
Journal of Geo-information Science >
Application of Density-Based Clustering Algorithm in Crime Cases Analysis Considering Multiple Time Scale
Received date: 2014-12-09
Request revised date: 2015-03-16
Online published: 2015-07-08
Copyright
Space-time clustering, which is one of the main research focuses in the field of data mining, has important application values in the field of environment protection, disease prevention and control, and crime prevention and combat. The time "distance" is considered to be a substantial interval within the existing space-time clustering methods. However, crime cases with social attributes have obvious cyclical characteristics in different time-scales. It would be difficult to find the real rules of time and space for crime cases if these characteristics are ignored. Therefore, based on DBSCAN, an algorithm considering multiple time-scales and equivalent spatio-temporal neighborhood (MTS-ESTN DBSCAN) was put forward. In this algorithm, the various time attributes in multiple time-scales were considered, the equivalent spatio-temporal neighborhood was built, and the concept of the classical density clustering algorithm was cited. In the equivalent spatio-temporal neighborhood, the Euclidean distance (L2-norm) is adopted as the measurement of spatial neighborhood for the space domain. With the improved function of HDsim, which is a method used to measure the unified similarity of high dimensional data, we defined the similarity of time domain. Based on the crime cases data in the urban area of Fuzhou city during 2013, cluster analysis was conducted, and the resultant clustering quality was evaluated using several indicators such as CH (Calinski-Harabasz), Sil (Silhouette), DB (Davies-Bouldin) and KL (Krzanowski-Lai). The results showed the feasibility of the method in space-time cluster analysis of crime cases. Compared with the traditional algorithm of ST-DBSCAN, this algorithm has produced better quality of clustering. In addition, this algorithm can find the accumulation characteristics behind the rules of human´s work, rest and other social activities in a long period. It has certain significances and application values for the advanced study of criminal geography in urban area.
WU Wenhao , WU Sheng . Application of Density-Based Clustering Algorithm in Crime Cases Analysis Considering Multiple Time Scale[J]. Journal of Geo-information Science, 2015 , 17(7) : 837 -845 . DOI: 10.3724/SP.J.1047.2015.00837
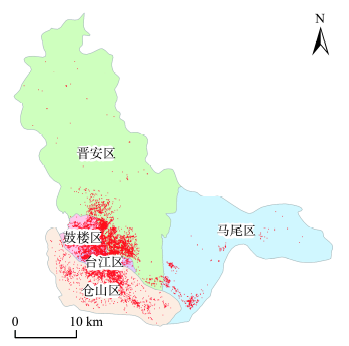
Fig. 1 Spacial distribution of crime cases in Fuzhou图1 福州市区案事件点的空间分布 |
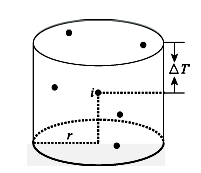
Fig. 2 Spatio-temporal scanning window图2 时空扫描窗口 |
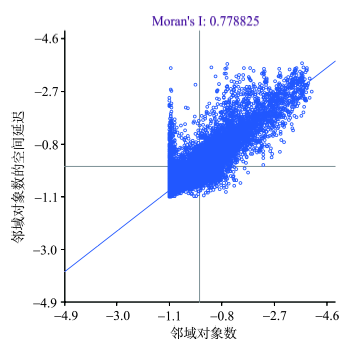
Fig. 3 Moran scatter plot图3 Moran散点图 |
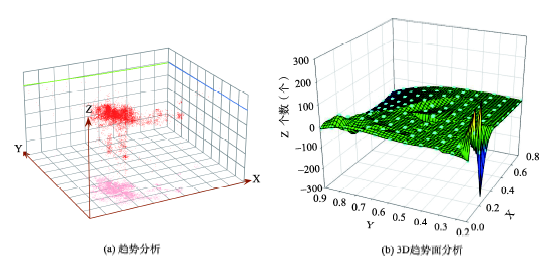
Fig. 4 Spatio-temporal trend graphs of sample data图4 样本数据时空趋势图 |
Tab. 1 The codes of all time periods表1 时段编码对照表 |
| 时间段 | 时辰编码 | 时间段 | 时辰编码 |
|---|---|---|---|
| [23:00, 01:00) | 0 | [11:00, 13:00) | 6 |
| [01:00, 03:00) | 1 | [13:00, 15:00) | 7 |
| [03:00, 05:00) | 2 | [15:00, 17:00) | 8 |
| [05:00, 07:00) | 3 | [17:00, 19:00) | 9 |
| [07:00, 09:00) | 4 | [19:00, 21:00) | 10 |
| [09:00, 11:00) | 5 | [21:00, 23:00) | 11 |
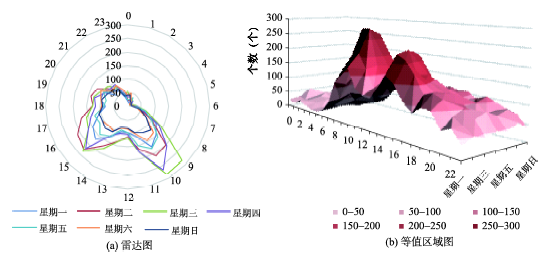
Fig. 5 Statistical graphs of crime cases based on different weekdays and time periods图5 案事件分星期、时段统计图 |
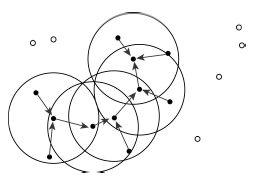
Fig. 6 Spatio-temporal density-connected data points (plane projection)图6 时空密度连接(平面空间投影) |
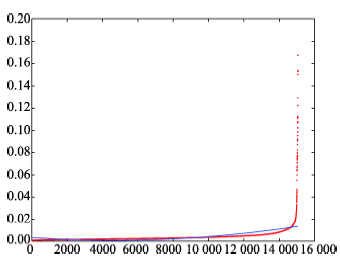
Fig. 7 Spatial k-dist plot图7 空间k-dist图 |
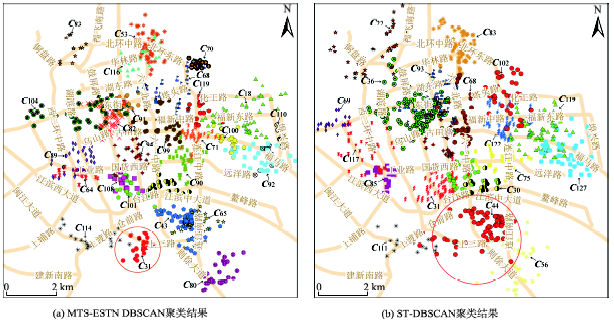
Fig. 8 Space-time clustering result (part of the clusters are shown in figures)图8 时空聚类结果(部分时空簇) |
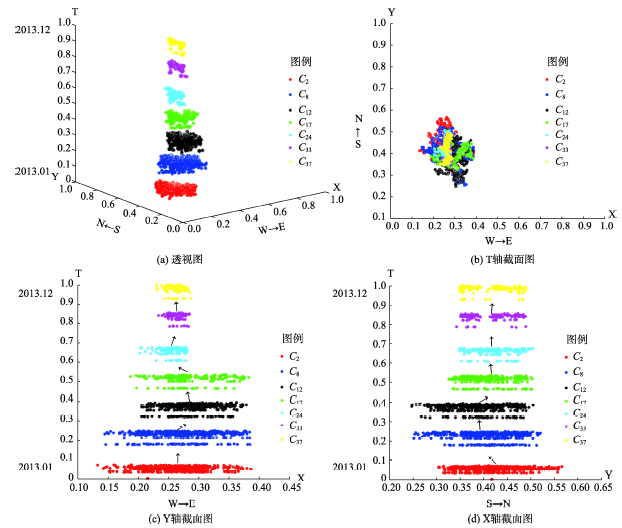
Fig. 9 Spatio-temporal offset features of multiple clusters图9 多个簇的时空偏移特征 |
Tab. 2 Assessment of the clustering results表2 聚类结果有效性评价 |
| 评价指标 | CH | Sil | DB | KL |
|---|---|---|---|---|
| MTS-ESTN DBSCAN | 1.0759 | -0.0008 | 0.0087 | 3.2584 |
| ST-DBSCAN | 0.2957 | -0.0008 | 0.0107 | 1.1279 |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}