
| 6 | 116.388505 | 40.008383 | 116.388320 | 40.008339 | |
| 7 | 116.387017 | 40.008089 | 116.386879 | 40.008066 | |
| … | …… | …… | …… | …… | |
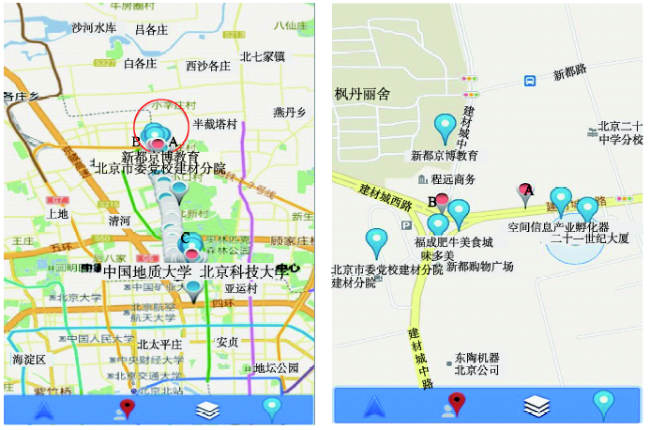
Fig.5 POI around the stay point图5 轨迹停留点周围POI点(右图为红色圆圈处放大图) |
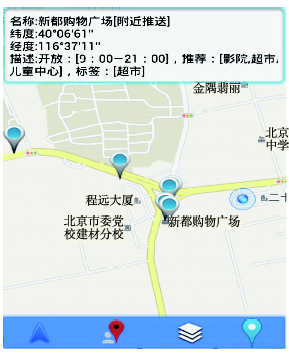
Fig.6 Details of POI图6 匹配POI详细信息 |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}