
Journal of Geo-information Science >
Extracting Geographic Information from Web Texts: Status and Development
Received date: 2014-08-28
Request revised date: 2014-10-29
Online published: 2015-02-10
Copyright
Internet generates a plenty of texts which contain abundant geographic semantic information, and bring massive opportunities for deep mining and knowledge discovery. Meanwhile, heterogeneous and dynamic web texts make a surge in the number and type of geographic entity's attributes and the complexity of geographic semantic relations, which present a unprecedented challenge to geographic information retrieval, spatial analysis and reasoning, and intelligent location based services. Firstly, we describe the process of extracting geopgraphic informantion from web texts, summarize the research status and major issues which include geographic entity recognition, locating, attribute extraction, relation construction and event extraction. Secondly, we introduce some popular open sources used for geographic information extraction. Lastly, we discuss and look ahead to the development trends of this domain in future.
YU Li , LU Feng , ZHANG Hengcai . Extracting Geographic Information from Web Texts: Status and Development[J]. Journal of Geo-information Science, 2015 , 17(2) : 127 -134 . DOI: 10.3724/SP.J.1047.2015.00127
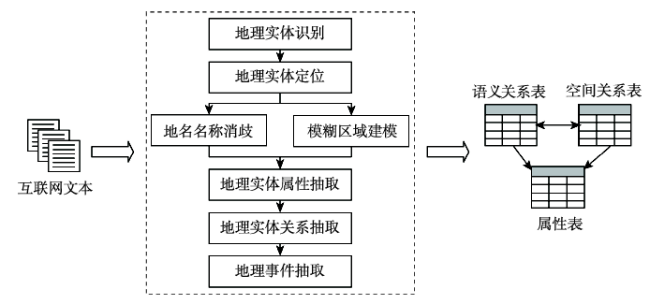
Fig. 1 Framework of geographic information extraction from web texts图1 网络文本蕴涵地理信息抽取流程 |
Tab. 1 Open source NLP tools for Chinese表1 支持中文的开源NLP工具 |
| 名称 | 下载网址 | 功能 | 开发者 | 开发语言 |
|---|---|---|---|---|
| UIMA | http://uima.apache.org/ | NLP工具集 | Apache软件基金会 | Java、C++ |
| OpenNLP | http://opennlp.apache.org/ | Apache软件基金会 | Java | |
| LingPipe | http://alias-i.com/lingpipe/index.html | Alias公司 | Java | |
| NLTK | http://nltk.org/ | 团队 | Python | |
| GATE | http://gate.ac.uk/ | 伊利诺斯大学 | Java | |
| Mallet | http://mallet.cs.umass.edu/ | 马萨诸塞大学 | Java | |
| StanfordNLP | http://nlp.stanford.edu/ | 斯坦福大学 | Java | |
| GATE | http://gate.ac.uk/ | 语料标注工具 | 伊利诺斯大学 | Java |
| Unitex | http://www-igm.univ-mlv.fr/~unitex/index.php?page=0 | 马恩-拉瓦莱大学 | Java、C++ | |
| Ellogon | http://www.ellogon.org/ | Georgios Petasis | C++、Java、Python | |
| LTP | http://www.ltp-cloud.com/ | 中文的NLP工具集 | 哈尔滨工业大学 | C#、C++、Java、Ruby、Python |
| FundanNLP | http://jkx.fudan.edu.cn/nlp/ | 复旦大学 | Java | |
| NLPIR | http://ictclas.nlpir.org/ | 张华平 | C、C++、C#、Java |
Tab. 2 Open gazetteers表2 开放的地名词典 |
| 类型 | 名称 | 下载网址 | 规模 | 内容 |
|---|---|---|---|---|
| 地名数据库 | DIVA-GIS Gazetteer | http://www.diva-gis.org/gdata | 超过58亿个地名 | 名称、坐标、地名的层级关系 |
| OpenStreetMap | http://www.openstreetmap.org | 超过20亿个点,2亿个线或面 | 18大类,地理实体的属性和空间信息 | |
| GeoNames | http://www.geonames.org/ | 超过1千万个地点 | 9大类,多语言的地名、坐标、海拔、人口、行政区划、邮编 | |
| Flickr | http://www.flickr.com/ | 超过140万个地理标签 | 带有空间位置信息的影像视频数据库 | |
| 同义词典 | TGN | http://www.getty.edu/research/tools/vocabularies/tgn/index.html | 超过90万个地点 | 行政区划和自然地理实体的历史名称、人口、文化、建筑等 |
| WordNet | http://wordnet.princeton.edu/ | 超过14万个名词 | 英文同义词集 | |
| E-HowNet | http://ehownet.iis.sinica.edu.tw/ | 可在线查询8万个词汇 | 添加繁体知识中英文同义词集 | |
| 同义词词林 | http://www.datatang.com/data/42306 | 超过7万个词汇 | 中文同义词集,12大类 | |
| 专题词典 | OWTRAD | http://www.ciolek.com/OWTRAD/caravanserais-catalogue-00.html | 1051个地名 | 欧亚非大陆旧贸易路线的客店和驿站的名称、坐标、编码等 |
| CH-GIS | http://www.fas.harvard.edu/~chgis/ | 2513个县名 | 地点的坐标、层级关系、历史名称、繁体书写、名称来历等 |
Tab. 3 Segmentation corpora表3 分词语料库 |
| 用途 | 名称 | 下载网址 | 规模 | 语料来源 | 单位 |
|---|---|---|---|---|---|
| 分词和词性标注 | Brown | http://www.hit.uib.no/icame/brown/ | 超过100万词语 | 美式英语书面语 | 布朗大学 |
| LOB | http://www.hit.uib.no/icame/lobman/lob-cont.html | 超过100万词语 | 英式英语书面语、Brown语料 | 兰卡斯特大学、奥斯陆大学、挪威计算中心 | |
| BNC | http://www.natcorp.ox.ac.uk/ | 超过1亿词语 | 英式英语的书面语和口语 | 英国牛津出版社等 | |
| 现代汉语语料库 | http://202.114.40.175:8080/cqs/ | 在线检索的语料约2千万字 | 教材、报纸、刊物、图书等 | 国家语言文字工作委员会 | |
| 现代汉语平衡语料库 | http://db1x.sinica.edu.tw/cgi-bin/kiwi/mkiwi/kiwi.sh | 在线检索限制2000句内 | 报纸、杂志、BBS、番薯藤网 | 中国台湾中央研究院 | |
| 人民日报切分标注语料库 | http://162.105.203.93/icl_groups/corpustagging.asp | 已发布语料约200万字 | 1998年人民日报 | 北京大学计算语言学研究所 | |
| 中文互联网5-gram语料库 | http://www.chineseldc.org/doc/CLDC-LAC-2008-001/label.htm | 超过8千亿词语 | 公开访问的网页 | Google研究院 |
Tab.4 Disambiguation corpora表4 消歧语料库 |
| 用途 | 名称 | 下载网址 | 规模 | 语料来源 | 单位 |
|---|---|---|---|---|---|
| 词义消歧 | SemCor | http://moin.delph-in.net/SemCor | 超过20万词次 | WordNet1.6、Brown语料库 | 普林斯顿大学 |
| DSO | https://catalog.ldc.upenn.edu/LDC97T12 | 191个名词和动词,约19万词次 | WordNet1.5、Brown语料库、华尔街时报 | 新加坡国立大学 | |
| SENSEVAL-3[60] | 57个实词,约1.2万词次 | WordNet1.7、WordSmyth、BNC | 苏塞克斯大学 | ||
| STC | http://www.icl.pku.edu.cn/member/wuyf/LanRes.html | 约4.6万个动词、2万个名词 | 现代汉语语义词典、人民日报标注语料库 | 北京大学 |
Tab. 5 Treebank表5 树库 |
| 用途 | 名称 | 下载网址 | 规模 | 语料来源 | 单位 |
|---|---|---|---|---|---|
| 句法分析 | Penn English Treebank | http://www.cis.upenn.edu/~treebank/ | 约2500个文档 | 华尔街日报、网页新闻、Brown语料库 | 宾夕法尼亚大学 |
| Lancaster-Leeds | http://clwww.esses.ac.uk/w3c/corpus_ling/content/corpora/list/private/LOB/lob.html | 约4.5万词语 | LOB语料库 | 兰卡斯特大学 | |
| Penn Chinese Treebank | http://www.cis.upenn.edu/~chinese/ctb.html | 超过160万个词语 | 网页新闻、政府文档、杂志、广播、博客 | 宾夕法尼亚大学 | |
| 汉语依存树库 | http://ir.hit.edu.cn/demo/ltp/Sharing_Plan.htm | 1万句 | Penn Chinese Treebank | 哈尔滨工业大学 | |
| 中文句结构树库 | http://rocling.iis.sinica.edu.tw/CKIP/treebank.htm | 超过6万句,可下载1000句 | 报纸、杂志、BBS、番薯藤网站 | 中国台湾中央研究院 | |
| Tsinghua Chinese Treebank | http://cslt.riit.tsinghua.edu.cn/~qzhou/eng/Resources.htm | 超过100万个词语 | 文学、学术、新闻、应用的平衡语料文本 | 清华大学 |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
|
| [51] |
|
| [52] |
|
| [53] |
|
| [54] |
|
| [55] |
|
| [56] |
|
| [57] |
|
| [58] |
|
| [59] |
|
| [60] |
|
| [61] |
|
| [62] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}