
Journal of Geo-information Science >
An Algorithm for Hilbert Ordering Code Based on State-Transition Matrix
Received date: 2014-03-14
Request revised date: 2014-05-05
Online published: 2014-11-01
Copyright
Spatial ordering based on space- filling curves is a linear mapping method from multi- dimensional space to one-dimensional space, which has been widely used in spatial querying, spatial indexing, space partition, image coding, and other related fields. The Hilbert curve is an excellent space-filling curve with remarkable spatial clustering properties. The traditional algorithm for Hilbert ordering code is based on binary circular bit manipulation, which has a complexity of O(n2). In this article, the Hilbert state- transition matrix is generated based on the fractal self- similarity, the spatial quadrants are redefined by the sequence of spatial partition, and the Hilbert state-transition matrix is translated into arrays in C++, all of which effectively reduce the nested loops and the iterations in the process of computing Hilbert code, thus decrease the complexity of algorithm to O(n). Also, the bit field union type is used to avoid the type conversion from number to string in the process of Hilbert code computation, which brings numerical calculation into full play and improves the performance of the Hilbert coding algorithm. Finally, the C++ code for Hilbert code generating algorithm is given, and various tests have been conducted to verify the correctness of the algorithm and to compare the performance with regard to the binary circular bit algorithm as well as the hierarchical space decomposition algorithm. Test results show that the algorithm demonstrates notable merits compared with the other two algorithms.
LI Shaojun , ZHONG Ershun , WANG Shaohua , ZHANG Xun . An Algorithm for Hilbert Ordering Code Based on State-Transition Matrix[J]. Journal of Geo-information Science, 2014 , 16(6) : 846 -851 . DOI: 10.3724/SP.J.1047.2014.00846
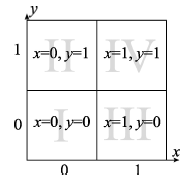
Fig. 2 Quadrant of QHC partition图2 QHC中的象限划分 |
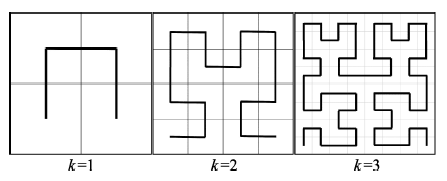
Fig. 1 Hilbert space-filling curve (k=1,2,3)图1 Hilbert空间填充曲线(k=1,2,3) |
Tab. 1 Definition of Bit-Field structure and macros表1 位域共用体及宏定义 |
| 名称 | 伪代码 |
|---|---|
| 位域共同体宏定义 | union unGridPos { unsigned short s; struct { unsigned a1:1; unsigned a2:1; … unsigned a16:1; } a; }; //定义取位运算的宏 #define GetBit(x,y) switch(x){\ case 1: y=X.a.a##1;break; \ case 2: y=X.a.a##2;break; \ … case 16: y=X.a.a##16;break; \ } |
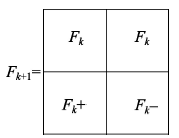
Fig. 3 Self-similarity characteristics of Hilbert图3 Hilbert曲线的自相似特征 |
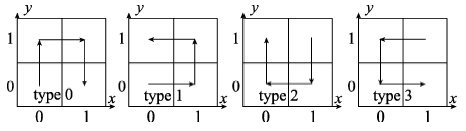
Fig. 4 Four state vector types in Hilbert curve图4 Hilbert曲线中4种状态向量 |
Tab. 2 Pseudo-code of QHC algorithm表2 QuickHilbertCode算法伪码 |
| 算法 | 伪代码 |
|---|---|
| QHC | Input: GridX, GridY:格元所在的列号和行号 k:填充空间的层级 Initial: arKey[4][2][2] = {0,1,3,2,0,3,1,2,2,3,1,0,2,1,3,0}:key向 量矩阵 arType[4][2][2] = {1,0,3,0,0,2,1,1,2,1,2,3,3,3,0,2}:type 向量矩阵 Output: resKey:格元的Hilbert码 nType=0; bitX=0; bitY=0; resKey=0; for level in k..1 do bitX=GetBit(GridX, level); bitY=GetBit(GridY, level); resKey = (resKey<<2)|arKey[nType][bitX][bitY]; nType = arType[nType][bitX][bitY]; end for return resKey; |
Tab. 3 Comparison of performance between spatial hierarchical decomposition and FR (s)表3 Hilbert空间排列码算法效率比较(s) |
| 格网数 | 512×512 | 768×768 | 1024×1024 | 2048×2048 |
|---|---|---|---|---|
| 位操作 | 3 | 7 | 12 | 53 |
| 层次分解 | 1 | 4 | 7 | 31 |
Tab. 4 Pseudo-code of verification algorithm表4 验证算法伪码 |
| 名称 | 伪代码 |
|---|---|
| 验证算法 | Input: k: 填充空间的层级 nTimes: 重复计算的次数,重复计算后取平均值以提高实验结果精确度 Initial: dQHCTime = 0.0: QHC算法耗费的时间 dFRTime = 0.0: 二进制位运算算法耗费的时间 Output: for level in 1..k do for t in 1..nTimes do dQHCTime+=QHC(level); 以QHC算法计算第level层所有格元耗费的时间 dFRTime+=FR(level); 以二进制位运算算法计算第level层所有格元耗费的时间 end for end for returndQHCTime, dFRTime; |
Tab. 5 Result of performance test (s)表5 性能对比实验结果 |
| 层级 | 格元数 | QHC算法 | FR算法 | 性能提升 |
|---|---|---|---|---|
| 7 | 128×128 | 0.000010 | 0.016548 | 1591 |
| 8 | 256×256 | 0.000038 | 0.068585 | 1792 |
| 9 | 512×512 | 0.000152 | 0.285086 | 1842 |
| 10 | 1024×1024 | 0.000604 | 1.189585 | 1971 |
| 11 | 2048×2048 | 0.002365 | 4.976408 | 2104 |
| 12 | 4096×4096 | 0.009638 | 21.498139 | 2231 |
| 13 | 8192×8192 | 0.038625 | 89.662764 | 2321 |
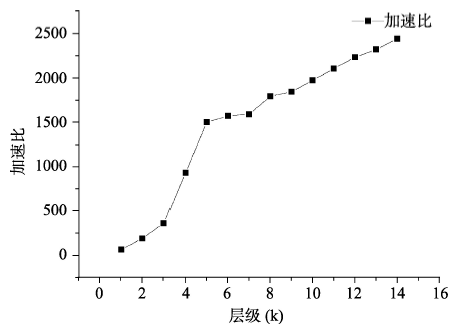
| 14 | 16384×16384 | 0.151542 | 369.571435 | 2439 |
Fig. 5 Speed-up ratio of QHC图5 算法性能提升 |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}