
Journal of Geo-information Science >
Self-organizing Dual Spatial Clustering Algorithm and Its Application in the Analysis of Urban Sprawl Structure
Received date: 2014-11-18
Request revised date: 2015-01-31
Online published: 2015-06-10
Copyright
Dual spatial clustering is an exploratory data analysis that deals with spatial contiguity and attributive similarity. Conventional spatial clustering methods cannot perform effective clustering in spatial and attribute domains simultaneously. This study employs SOFM (Self-Organizing Feature Mapping) to solve dual spatial clustering problems, and then verify the proposed method in the analysis of urban expansion structure. By modifying the algorithm of best matching neuron searching in SOFM, we manage to perform clustering in both spatial and attribute domains. The algorithm includes two independent self-organizing clustering processes. The first one includes a spatial constraint, and the other one includes an attribute constraint. The final result is generated by merging the corresponding two results that derived separately from the two processes. The analysis of the structure of urban expansion of Wuhan city is used as a case study. We feed the proposed model with the location information and the expansion degree information of newly grown urban patches, and the generated dual clustering results could clearly illustrate the spatial structure of urban expansion. As a conclusion, the self-organizing dual spatial clustering method can generate spatial continuous and attributive similar clusters with little artificial interference.
JIAO Limin , ZHANG Xin , MAO Lifan . Self-organizing Dual Spatial Clustering Algorithm and Its Application in the Analysis of Urban Sprawl Structure[J]. Journal of Geo-information Science, 2015 , 17(6) : 638 -643 . DOI: 10.3724/SP.J.1047.2015.00638
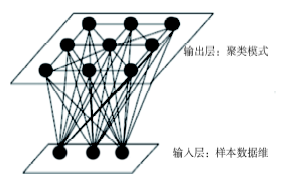
Fig. 1 The structure of SOFM neutral network图1 自组织特征映射神经网络的结构 |
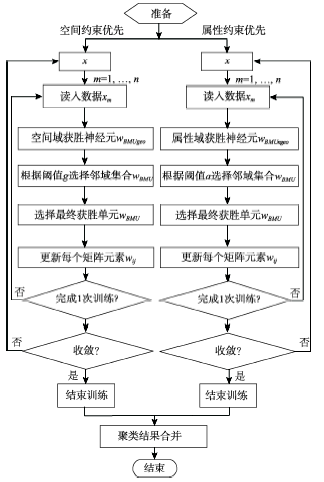
Fig. 2 The flowchart of dual spatial clustering algorithm图2 自组织双重空间聚类算法流程图 |
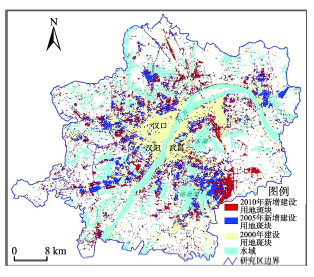
Fig. 3 The study area and the distribution of urban patches图3 研究区域及建设用地斑块分布图 |
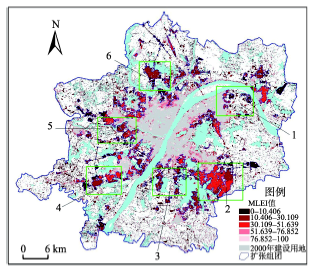
Fig. 4 Extracting urban expansion structure with self-organizing dual spatial clustering algorithm图4 自组织双重空间聚类提取城市扩张组团结构 |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}