
Journal of Geo-information Science >
A Topic Crawler for Discovering Geospatial Web Services
Received date: 2014-11-14
Request revised date: 2014-12-21
Online published: 2015-02-10
Copyright
In Internet era, geospatial web services (GWSs) are the primary approaches to share and interoperate geographical data. After more than ten years of development and the widely adoption on specifications, an increased number of geospatial web services have been published and are available for online public access. To obtain those geographical data, it is necessary to find an effective approach to locate and discover GWSs among massive web resources. Currently, the most widely used methods in practical for GWSs discovering are either based on Google Search API or based on generic web crawler. But the aforementioned approaches have some shortages, such as relatively inefficient search performance, irrelevant results, and low precision on GWS identification. To partially address the above issues, this paper developed a topic crawler to harvest GWSs based on the modified Best First Search strategy. The core of the proposed algorithm is that through combining the topic relevance of the link text and the topic relevance of the webpage text synthetically to predict the crawling priority of the unvisited URL. Then, we can utilize the priority thresholds to filter out the irrelevant URLs and narrow the search range at the same time. Moreover, a capabilities document detecting operation is added to GWSs recognition process to improve the search precision. Finally, we use the most widely adopted GWS specification: Web Map Service (WMS), which is proposed by Open Geospatial Consortium (OGC), as a case study. Two groups of experiments were conducted to compare the proposed method and a generic web crawler. The experimental results verified the feasibility of the proposed algorithm.
SHEN Ping , GUI Zhipeng , YOU Lan , HU Kai , WU Huayi . A Topic Crawler for Discovering Geospatial Web Services[J]. Journal of Geo-information Science, 2015 , 17(2) : 185 -190 . DOI: 10.3724/SP.J.1047.2015.00185
Fig. 1 Workflow of the proposed crawler algorithm图1 本文爬虫算法的工作流程图 |
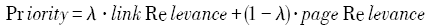
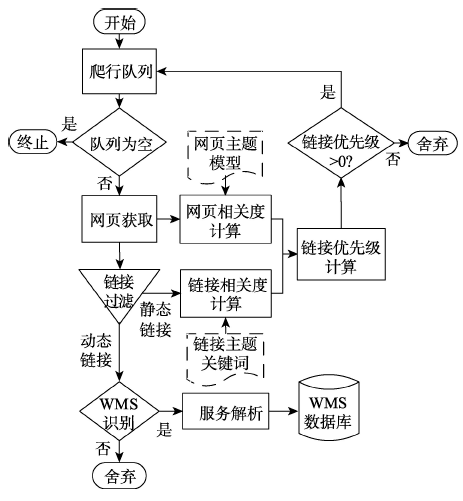
Tab. 1 The experimental results of the generic web crawler and the proposed crawler表1 两种爬虫的搜索WMS的结果对比 |
| 种子点 | 算法 | 已下载的网页总数 | WMS数量 | 精确率(%) |
|---|---|---|---|---|
| 种子点1 | 通用爬虫 | 1 820 | 888 | 48.68 |
| 本文爬虫 | 1 373 | 886 | 64.53 | |
| 种子点2 | 通用爬虫 | 18 955 | 153 | 0.81 |
| 本文爬虫 | 2 201 | 153 | 6.95 |
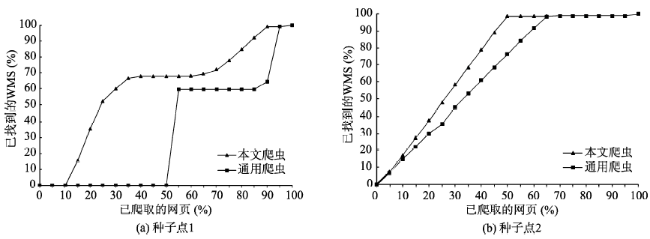
Fig. 2 Performance comparison between the proposed crawler and the generic web crawler using entry1 and entry2图2 本文爬虫和通用爬虫的性能对比(种子点1和种子点2) |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}