
Journal of Geo-information Science >
The Gridding Approach to Redistribute Population Based on Multi-source Data
Received date: 2014-07-22
Request revised date: 2014-10-17
Online published: 2015-06-10
Copyright
Gridded population distribution data are increasingly expanding their uses in a wide range of fields, such as resource utilization, disaster response and relief, environment protection, and economic research. The enhancement of resolution with detailed precision is a perpetual topic in population gridding research. In this paper, a 100m gridded population dataset was established for Yan’an city by developing a method that distributed the population based on the land use data with improved settlement information. Data used here include township boundary data, township-level demographic data, land use data, TM image, town-village settlement point data, and DMSP/OLS nighttime light images. Two approaches were used to improve the detailed information of settlement distribution. First, we identify the rural settlement information from land use data and enhance the information by the village point data obtained from Google Earth. Second, we downscale the DMSP/OLS data by spatial interpolation. The sum of light emission, lit area and unlit area under different land use types in each town were counted to be used as the independent variables, and the statistical population of each town were used as the dependent variable. A stepwise regression method was adopted to simulate their relationship. Finally, the sum of night light emission, the unlit area of build-up area, the unlit area of grassland, and the lit area of farmland were put into constructing the ultimate equation. All variables were significant under the level of 0.01 and the coefficient of multiple correlation is 0.872. We estimated the population at township level for selected towns as a validation. Through using the equation, we found that the mean error between the estimation and the statistical population is lower than 5%. The above analysis suggests that the proposed modeling strategy is highly efficient. As a result, we calculate the weight and distribute the population through the equation in the formation of 100m grid, by taking township as the unit. In summary, the gridding method used in this study can obviously improve the output resolution and the distribution details. Also, the expression of the final equation is relative simple. As a conclusion, this paper has its significance in guiding the population gridding research in the county level areas like Yan’an city.
BAI Zhongqiang , WANG Juanle , JIANG Hao . The Gridding Approach to Redistribute Population Based on Multi-source Data[J]. Journal of Geo-information Science, 2015 , 17(6) : 653 -660 . DOI: 10.3724/SP.J.1047.2015.00653
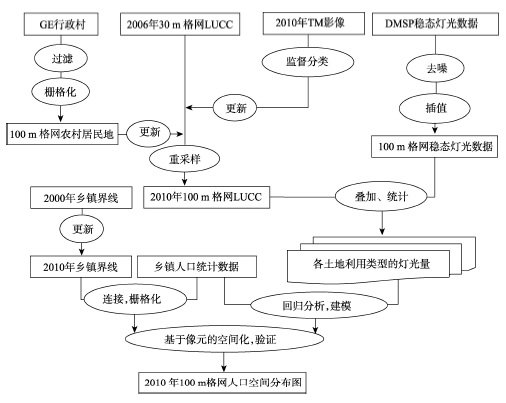
Fig. 2 Spatialization modeling strategy图2 格网化建模流程图 |
Tab. 1 Comparison of the two interpolation methods表1 插值方法对比 |
| 最小值 | 最大值 | 平均值 | 标准差 | 偏度 | 峰度 | 相关性 | |
|---|---|---|---|---|---|---|---|
| 原始数据 | 0 | 63.0 | 4.470 | 0.153 | 3.116 | 10.241 | |
| IDW | 0 | 62.5 | 4.451 | 0.146 | 3.085 | 10.072 | 0.981 |
| OK | 0 | 62.3 | 4.449 | 0.144 | 3.053 | 9.862 | 0.974 |
Tab. 2 Validation of village points from GE表2 GE行政村点验证 |
| 县名 | 抽样点数 | 非居民点数 | 平均精度 | 县名 | 抽样点数 | 非居民点数 | 平均精度 |
|---|---|---|---|---|---|---|---|
| 黄陵县 | 21 | 2 | 0.9048 | 宝塔区 | 66 | 5 | 0.9242 |
| 黄龙县 | 23 | 5 | 0.7826 | 延川县 | 28 | 3 | 0.8929 |
| 洛川县 | 36 | 1 | 0.9730 | 志丹县 | 25 | 5 | 0.8000 |
| 富 县 | 30 | 4 | 0.8824 | 安塞县 | 20 | 3 | 0.8500 |
| 宜川县 | 22 | 4 | 0.8182 | 吴旗县 | 23 | 3 | 0.8697 |
| 甘泉县 | 12 | 2 | 0.8333 | 子长县 | 51 | 7 | 0.8627 |
| 延长县 | 30 | 6 | 0.8333 |
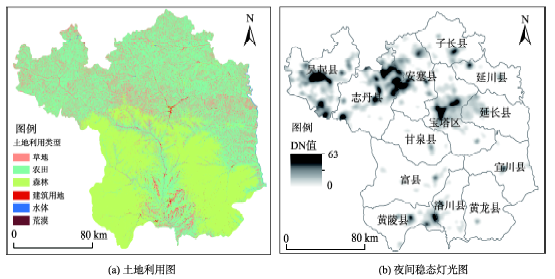
Fig. 3 Maps showing the land use and night light radiation distribution in Yan'an city in 2010图3 延安市2010年土地利用与夜间稳态灯光辐射 |
Tab. 3 The regression coefficients of the model表3 模型各回归系数 |
| 土地利用类型 | 系数 | 标准系数 | Sig. | |
|---|---|---|---|---|
| 城镇及建设用地 | e | 3.089 | 0.766 | 0.000 |
| u | 45.998 | 11.061 | 0.000 | |
| 草地 | u | 0.502 | 0.200 | 0.000 |
| 农田 | l | 1.841 | 0.174 | 0.000 |
| R2 | 0.872 |
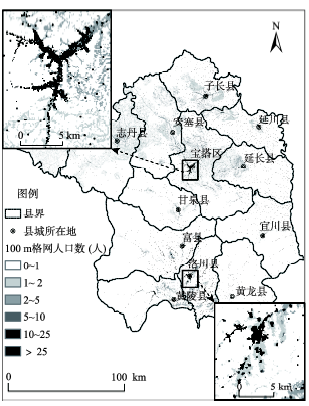
Fig. 4 The spatial distribution of population in Yan'an city in 100 m×100 m grid cell in 2010图4 延安市2010年100 m格网人口空间分布 |
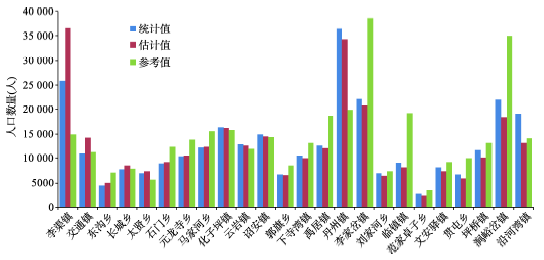
Fig. 5 A comparison of the estimated, the statistical and the reference population of selected towns图5 估计人口与统计数据及参考值对比图 |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}