
Journal of Geo-information Science >
A Research of Map-Matching Method for Massive Floating Car Data
Received date: 2015-04-15
Request revised date: 2015-05-15
Online published: 2015-10-10
Copyright
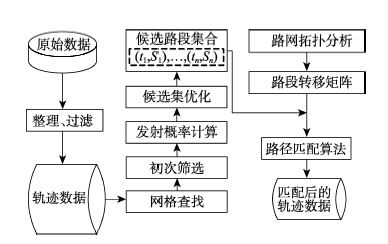
Floating Car Data (FCD) has been widely applied into traffic supervision, smart travelling, urban planning and so forth. Map-matching is one of the key technologies of FCD, for current map-matching algorithms, it is difficult to improve their map-matching efficiency considerably with a guaranteed accuracy. To solve this problem, our research proposes a map-matching model based on Hidden Markov Model (HMM), and makes a variety of improvements compared with the traditional model: (1) in addition to the position information, it introduces the heading angle variable to emission probability calculation, and discusses its influences on model accuracy and how to set a reasonable weight; (2) it divides road network according to a square grid, constructs candidate road segments searching algorithm based on hash index, and then discusses the optimization approach of the candidate road segment collection; (3) the numbers of segments in the path is used as the measurement for transition probability computation instead of the practical length, which simplifies the calculation procedure; (4) by preprocessing the road net, it constructs a road segment transition matrix according to the characteristic that floating cars have a limited scope of space activities in a given time, which realizes the fast calculation of road segment transition probability and reduces the time complexity of road matching calculation to a significant extent. We have applied this map-matching model in analyzing Beijing taxis’ trajectory data, in which the sampling time interval varies from 1 s to 120 s. The result demonstrates that this model is practicable, the required road segment transition matrix can be constructed in affordable space cost, and its efficiency is improved significantly with the condition that the accuracy meets the application requirements, which makes the model more applicable for massive FCD map-matching. As a conclusion, the proposed model has a high application value for multiple cases.
Key words: FCD; map matching; HMM; grid; road segment transition matrix
WANG Xiaomeng , CHI Tianhe , LIN Hui , SHAO Jing , YAO Xiaojing , YANG Lina . A Research of Map-Matching Method for Massive Floating Car Data[J]. Journal of Geo-information Science, 2015 , 17(10) : 1143 -1151 . DOI: 10.3724/SP.J.1047.2015.01143
Fig. 1 HMM-MM process图1 基于HMM的地图匹配过程 |
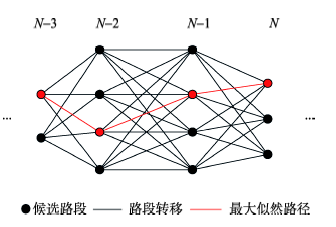
Fig. 2 Map-matching model based on HMM图2 基于HMM的地图匹配模型 |
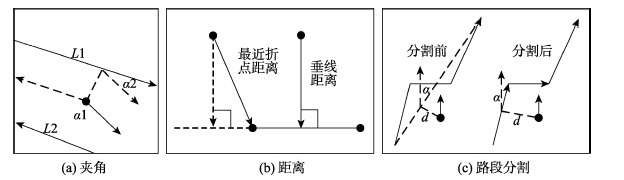
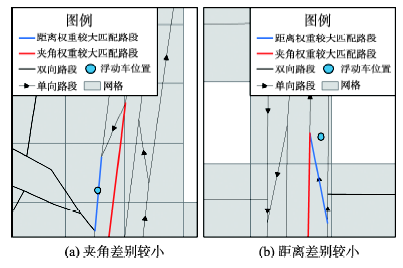
Fig. 3 Road segment selecting by included angles and distances图3 轨迹点与路段的方向夹角和距离 |
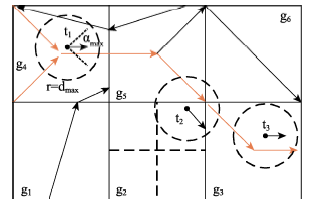
Fig. 4 Candidate road segments searching by grids图4 基于网格的邻近子路段查找 |
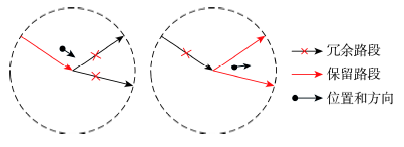
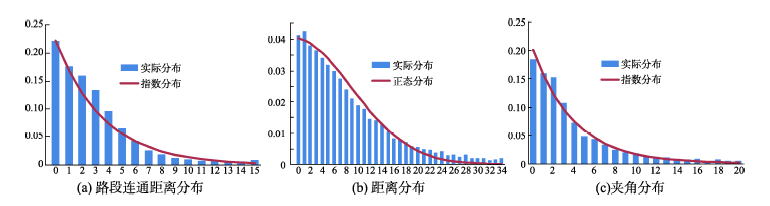
Fig. 5 Eliminate redundant segments图5 删除冗余路段 |

Tab. 1 Static data scale表1 模型静态数据规模 |
| 名称 | 键值对组织方式 | 规模(万条) | 占用空间(MB) |
|---|---|---|---|
| 路网邻接矩阵 | 12.48 | 2.7 | |
| 网格-子路段关系 | 28.84 | 5.8 | |
| 子路段-路段关系 | 58.39 | 7.9 | |
| 有限路段转移集合 | 4000 | 847 |
Fig. 6 Floating car data distributions图6 浮动车数据分布情况 |
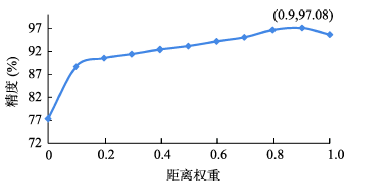
Fig. 7 Comparison of model accuracies under different weight strategies图7 不同权重策略的模型精度比较 |
Fig. 8 Comparison of matching results under different weight strategies图8 不同权重策略匹配结果对比 |
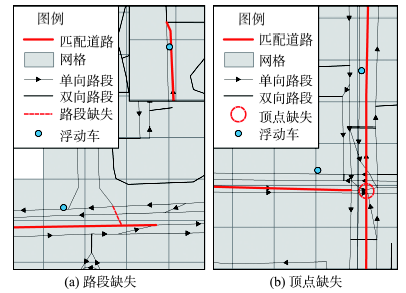
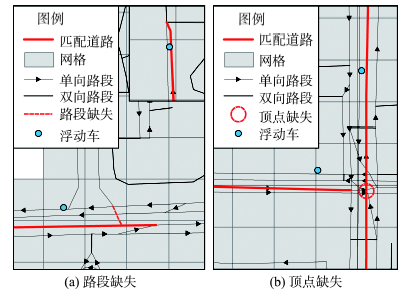
Fig. 9 Road net topology errors图9 路网拓扑错误 |
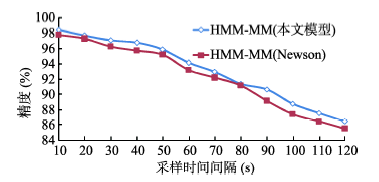
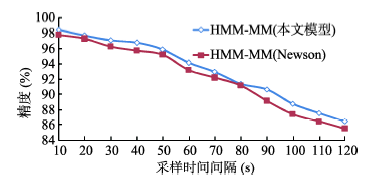
Fig. 10 Comparison of accuracies of map-matching图10 地图匹配精度对比 |
Tab. 2 Computational performance of the model without I/O cost表2 模型运行效率(除去I/O耗时) |
| 算法类型 | 路段查找(s) | 路径匹配(s) | 总耗时(s) | 平均(点/s) |
|---|---|---|---|---|
| 传统模型 | 20.73 | 43.69 | 64.42 | 817.83 |
| 本文模型 | 5.89 | 0.63 | 6.52 | 6219.11 |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}